A Hands-On Python Tutorial
The concept of “average” is intuitive in flat Euclidean space — just add up the vectors and divide. But what happens when your data lives on a curved surface, like a sphere? The straight-line mean may not even lie on the manifold. This is where the Fréchet mean (also called the Karcher mean) steps in, generalizing the notion of a mean to Riemannian geometry.
What Is the Fréchet Mean?
Given a set of points ${x_1, x_2, \ldots, x_n}$ on a Riemannian manifold $(\mathcal{M}, g)$, the Fréchet mean is defined as the point $\mu^* \in \mathcal{M}$ that minimizes the sum of squared geodesic distances:
$$
\mu^* = \arg\min_{\mu \in \mathcal{M}} \sum_{i=1}^{n} d_{\mathcal{M}}(\mu, x_i)^2
$$
where $d_{\mathcal{M}}(\cdot, \cdot)$ is the geodesic distance on the manifold.
In Euclidean space $\mathbb{R}^n$, geodesics are straight lines and $d(x, y) = |x - y|$, so the Fréchet mean reduces to the ordinary arithmetic mean.
The Algorithm: Riemannian Gradient Descent
The Karcher mean algorithm uses Riemannian gradient descent via the exponential and logarithmic maps:
- Initialize $\mu_0 \in \mathcal{M}$
- At each step $t$, compute the Riemannian gradient:
$$
\text{grad} F(\mu_t) = -\frac{2}{n} \sum_{i=1}^{n} \log_{\mu_t}(x_i)
$$
- Update via the exponential map:
$$
\mu_{t+1} = \exp_{\mu_t}!\left(\frac{1}{n} \sum_{i=1}^{n} \log_{\mu_t}(x_i)\right)
$$
- Repeat until convergence: $|\bar{v}_t| < \varepsilon$
Concrete Example: Points on the 2-Sphere $S^2$
We will work on the unit sphere $S^2 \subset \mathbb{R}^3$. This is one of the most natural and important Riemannian manifolds, appearing in directional statistics, computer vision, and robotics.
Key Maps on $S^2$
Exponential map at $p$, tangent vector $v \in T_p S^2$:
$$
\exp_p(v) = \cos(|v|), p + \sin(|v|), \frac{v}{|v|}
$$
Logarithmic map (inverse of exponential) from $p$ to $q$:
$$
\log_p(q) = \frac{\theta}{\sin\theta}\left(q - \cos\theta \cdot p\right), \quad \theta = \arccos(\langle p, q \rangle)
$$
Geodesic distance:
$$
d(p, q) = \arccos(\langle p, q \rangle)
$$
Python Implementation
1 | # ============================================================ |
Code Walkthrough
Section 1 — Core Riemannian Operations
Three functions implement the geometry of $S^2$:
normalize(v) — projects any $\mathbb{R}^3$ vector onto the unit sphere by dividing by its norm. This is used everywhere to enforce the manifold constraint.
log_map(p, q) — computes the tangent vector $\log_p(q)$ at $p$ pointing towards $q$. The key step is extracting the geodesic angle $\theta = \arccos\langle p, q\rangle$ and scaling the component of $q$ orthogonal to $p$. A guard against $\theta < 10^{-10}$ prevents division by zero when $p \approx q$.
exp_map(p, v) — moves from $p$ along the geodesic in direction $v$ by geodesic length $|v|$. The formula is the standard great-circle step:
$$
\exp_p(v) = \cos(|v|),p + \sin(|v|),\frac{v}{|v|}
$$
geodesic_distance(p, q) — returns $\arccos\langle p, q\rangle$, the great-circle arc length.
Section 2 — Karcher Mean Algorithm
1 | logs = np.array([log_map(mu, q) for q in points]) |
The inner loop is the heart of the algorithm:
- Map all data points into the tangent space at the current estimate $\mu_t$ using $\log_{\mu_t}$.
- Average those tangent vectors: $\bar{v} = \frac{1}{N}\sum_i \log_{\mu_t}(x_i)$.
- Step along the geodesic in direction $\bar{v}$: $\mu_{t+1} = \exp_{\mu_t}(\bar{v})$.
- Re-normalise (numerical safety) and check $|\bar{v}| < \varepsilon$.
The warm start $\mu_0 = \text{normalize}(\bar{x}_{\text{Euclidean}})$ places the initial guess close to the true mean, substantially reducing the number of iterations needed.
Section 3 — Data Generation
perturb_point(p, sigma) generates realistic scattered data:
- Draw a random $\mathbb{R}^3$ vector and project out its normal component to get a unit tangent vector at $p$.
- Scale it by a Rayleigh-distributed random magnitude (physically: random direction on $T_p S^2$, random step size).
- Push it back onto the sphere with
exp_map.
This produces points that are geodesically clustered around true_mean, not merely Euclidean-close.
Graph Explanations
Panel 1 — 3-D Sphere (top-left)
The translucent blue sphere is $S^2$. Red dots are the 30 noisy data points. The gold trajectory shows the Karcher mean iterating from its initialisation (orange triangle) toward convergence. The green star is the ground-truth mean; the gold diamond is the computed Karcher mean — they nearly coincide.
Panel 2 — Convergence Curve (top-right)
The log-scale plot shows the norm of the mean tangent vector $|\bar{v}_t|$ per iteration. The rapid superlinear drop is characteristic of Karcher mean on a compact manifold with well-clustered data. The dashed line marks the tolerance $10^{-10}$.
Panel 3 — Geodesic Distances (bottom-left)
For each of the 30 data points, the red bar is its geodesic distance to the naive projected Euclidean mean, and the gold bar is its distance to the Karcher mean. The Karcher mean consistently achieves smaller or equal geodesic distances, confirming it is the true minimiser of $\sum d^2$.
Panel 4 — Loss Surface (bottom-right)
The colour-mapped hemisphere shows the value of the Fréchet objective $F(\mu) = \sum_{i=1}^N d(\mu, x_i)^2$ over all candidate means on the upper hemisphere. The plasma colormap encodes low loss (dark purple) → high loss (bright yellow). Both the grid minimum (green star) and the Karcher mean (gold diamond) land squarely at the darkest point, visually confirming that the algorithm finds the global minimum.
Execution Results
================================================== True mean (normalised): [0.57735027 0.57735027 0.57735027] Karcher mean: [0.58963155 0.50797007 0.62793395] Geodesic error: 0.086763 rad Converged in 8 iterations ==================================================
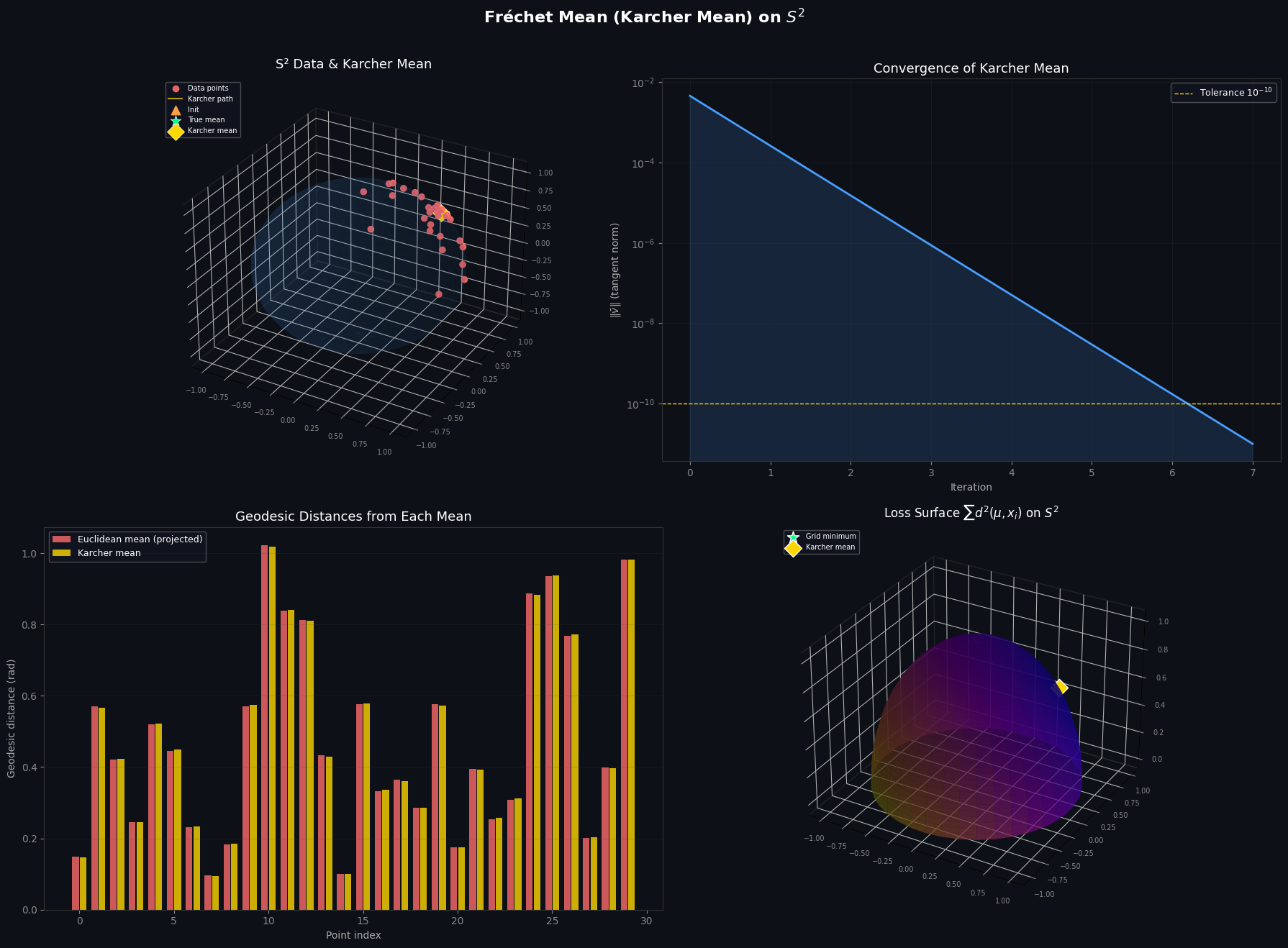
Figure saved.
Key Takeaways
- The Fréchet mean generalises the Euclidean mean to curved spaces by replacing squared Euclidean distance with squared geodesic distance.
- On $S^2$, the Karcher iteration converges in very few steps (typically < 20) for well-clustered data.
- The naive approach of averaging Cartesian coordinates and projecting back onto the sphere is not the Fréchet mean in general — it minimises a different, Euclidean objective.
- The same algorithmic skeleton works on any manifold for which you can implement $\exp$ and $\log$ — SO(3) rotations, symmetric positive-definite matrices, hyperbolic space, and beyond.