前回記事にて、川と橋のあるマップをそれなりに攻略できたのですが、橋を渡ってくれず川をつっきる最短距離のルートとなってしまいました。
[川と橋を追加したマップイメージ]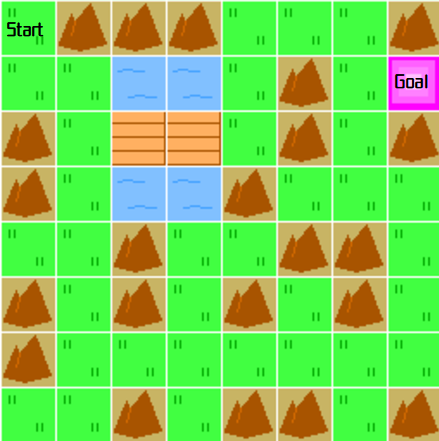
今回は橋を渡るようにカスタムGym環境を修正していきます。
橋を渡るように修正
やはりまず思いつくのが、川に入った時の報酬のマイナスポイントを変化させることです。
-5に設定している報酬を少しずつ変更して最終的に-100としました。(95行目)
[ソース]
1 | import sys |
このカスタムGym環境を読み込んで、これまでと同じように学習を行います。
(前回記事のtrain6.pyを実行)
結果は次のようになりました。
[結果]
☆山山山 山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-1.] ----------- S山山山 山 ☆ 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-2.] ----------- S山山山 山 ☆川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-3.] ----------- S山山山 山 川川 山 G 山☆三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-4.] ----------- S山山山 山 川川 山 G 山 ☆三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-5.] ----------- S山山山 山 川川 山 G 山 三☆ 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-6.] ----------- S山山山 山 川川 山 G 山 三三☆山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-7.] ----------- S山山山 山 川川☆山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-8.] ----------- S山山山☆ 山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-9.] ----------- S山山山 ☆ 山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-10.] ----------- S山山山 ☆山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-11.] ----------- S山山山 山 川川 山☆G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [800.] total_reward [789.] ----------- total_reward: [789.]
思った通りに橋を渡ってゴールにまっすぐたどり着いています。
やはり強化学習は報酬の与え方がとても重要だという事を実感しました。