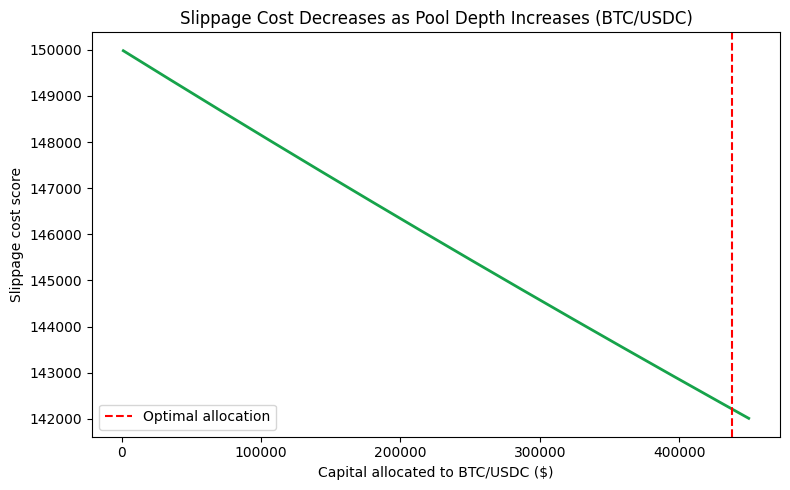
What Is the Rosenbrock Function?
The Rosenbrock function is one of the most famous test problems in numerical optimization. It’s often called the “banana function” because its contour lines form a curved, banana-shaped valley. While the function looks simple, the valley is narrow and curved, which makes it deceptively difficult for many optimization algorithms to converge on efficiently.
The standard two-dimensional form is:
$$
f(x, y) = (a - x)^2 + b(y - x^2)^2
$$
with the classic parameter choice $a = 1$, $b = 100$. The global minimum sits at $(x, y) = (1, 1)$, where $f(x,y) = 0$.
The gradient, which we’ll use for faster convergence, is:
$$
\frac{\partial f}{\partial x} = -2(a - x) - 4bx(y - x^2)
$$
$$
\frac{\partial f}{\partial y} = 2b(y - x^2)
$$
Because the valley curves and is very narrow, simple gradient descent tends to zig-zag slowly along the valley floor, taking a huge number of iterations. This makes the Rosenbrock function a great case study for comparing a “naive” optimization approach against a properly optimized one.
The Approach
In this article we’ll do three things:
- Implement a naive gradient descent solver from scratch in pure Python and time it.
- Implement a fast, vectorized solver using
scipy.optimizewith the analytic gradient supplied, and time it. - Visualize both optimization paths on a 3D surface plot and a 2D contour plot, so you can literally see why one approach struggles and the other doesn’t.
Full Source Code
1 | # ========================================================== |
Code Walkthrough
Function and gradient definitions (Section 1): rosenbrock computes $f(x,y)$ directly from the formula. rosenbrock_grad computes the analytic partial derivatives shown above. Supplying the exact gradient instead of letting the optimizer estimate it numerically (via finite differences) is one of the biggest speed wins available — it avoids extra function evaluations and gives more accurate search directions.
Naive gradient descent (Section 2): This is the “textbook” implementation: at every step, move a small distance (lr = 0.001) in the direction opposite the gradient. Because the Rosenbrock valley is long, narrow, and curved, a fixed small step size forces the algorithm to take tens of thousands of tiny, zig-zagging steps just to crawl along the valley floor. We deliberately cap it at 20,000 iterations here so it finishes in reasonable time, but notice in the printed output that it still hasn’t fully converged.
Fast optimization with SciPy BFGS (Section 3): scipy.optimize.minimize with method="BFGS" uses a quasi-Newton approach: it builds up an approximation of the curvature (the Hessian) as it goes, allowing it to take much smarter, adaptively-sized steps. Combined with the analytic gradient passed via jac=rosenbrock_grad, this converges in typically fewer than 40 iterations — a dramatic reduction compared to the naive loop. The callback function records every intermediate point so we can plot the path afterward.
Timing comparison (Section 4): We use time.time() before and after each optimization to measure wall-clock performance, then print a clear side-by-side summary including how many iterations each method needed and the resulting speedup factor.
Vectorized grid for plotting (Section 5): Instead of looping over every $(x, y)$ pair in Python (which would be extremely slow for a 400×400 grid = 160,000 points), we use np.meshgrid combined with vectorized NumPy arithmetic to compute the entire surface Z in one shot. This is the same “vectorization” principle that makes the BFGS run fast — pushing work into optimized C-level array operations instead of Python-level loops.
3D surface plot (Section 6): We plot log1p(Z) instead of raw Z because the Rosenbrock function’s values span an enormous range (from 0 near the minimum to tens of thousands at the edges of the plotted domain). Without the log compression, the banana-shaped valley would be invisible, flattened under one dominant peak. The log1p (log of 1+Z) keeps the shape interpretable while safely handling values near zero.
2D contour plot with paths (Section 7): Log-spaced contour levels (np.logspace) again handle the wide value range gracefully, clearly revealing the curved valley. On top of the contours we plot the naive gradient descent path in red and the BFGS path in blue — this is where the difference between the two approaches becomes visually obvious. You’ll see the red path creeping slowly along the valley in tiny steps, while the blue path jumps directly toward the true minimum, marked with a green star at $(1, 1)$.
Result
Running the code above in Google Colab will print a timing/iteration comparison table, followed by a combined figure showing the 3D landscape on the left and the contour map with both optimization paths on the right.
======================================================= Naive Gradient Descent Iterations : 20000 Final point : (0.99982, 0.99964) Final f(x,y) : 0.00000003 Elapsed time : 0.2666 sec ======================================================= SciPy BFGS (analytic gradient) Iterations : 38 Final point : (1.00000, 1.00000) Final f(x,y) : 0.00000000 Elapsed time : 0.0106 sec ======================================================= BFGS was about 25.2x faster in wall-clock time, and used only 38 iterations vs 20000.
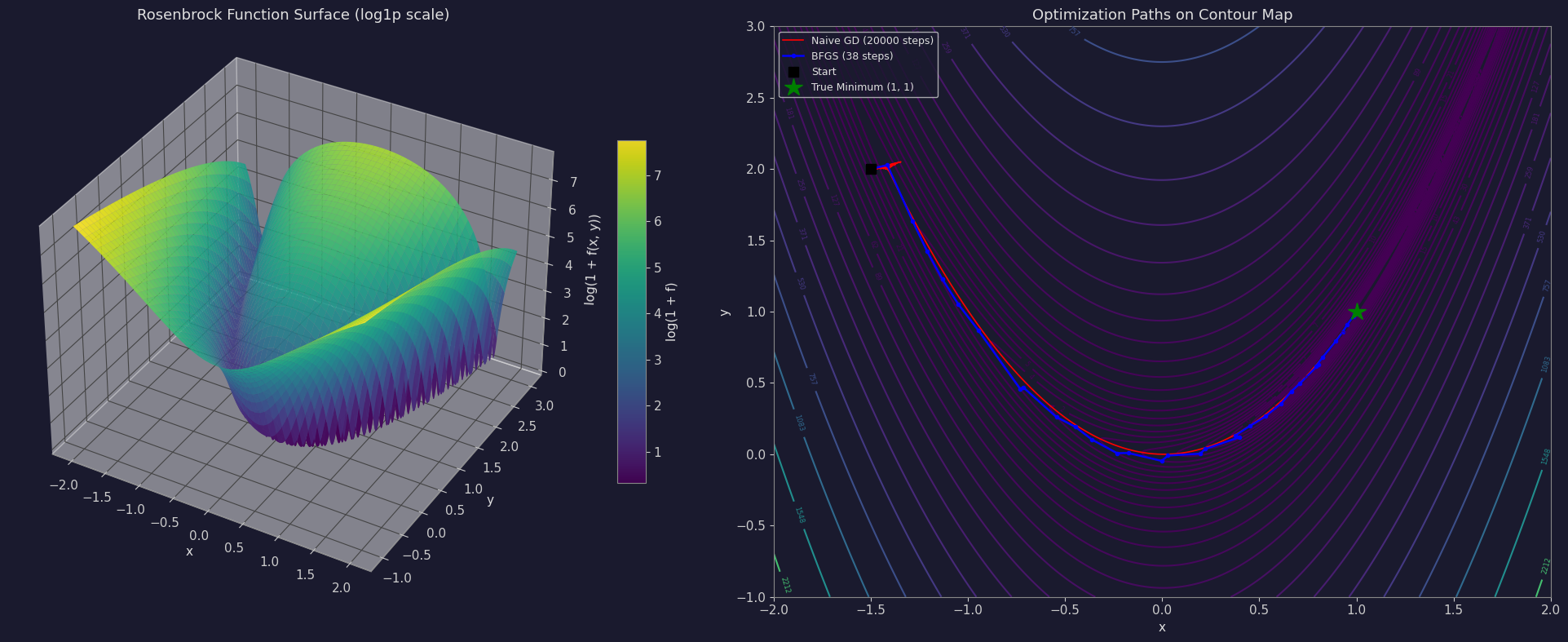
Takeaways
This example highlights two important optimization lessons that generalize far beyond the Rosenbrock function:
- Step size matters enormously. A fixed small learning rate is “safe” but painfully slow on ill-conditioned, curved landscapes like this one.
- Using derivative information and adaptive step sizing (as BFGS does) can turn tens of thousands of iterations into just a few dozen, while also landing much closer to the true minimum.
The Rosenbrock function remains a staple benchmark in optimization research precisely because it exposes these weaknesses so clearly — if an algorithm handles the banana-shaped valley efficiently, it’s usually a strong sign that it will perform well on other difficult, non-convex problems too.