今回は、川と橋のあるマップを強化学習で攻略していきます。
[川と橋を追加したマップイメージ]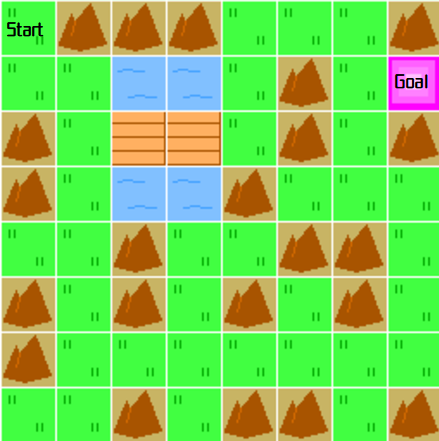
川と橋と橋のあるマップを強化学習
前々回に実装したカスタムGym環境(env6.py)を9行目で読み込み、強化学習を行います。
学習アルゴリズムはACKTR(25行目)で、学習ステップ数は128000(28行目)としています。
[ソース]
1 | # 警告を非表示 |
学習はなかなかうまくいきませんでした。
学習ステップ数を増やしたり、学習アルゴリズムをPPO2に戻したりしたのですが、それでもうまくゴールまでたどり着いてくれません😑
うまく学習できない場合の対処法
いろいろと学習方法を変更したのですがうまくいかなかったので、カスタムGym環境のほうを見直すことにしました。
報酬を見直して、ゴール時の報酬が少ないのかと思い100から800に変更してみました。
(前々回ソースenv6.pyの91行目がその報酬設定となります)
そうするとあっさりゴールまでたどり着くことができました😅
学習済みモデルを使って攻略
うまくゴールまでたどり着くことができるようになった学習済みモデルを使って、プレイしてみます。
[ソース]
1 | # 警告を非表示 |
実行結果は以下のようになりました。
[結果]
Loading a model without an environment, this model cannot be trained until it has a valid environment. ☆山山山 山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-1.] ----------- S山山山 山 ☆ 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-2.] ----------- S山山山 山 ☆川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-5.] total_reward [-7.] ----------- S山山山 山 ☆川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-5.] total_reward [-12.] ----------- S山山山 山 川☆ 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-13.] ----------- S山山山 山 川川☆山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-14.] ----------- S山山山☆ 山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-15.] ----------- S山山山 ☆ 山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-16.] ----------- S山山山 ☆山 川川 山 G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [-1.] total_reward [-17.] ----------- S山山山 山 川川 山☆G 山 三三 山 山 山 川川山 山 山山 山 山 山 山 山 山 山山 山 reward: [800.] total_reward [783.] ----------- total_reward: [783.]
まっすぐゴールまで向かっていますが、なにか引っ掛かります。
そう、橋を渡らず川を突っ切っているのです😥
確かに距離的には川を渡った方が近いのかもしれませんが、マップを作った時の想定としては橋をわたって欲しかったのです。
報酬的には、川に入ると-5ポイントで橋を渡ると-1ポイントなので、橋をわたる方が総報酬としは上になるはずなんですが・・・
次回は、川ではなくきちんと橋を渡ってくれるように調整を行いたいと思います。
(おそらく報酬設定を変えるだけで対応可能だと思うのですが・・・)