
3Dグラフ
scikit-learnを使用して、3Dグラフ化を行うために、まず問題を設定し、それを解決するサンプルコードを提供します。
ここでは、3つの特徴量を持つサンプルデータセットを使用して、分類問題を解決し、3Dプロットで可視化します。
以下は、サンプルコードの一例です。
1 | import numpy as np |
このコードは、3つの特徴量を持つサンプルデータを生成し、SVMを使用して二項分類モデルを訓練します。
その後、3Dグラフを使用してデータ、決定境界、およびサポートベクトルを可視化します。
このコードを実行すると、3Dプロットが表示されます。
ソースコード解説
このコードは、サポートベクトルマシン(SVM)を使用して2つのクラスに分類し、その結果を3Dグラフで視覚化するものです。
1. ライブラリのインポート:
numpy:数値計算のためのPythonライブラリ。matplotlib.pyplot:グラフの描画に使用するPythonライブラリ。mpl_toolkits.mplot3d:3Dプロットを作成するためのMatplotlibのツールキット。sklearn.datasets:機械学習のためのデータセットを生成するためのScikit-learnのサブモジュール。sklearn.model_selection:データを訓練用とテスト用に分割するためのScikit-learnのサブモジュール。sklearn.preprocessing:データの前処理(標準化)を行うためのScikit-learnのサブモジュール。sklearn.svm.SVC:Scikit-learnのSVM分類器をインポート。
2. サンプルデータの生成:
make_classification関数を使用して、サンプルデータを生成します。
このデータは3つの特徴量(n_features=3)と2つのクラス(n_classes=2)から成り、2つのクラスを分類するためのデータセットです。
3. データの訓練用とテスト用への分割:
train_test_split関数を使用して、生成されたデータセットを訓練用データとテスト用データに分割します。
デフォルトで80%が訓練データとなり、20%がテストデータとなります。
4. 特徴量の標準化:
StandardScalerを使用して、特徴量を標準化(平均0、分散1)します。
これは一般的な前処理手法で、特徴量のスケールを調整するのに役立ちます。
5. サポートベクトルマシン(SVM)を使って分類モデルを訓練:
SVCを使用して、線形SVM分類モデルを訓練します。
これにより、データを最適な線形決定境界で分割し、分類モデルが作成されます。
6. 3Dグラフの設定:
mpl_toolkits.mplot3dを使用して、3Dプロットを設定します。- グリッドを作成し、決定境界を生成します。
- サポートベクトルを3Dプロット上にプロットします。サポートベクトルは訓練データの中で特に重要なサンプルであり、分類モデルの性能に大きな影響を与えます。
- 決定境界をプロットし、2つの異なるクラスを分ける境界を視覚化します。
7. 軸ラベル:
- 各軸には “Feature 1”、”Feature 2”、および “Feature 3” のラベルが付いており、それぞれの軸がデータの特徴量を表しています。
8. plt.show()を使用して、3Dグラフを表示します。
このコードは、SVMを使用して分類モデルを訓練し、そのモデルの決定境界とサポートベクトルを3Dグラフで可視化するための例です。
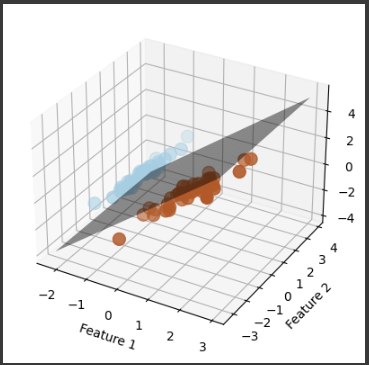
結果解説
このグラフの主な要素とその要素の説明を行います。
1. 3Dプロット:
- グラフは3次元空間内にあり、3つの特徴量に対応しています。
これらの特徴量は “Feature 1”、”Feature 2”、および “Feature 3” です。
2. サポートベクトル:
- サポートベクトルは訓練データセット内のサンプルで、分類器の決定境界に最も近いサンプルです。
グラフ内では、サポートベクトルがプロットされており、それらは散布図内で色分けされています。
異なる色は異なるクラスを表しており、サポートベクトルは分類器の決定境界に最も影響を与える点です。
3. 決定境界:
- 決定境界は、2つの異なるクラスを分けるための境界線を示しています。
この境界は、サポートベクトルマシンが学習した分類ルールに基づいて設定されており、直線として描かれています。
境界はクラス1とクラス2を区別するための境界線であり、クラス1の点とクラス2の点が異なる側に存在します。
4. 軸ラベル:
- 各軸には “Feature 1”、”Feature 2”、および “Feature 3” のラベルがあり、それぞれの軸がどの特徴量を表しているかを示しています。
この3Dグラフは、SVMによって学習された分類モデルが、3つの特徴量に基づいてデータを効果的に分類していることを視覚的に示しています。
境界線は、2つの異なるクラスを区別するための基準を提供し、サポートベクトルは分類器の重要な要素であることが強調されています。