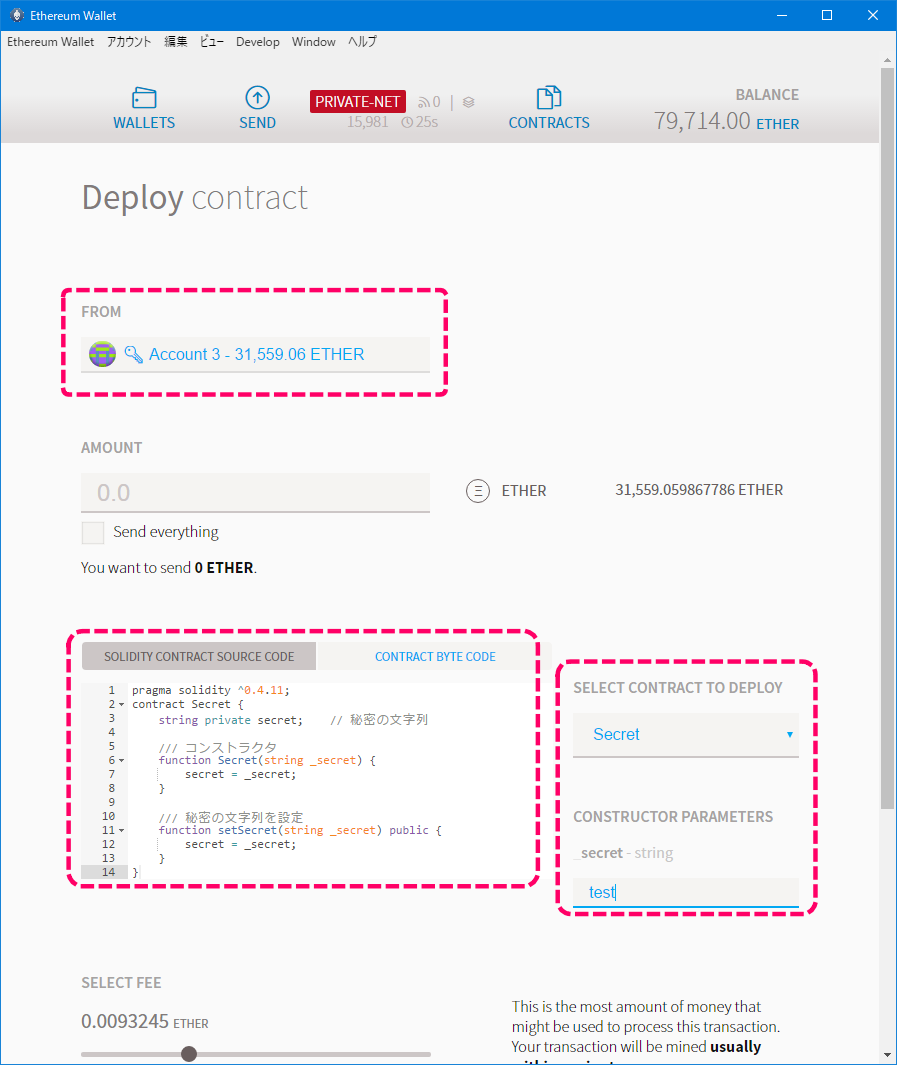
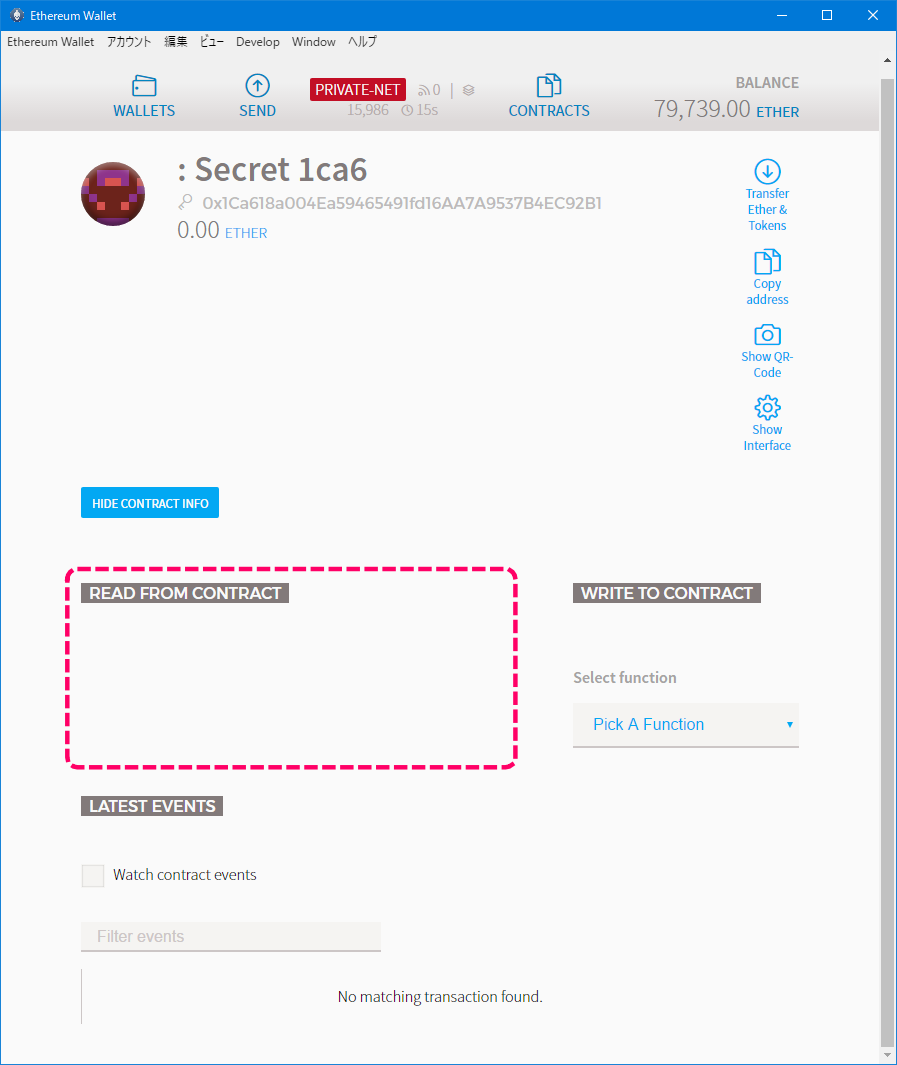
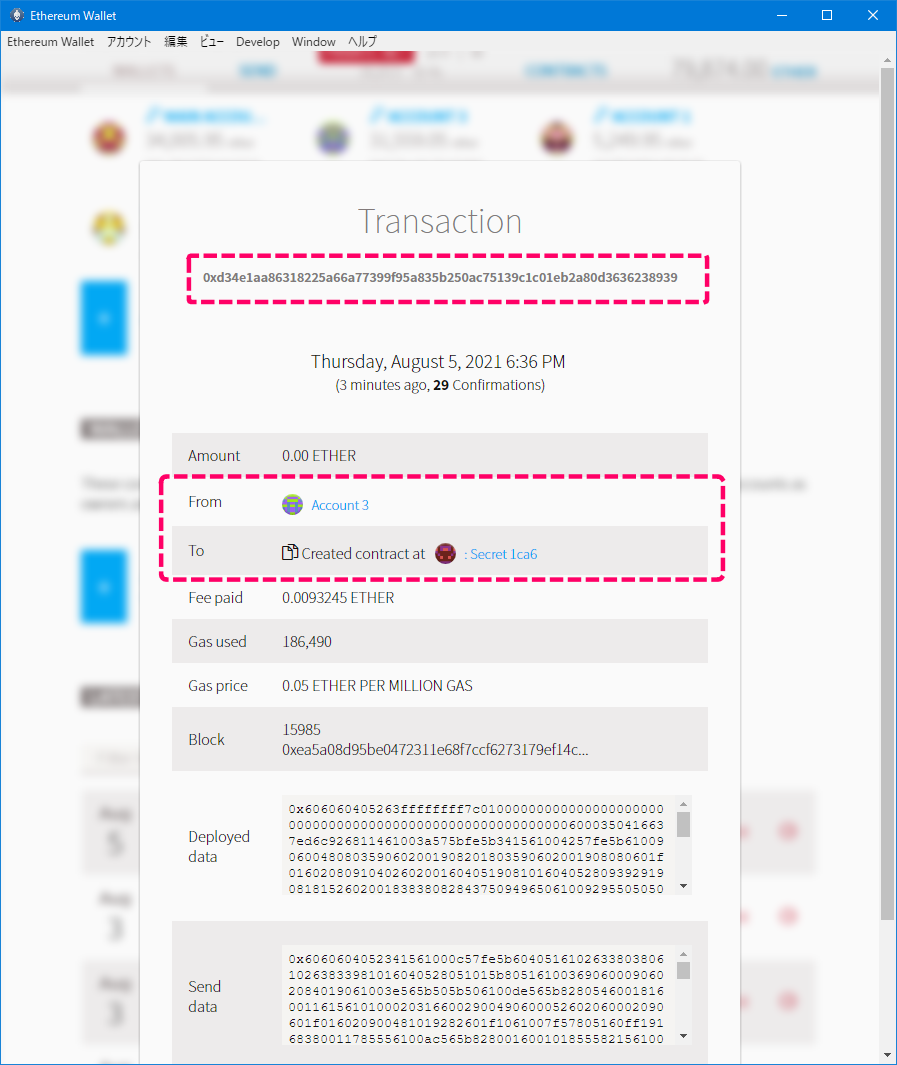
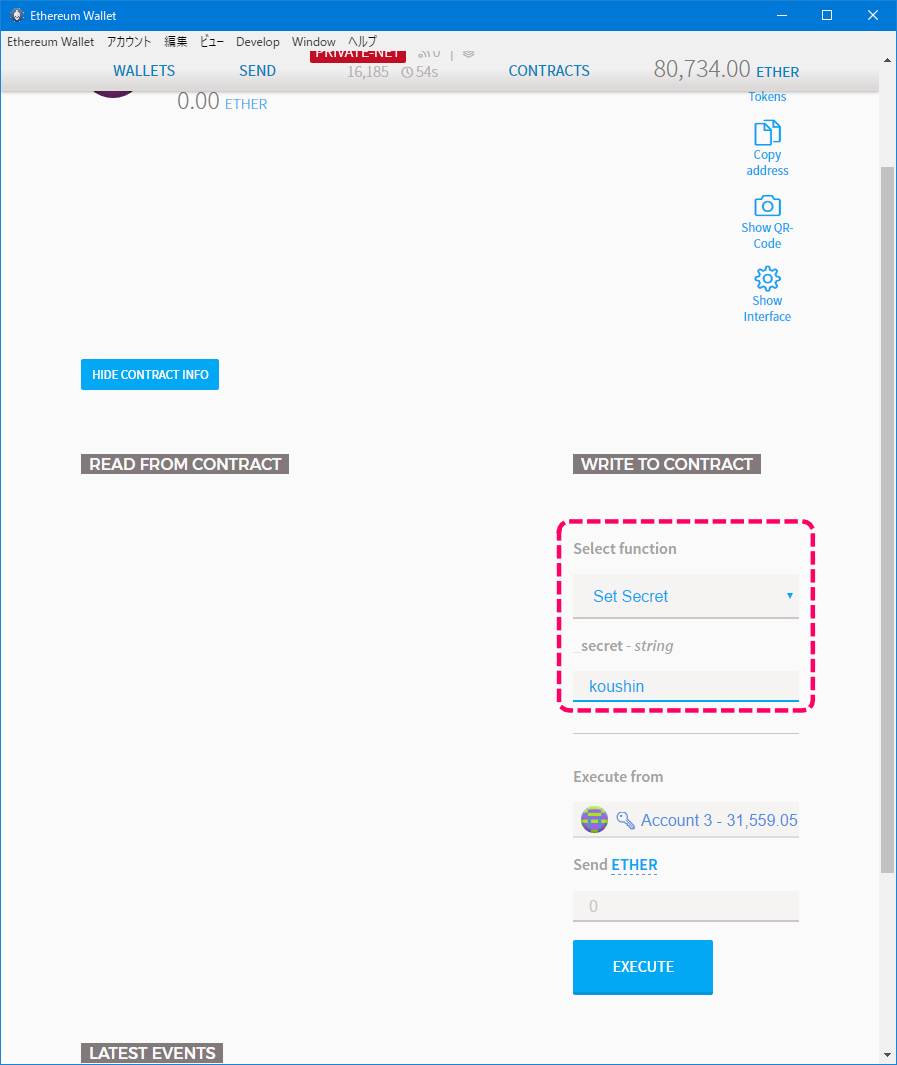
1
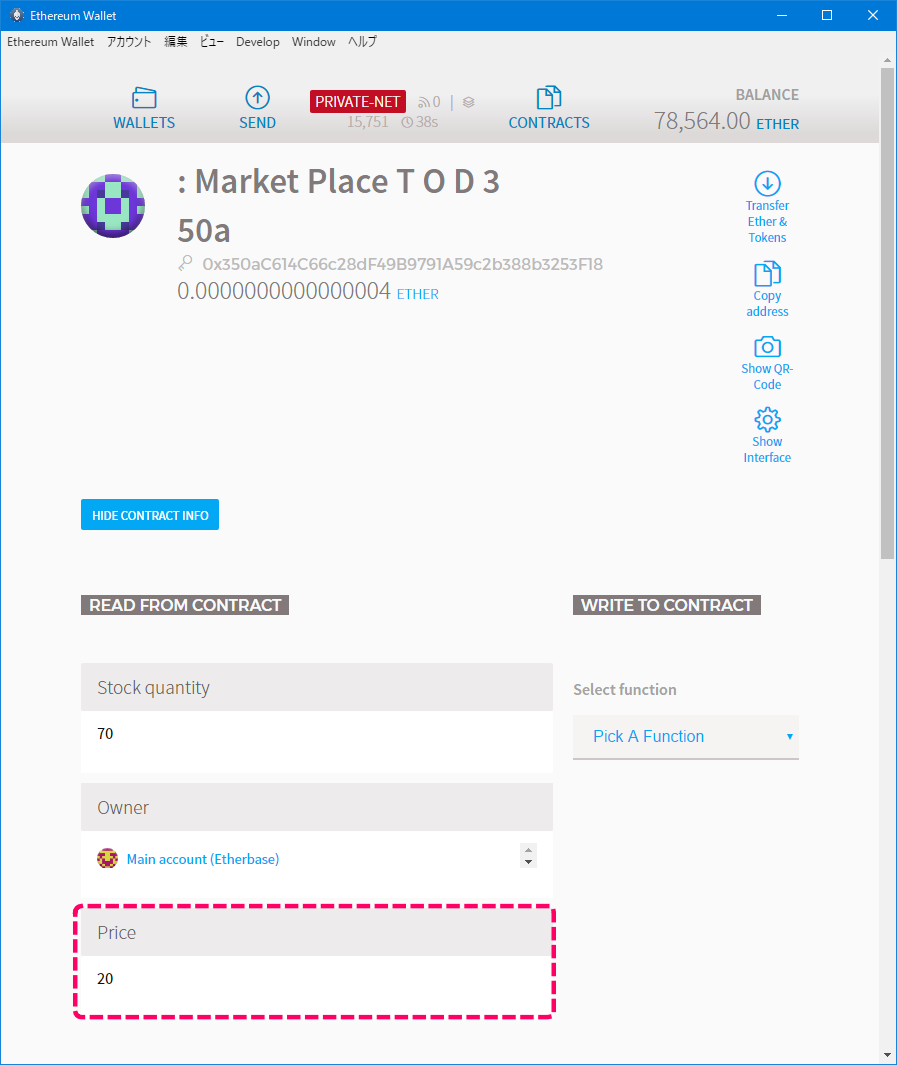
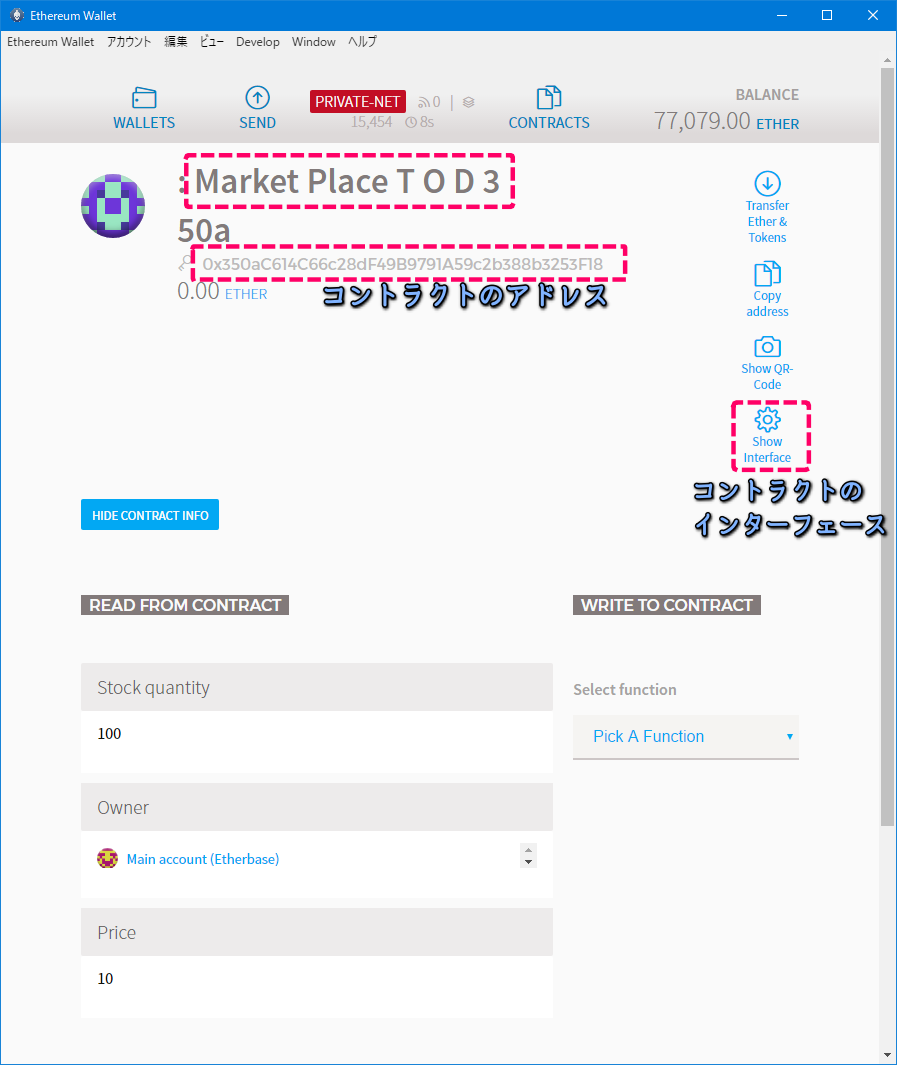
| var mpt = eth.contract([ { "constant": true, "inputs": [], "name": "stockQuantity", "outputs": [ { "name": "", "type": "uint256", "value": "100" } ], "payable": false, "type": "function" }, { "constant": false, "inputs": [ { "name": "_price", "type": "uint256" } ], "name": "updatePrice", "outputs": [], "payable": false, "type": "function" }, { "constant": true, "inputs": [], "name": "owner", "outputs": [ { "name": "", "type": "address", "value": "0xec3b01f36b44182746ca109230567c4915512e35" } ], "payable": false, "type": "function" }, { "constant": true, "inputs": [], "name": "price", "outputs": [ { "name": "", "type": "uint256", "value": "10" } ], "payable": false, "type": "function" }, { "constant": false, "inputs": [ { "name": "_quantity", "type": "uint256" } ], "name": "buy", "outputs": [], "payable": true, "type": "function" }, { "inputs": [], "payable": false, "type": "constructor" }, { "anonymous": false, "inputs": [ { "indexed": false, "name": "_price", "type": "uint256" } ], "name": "UpdatePrice", "type": "event" }, { "anonymous": false, "inputs": [ { "indexed": false, "name": "_price", "type": "uint256" }, { "indexed": false, "name": "_quantity", "type": "uint256" }, { "indexed": false, "name": "_value", "type": "uint256" }, { "indexed": false, "name": "_change", "type": "uint256" } ], "name": "Buy", "type": "event" } ]).at('0x350aC614C66c28dF49B9791A59c2b388b3253F18')
|