今回は、広げたマップを強化学習で攻略していきます。
[広くしたマップイメージ]
広げたマップマップを強化学習
前々回に実装したカスタムGym環境(env7.py)を9行目で読み込み、強化学習を行います。
学習アルゴリズムはACKTR(25~32行目)で、学習率は0.01から50.0に段階的に変更して結果がどのように変わるか確認していきます。
学習ステップ数は128000(35行目)としています。
[ソース]
1 | # 警告を非表示 |
各実行結果をまとめると下記のようになりました。
[結果]
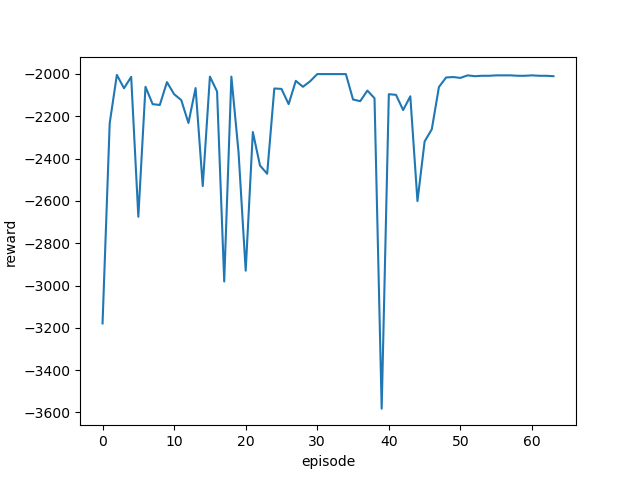
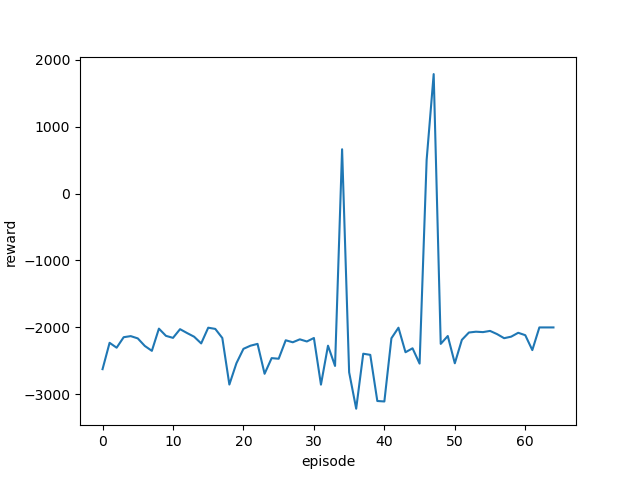
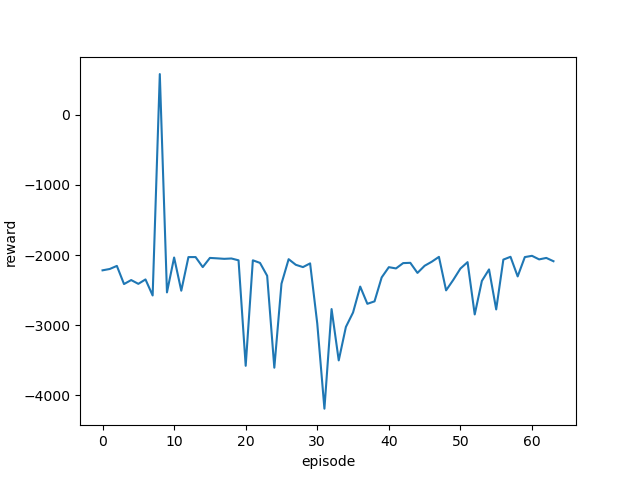
| 学習率 | 最終位置・最終報酬 | 平均報酬遷移 |
|---|---|---|
| 0.01 |  |
 |
| 0.05 |  |
 |
| 0.1 |  |
 |
| 0.5 | 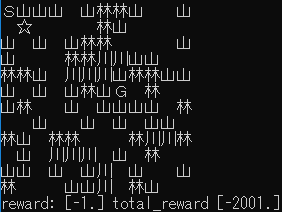 |
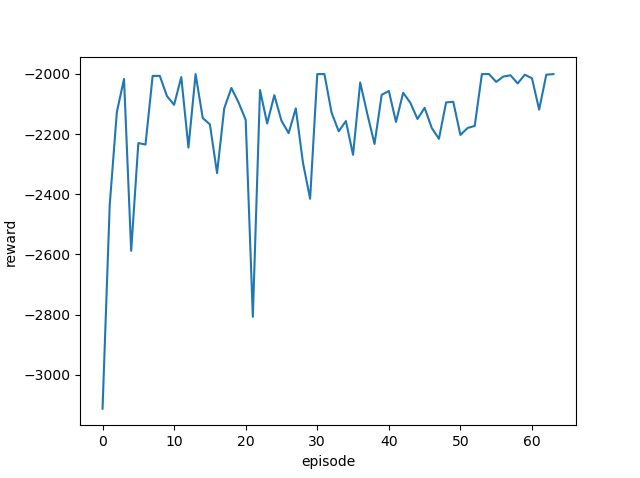 |
| 1.0 |  |
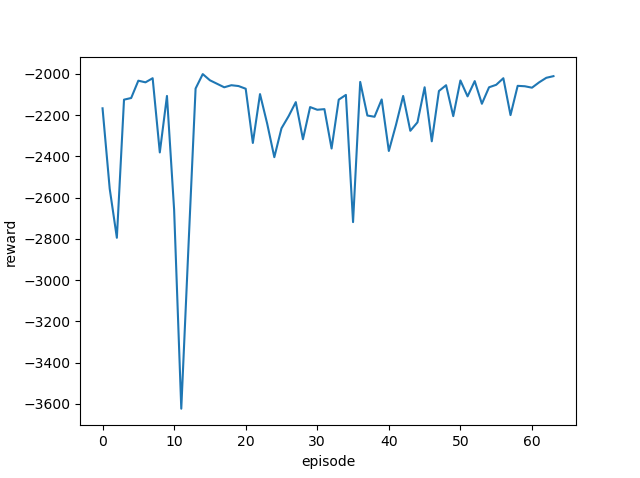 |
| 5.0 |  |
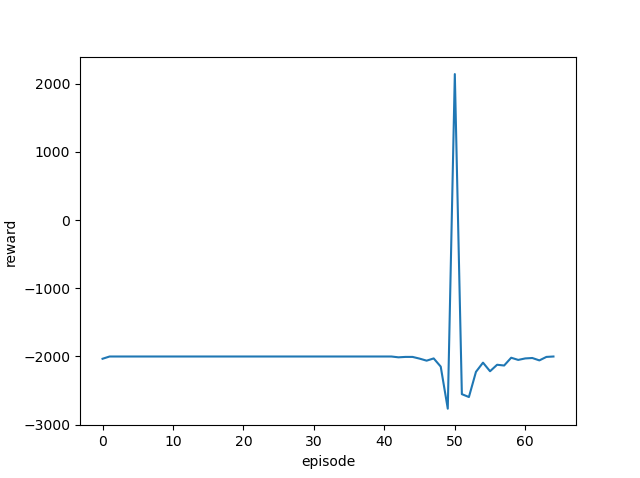 |
| 10.0 |  |
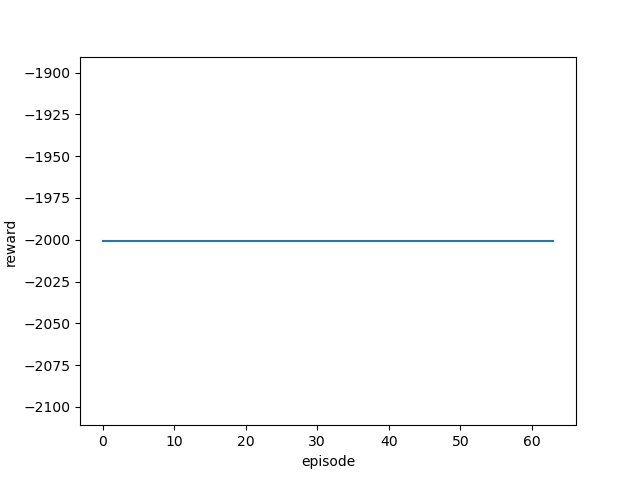 |
| 50.0 |  |
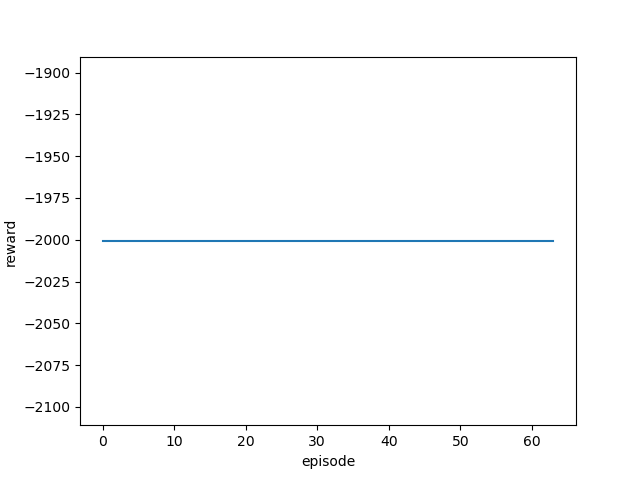 |
全然ゴールできていません。
ランダムで実行していたときは、半分ほどゴールまでたどり着いていたのでランダム実行よりはるかに劣る結果ということになります😥
スタート地点付近からほとんど動かないことが多く、学習率の調整以前の問題だと考えられます。
ということで次回はカスタム環境の報酬設定を見直していきたいと思います。