今回は、リーフノードのサンプル数を変更してみます。
最小サンプル数変更
リーフノードの最小サンプル数を変更するためには、min_samples_leafを設定します。
min_samples_leafのデフォルト値は1となっており、ノード数が1になるまで分岐をし続けることを意味します。
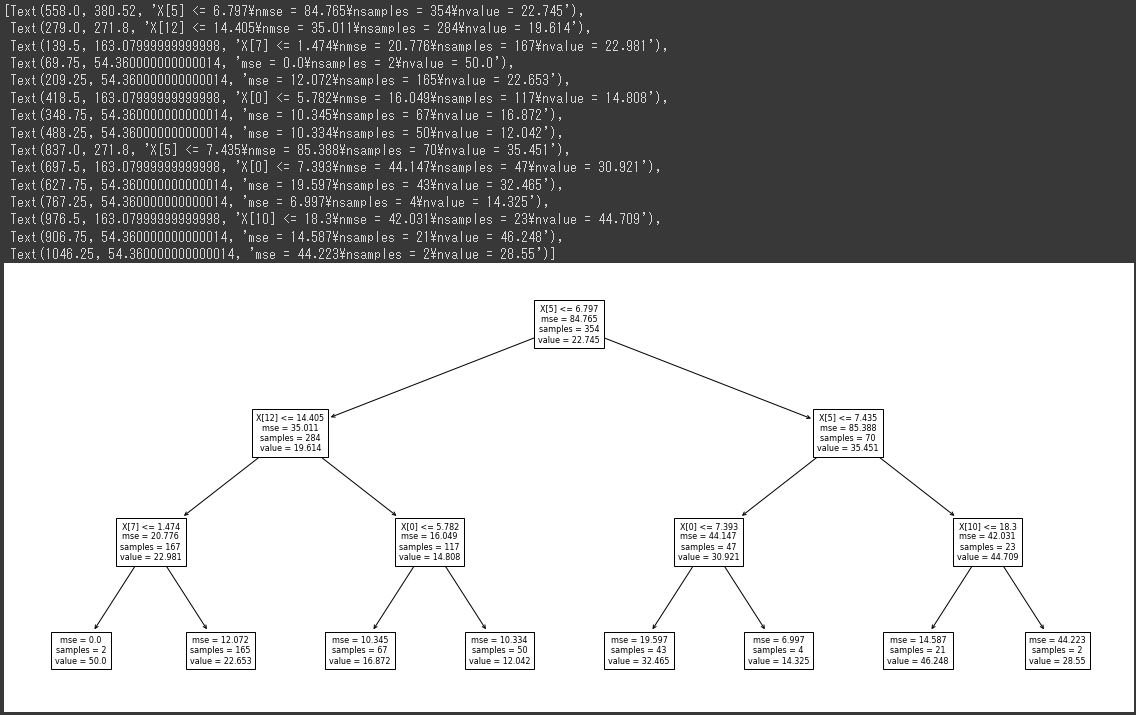
深さ(max_depth)は前回過学習に陥った20としたままで、最小サンプル数(min_samples_leaf)を1から5に変更してみます。(1行目)
[Google Colaboratory]
1 | tree_reg_samples_5 = DecisionTreeRegressor(max_depth=20, min_samples_leaf=5,random_state=0).fit(X_train,y_train) |
[実行結果]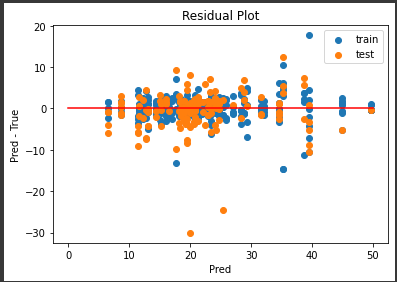
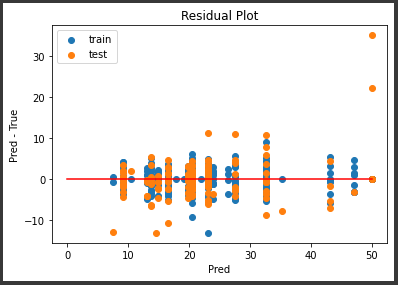
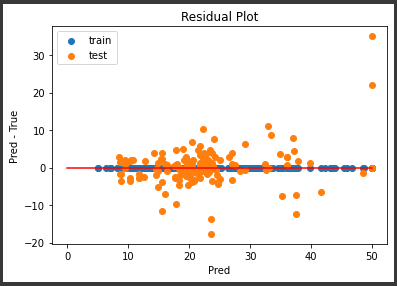
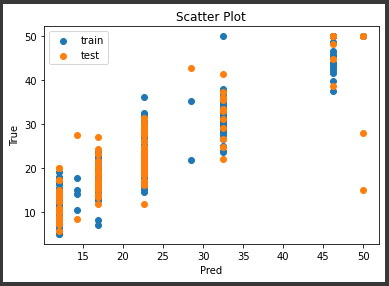
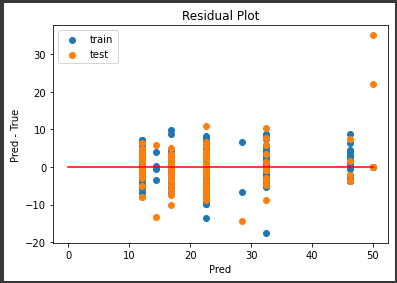
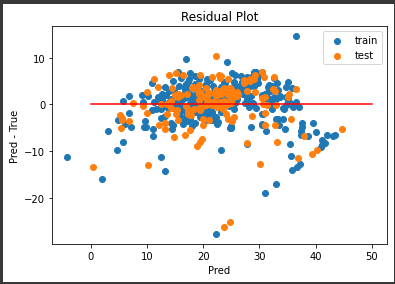
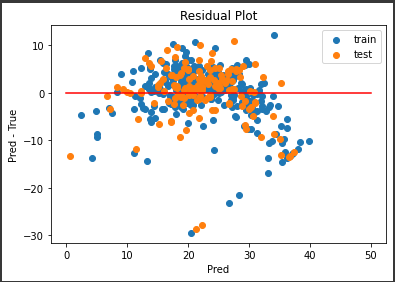
中央下にいくつか外れ値がありますが、誤差の範囲が±10程度に集まっていてなかなかの結果になっていると思います。
また訓練データの誤差も適度にばらついていて、過学習の傾向が減っているようです。
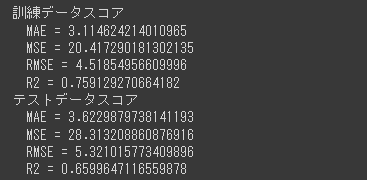
精度評価スコア (max_depth=20, min_samples_leaf=5)
精度評価スコアを算出します。
[Google Colaboratory]
1 | print("訓練データスコア") |
[実行結果]
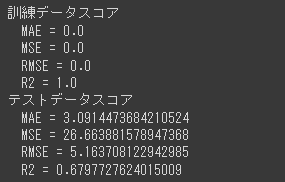
リーフノードの最小サンプル数を5に制限したことで、テストデータのR2スコアが0.71となりこれまでで最も良い結果となりました。
また、訓練データのR2スコアが1.0から0.91となり、過学習傾向が軽減されていることが分かります。
決定木は過学習に陥りやすい傾向はありますが、深さや最小サンプル数などのハイパーパラメータを調整することで過学習をある程度抑えることができ、モデルの精度改善を行うことができます。