Example Problem
We will simulate the orbit of a planet around a star using Kepler’s laws of planetary motion and Newtonian mechanics.
The goal is to calculate the orbit of the planet and visualize it.
Problem Description
Kepler’s Laws:
- Planets move in elliptical orbits with the star at one focus.
- The line connecting a planet to the star sweeps out equal areas in equal times.
Newtonian Mechanics:
- The gravitational force between the star and the planet dictates the motion:
$$
F = \frac{G M m}{r^2}
$$ - The planet’s position is updated using numerical integration of this force.
- The gravitational force between the star and the planet dictates the motion:
Python Code Implementation
Here’s the $Python$ implementation:
1 | import numpy as np |
Code Explanation
Initial Conditions:
- The planet starts at a distance $( r_0 ) (1 AU)$ with an initial velocity perpendicular to the radius.
Numerical Integration:
- At each time step:
- Calculate the gravitational acceleration $( a = F / m )$.
- Update the velocity using $( v = v + a \cdot dt )$.
- Update the position using $( r = r + v \cdot dt )$.
- At each time step:
Scaling:
- The positions are scaled to astronomical units $(AU)$ for clear visualization.
Plot:
- The orbit is plotted, showing the elliptical path of the planet around the star.
Results Visualization
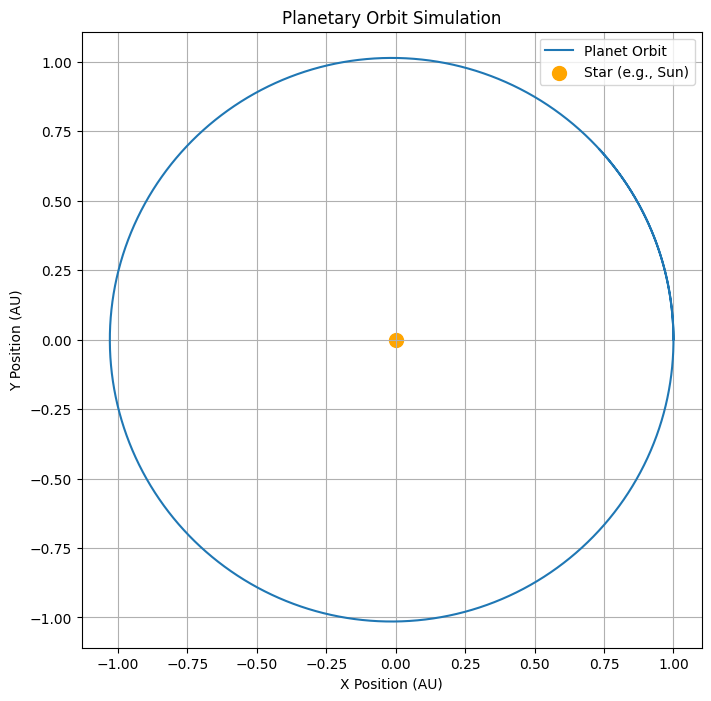
Orbit Shape:
- The planet’s trajectory forms an ellipse with the star at one focus.
Key Observations:
- The planet moves faster when it is closer to the star (perihelion).
- The planet moves slower when it is farther from the star (aphelion), illustrating Kepler’s second law.
This simulation demonstrates how planetary orbits emerge from gravitational interactions.