def agent(observation, configuration): # Number of Columns on the Board.(ボードのカラム数) columns = configuration.columns # Number of Rows on the Board.(ボードの行数) rows = configuration.rows # Number of Checkers "in a row" needed to win.(勝つために並べるコインの数) inarow = configuration.inarow # The current serialized Board (rows x columns).(現在のボードの状態。1次元として) board = observation.board # Which player the agent is playing as (1 or 2).(どちらのプレイヤーか) mark = observation.mark
# Return which column to drop a checker (action).(どのカラムに落とすかを返す) return 0
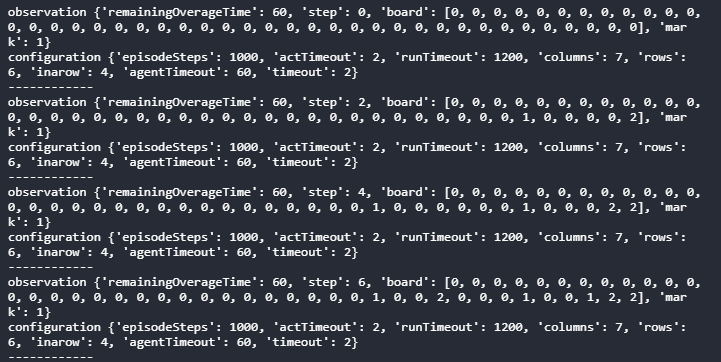
確認のために、前回作成したソースにエージェントが受け取る情報を表示する処理を追加し実行してみます。
[ソース]
1 2 3 4 5 6 7 8 9 10 11
def my_agent(observation, configuration): print('observation', observation) print('configuration', configuration) print('------------') from random import choice return choice([c for c in range(configuration.columns) if observation.board[c] == 0])
env.reset() # Play as the first agent against default "random" agent. env.run([my_agent, "random"]) env.render(mode="ipython", width=500, height=450)
from kaggle_environments import evaluate, make, utils
env = make("connectx", debug=True) env.render()
エージェントの作成
エージェントを作成します。
ここではサンプルとしてランダムにコインを落とす場所を決めているようです。
今後はこのロジックを実装していき勝率を上げていけばいいんですね。
[ソース]
1 2 3 4
# This agent random chooses a non-empty column. def my_agent(observation, configuration): from random import choice return choice([c for c in range(configuration.columns) if observation.board[c] == 0])
エージェントのテスト
上記で作成したエージェントのテストを行います。
ただ相手のロジックもランダムにコインを落とすようなので・・・・今回はただの動作確認用です。
[ソース]
1 2 3 4
env.reset() # Play as the first agent against default "random" agent. env.run([my_agent, "random"]) env.render(mode="ipython", width=500, height=450)
[結果]
上記のようなボードが現れてコインが次々に落とされ、コインが4つそろったら終了になります。
アニメーションとして動くのでちょっとおもしろいです。
エージェントのテストと訓練
エージェントのテストと訓練を行います。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12
# Play as first position against random agent. trainer = env.train([None, "random"])
observation = trainer.reset()
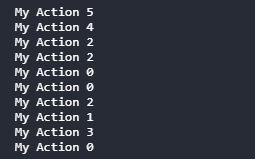
while not env.done: my_action = my_agent(observation, env.configuration) print("My Action", my_action) observation, reward, done, info = trainer.step(my_action) # env.render(mode="ipython", width=100, height=90, header=False, controls=False) env.render()
[結果]
一回の動作(どの位置にコインを落とすのか)ごとに、その動作がデバッグ表示されます。
エージェントの評価
作成したエージェントを評価します。
[ソース]
1 2 3 4 5 6
def mean_reward(rewards): return sum(r[0] for r in rewards) / float(len(rewards))
# Run multiple episodes to estimate its performance. print("My Agent vs Random Agent:", mean_reward(evaluate("connectx", [my_agent, "random"], num_episodes=10))) print("My Agent vs Negamax Agent:", mean_reward(evaluate("connectx", [my_agent, "negamax"], num_episodes=10)))
# "None" represents which agent you'll manually play as (first or second player). env.play([None, "negamax"], width=500, height=450)
[結果]
マス目をクリックしてみたのですが、「Processing…」と表示されたまま動作しませんでした。
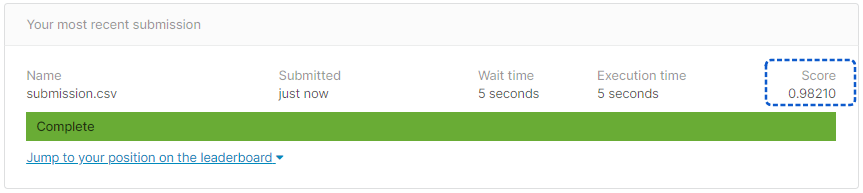
提出ファイルの書き出し
提出用のファイルを出力します。
[ソース]
1 2 3 4 5 6 7 8 9
import inspect import os
def write_agent_to_file(function, file): with open(file, "a" if os.path.exists(file) else "w") as f: f.write(inspect.getsource(function)) print(function, "written to", file)
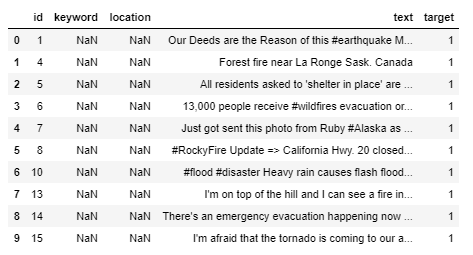
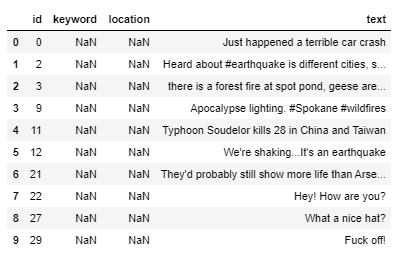
X_train,X_test,y_train,y_test = train_test_split(train,tweet['target'].values,test_size=0.15) print('Shape of train',X_train.shape) print("Shape of Validation ",X_test.shape)
def create_corpus(df): corpus=[] for tweet in tqdm(df['text']): words=[word.lower() for word in word_tokenize(tweet) if((word.isalpha()==1) & (word not in stop))] corpus.append(words) return corpus
corpus = create_corpus(df)
[結果]
単語ベクター化
GloVeの学習済みモデルを準備します。3つの次元(50 D ,100 D, 200 D)が用意されていますが、今回は100 Dを使います。
embedding_dict={} with open('../input/glove-global-vectors-for-word-representation/glove.6B.100d.txt','r') as f: for line in f: values = line.split() word = values[0] vectors = np.asarray(values[1:],'float32') embedding_dict[word] =vectors f.close()
for word,i in tqdm(word_index.items()): if i > num_words: continue emb_vec = embedding_dict.get(word) if emb_vec is not None: embedding_matrix[i] = emb_vec
spell = SpellChecker() def correct_spellings(text): corrected_text = [] misspelled_words = spell.unknown(text.split()) for word in text.split(): if word in misspelled_words: corrected_text.append(spell.correction(word)) else: corrected_text.append(word) return " ".join(corrected_text) text = "corect me plese" correct_spellings(text)
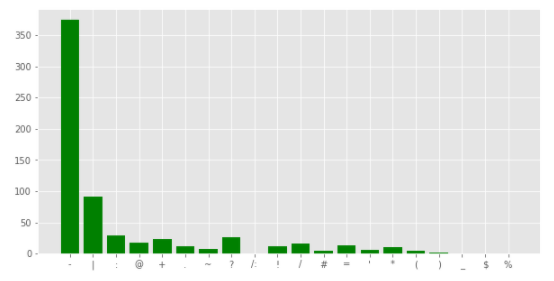
plt.figure(figsize=(10,5)) corpus = create_corpus(1)
dic = defaultdict(int) import string special = string.punctuation for i in (corpus): if i in special: dic[i] += 1 x,y = zip(*dic.items()) plt.bar(x,y)
[結果]
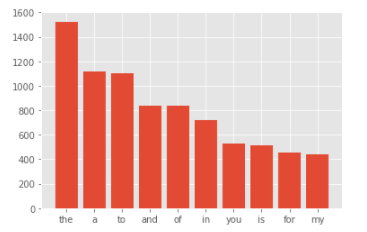
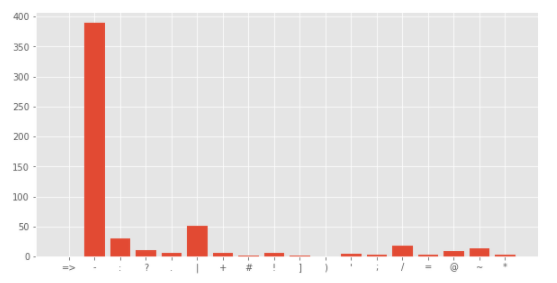
災害に関係のないツイートの句読点出現回数をグラフで表示します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13
plt.figure(figsize=(10,5)) corpus = create_corpus(0)
dic = defaultdict(int) import string special = string.punctuation for i in (corpus): if i in special: dic[i] += 1 x, y = zip(*dic.items()) plt.bar(x,y,color='green')
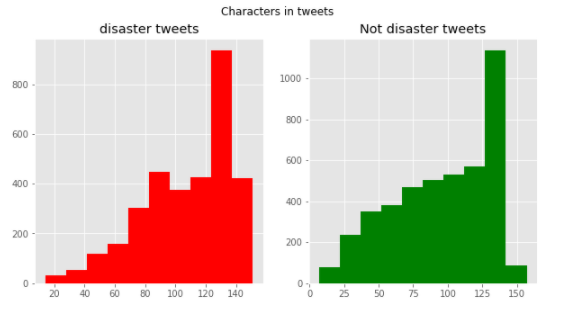
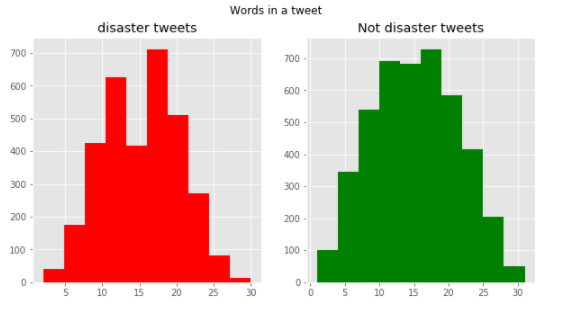
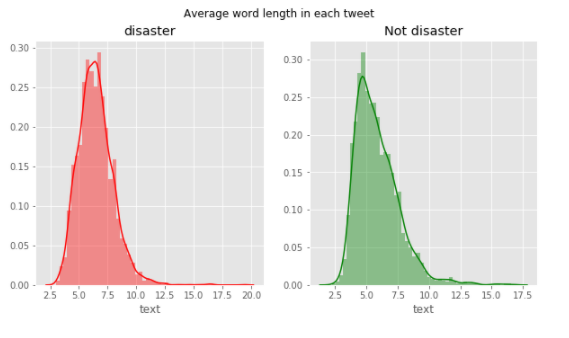
fig,(ax1,ax2)=plt.subplots(1,2,figsize=(10,5)) word=tweet[tweet['target']==1]['text'].str.split().apply(lambda x : [len(i) for i in x]) sns.distplot(word.map(lambda x: np.mean(x)),ax=ax1,color='red') ax1.set_title('disaster') word=tweet[tweet['target']==0]['text'].str.split().apply(lambda x : [len(i) for i in x]) sns.distplot(word.map(lambda x: np.mean(x)),ax=ax2,color='green') ax2.set_title('Not disaster') fig.suptitle('Average word length in each tweet')
import os import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np from nltk.corpus import stopwords from nltk.util import ngrams from sklearn.feature_extraction.text import CountVectorizer from collections import defaultdict from collections import Counter plt.style.use('ggplot') stop=set(stopwords.words('english')) import re from nltk.tokenize import word_tokenize import gensim import string from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from tqdm import tqdm from keras.models import Sequential from keras.layers import Embedding,LSTM,Dense,SpatialDropout1D from keras.initializers import Constant from sklearn.model_selection import train_test_split from keras.optimizers import Adam
# ライブラリをインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt import os from tqdm import tqdm import seaborn as sns from sklearn.model_selection import train_test_split import warnings warnings.filterwarnings("ignore")
import torch import torch.nn as nn import torchvision from torch.utils.data import DataLoader, Dataset from torchvision import transforms
# 学習率を更新する def update_lr(optimizer, lr): for param_group in optimizer.param_groups: param_group['lr'] = lr
# 学習する total_step = len(train_loader) curr_lr = learning_rate for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): images = images.to(device) labels = labels.to(device)
# Forward pass(順伝搬:初期の入力を層ごとに処理して出力に向けて送ること) outputs = model(images) loss = criterion(outputs, labels.flatten())
# Backward and optimize(逆伝播と最適化を行う) optimizer.zero_grad() loss.backward() optimizer.step()
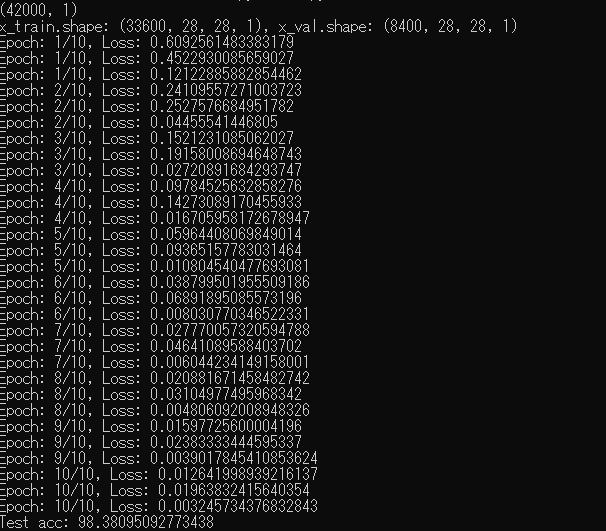
if (i + 1) % 300 == 0: print(f'Epoch: {epoch + 1}/{num_epochs}, Loss: {loss.item()}')
# 評価する model.eval() with torch.no_grad(): correct = 0 total = 0 for images, labels in val_loader: images = images.to(device) labels = labels.to(device)