マンハッタンプロット
ManhattanPlotコンポーネントを使うと、マンハッタンプロットを表示することができます。
マンハッタンプロットは、多数のデータポイント、非ゼロ振幅、および高い振幅値の分布を持つデータを表示します。
一般的にゲノムワイド関連解析(GWAS)で使用され、重要なSNP(個人間の遺伝情報のわずかな違いのこと。一塩基多型とも呼ばれる。)を表示することができます。
Dash Enterprise - https://dash.plotly.com/dash-bio/manhattanplot
上記のDash Enterpriseにあるサンプルを参考にして、マンハッタンプロットを表示します。
[ソースコード]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import pandas as pd
import dash
import dash_bio as dashbio
from dash import dcc
app = dash.Dash(__name__)
df = pd.read_csv('https://git.io/manhattan_data.csv')
app.layout = dcc.Graph(figure=dashbio.ManhattanPlot(dataframe=df))
if __name__ == '__main__':
app.run_server(debug=True)
|
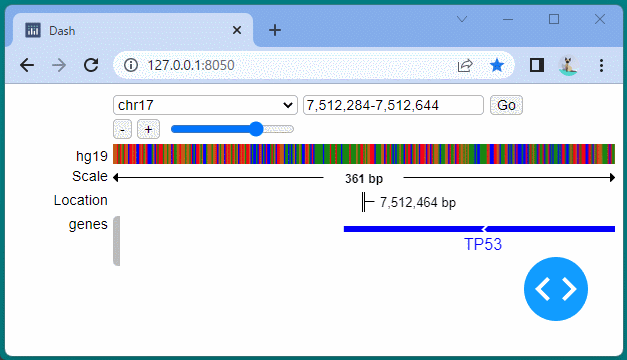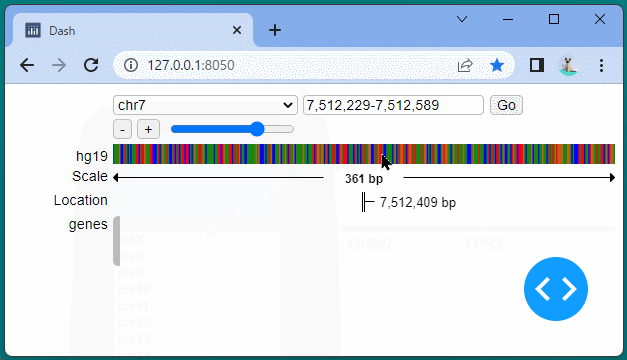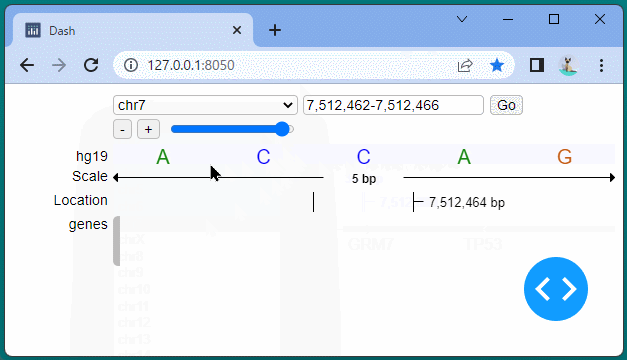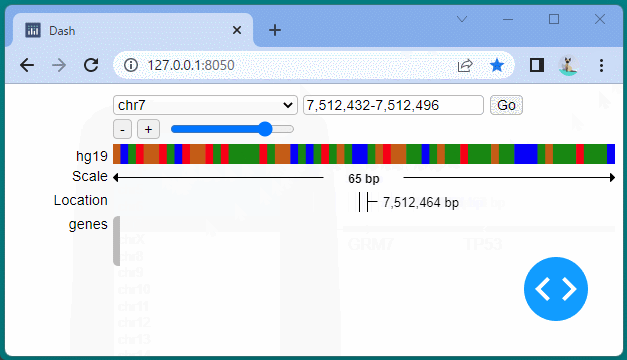
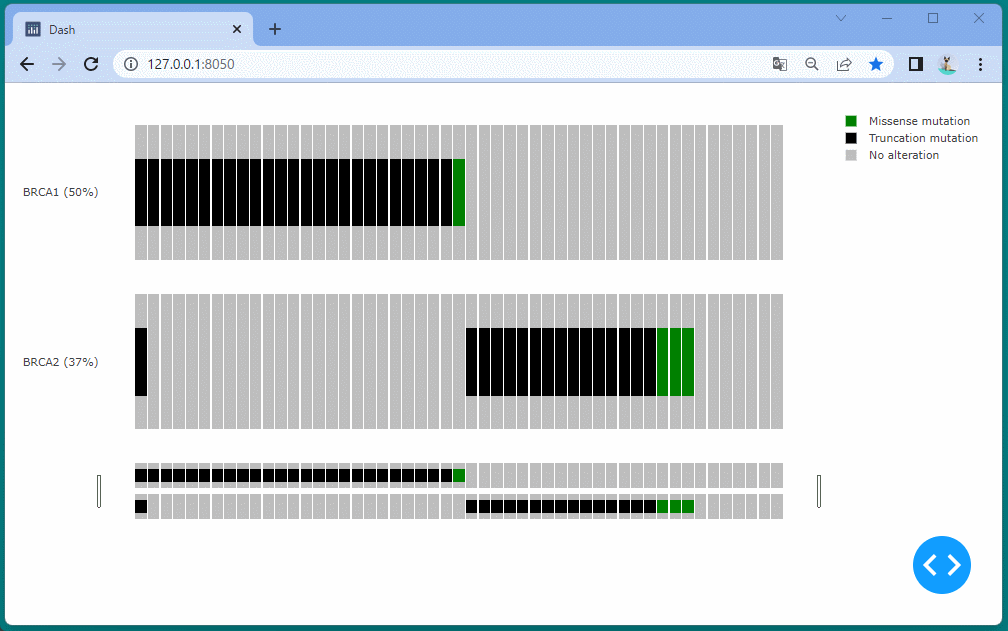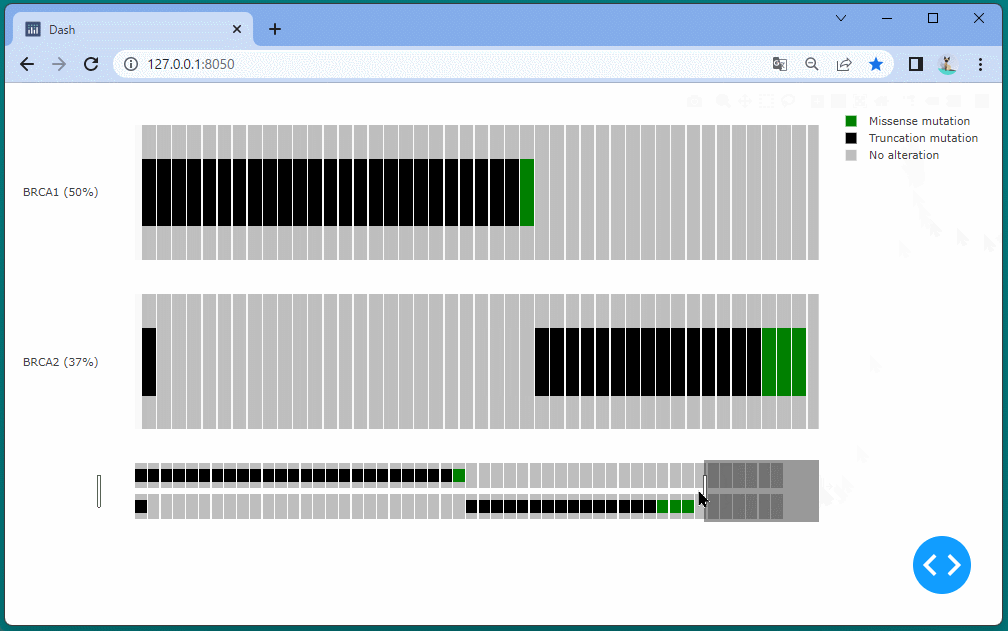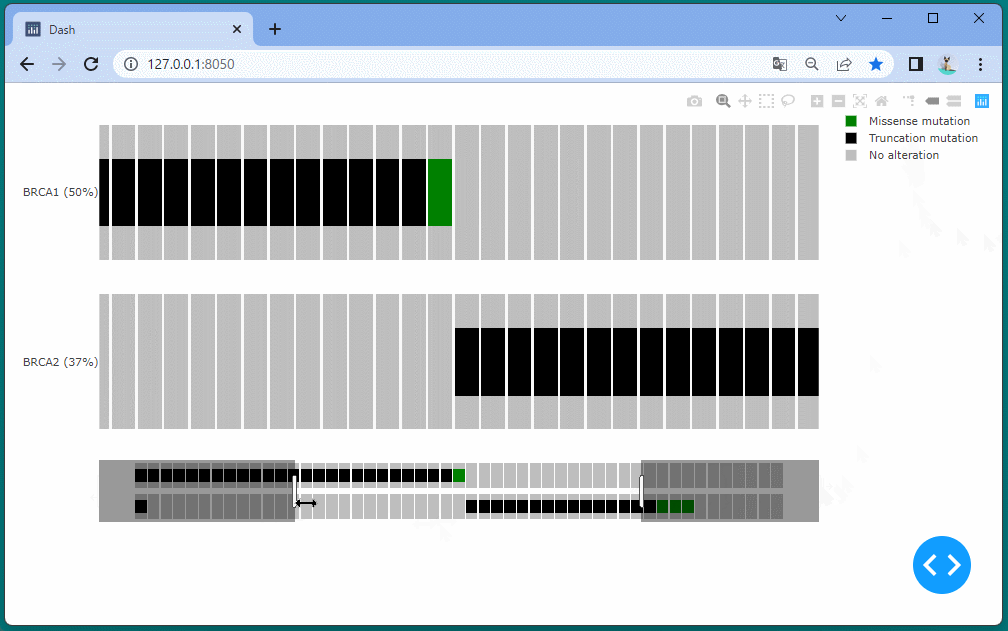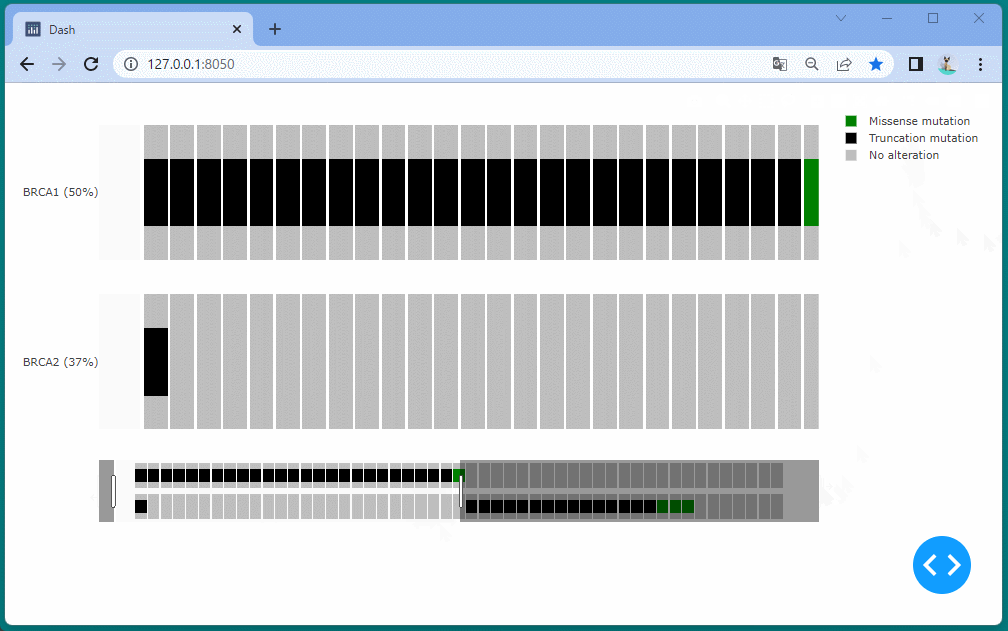
[ブラウザで表示]
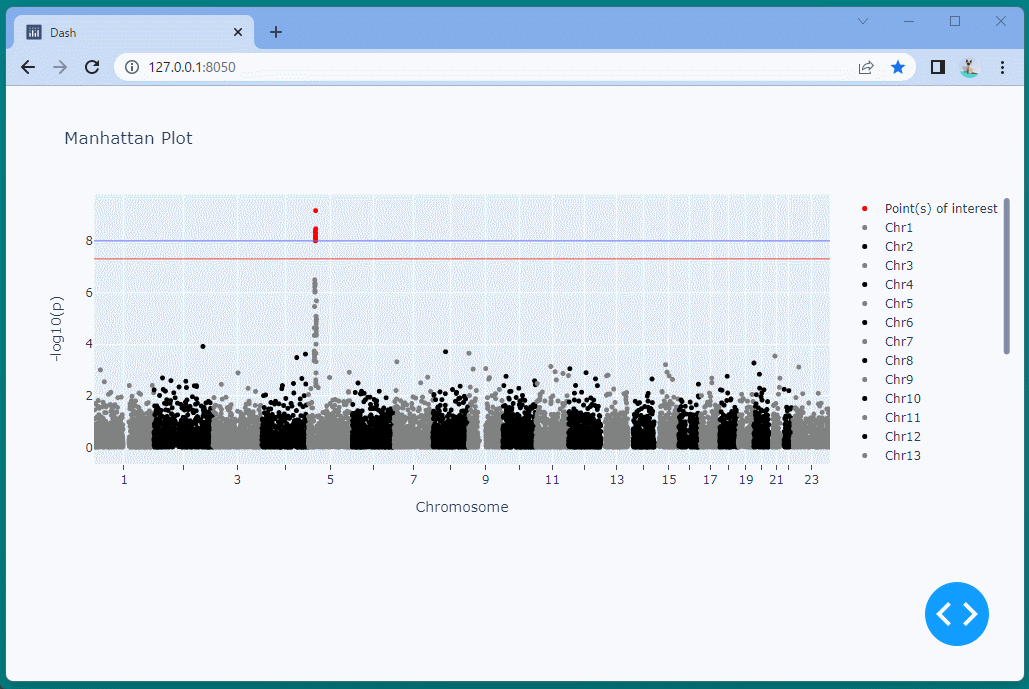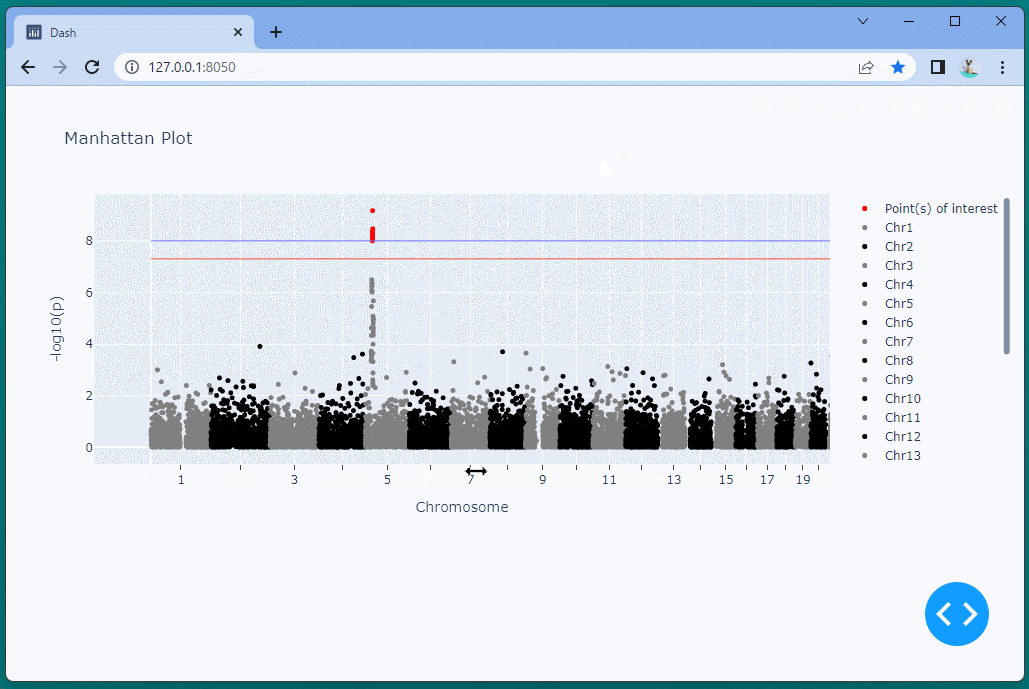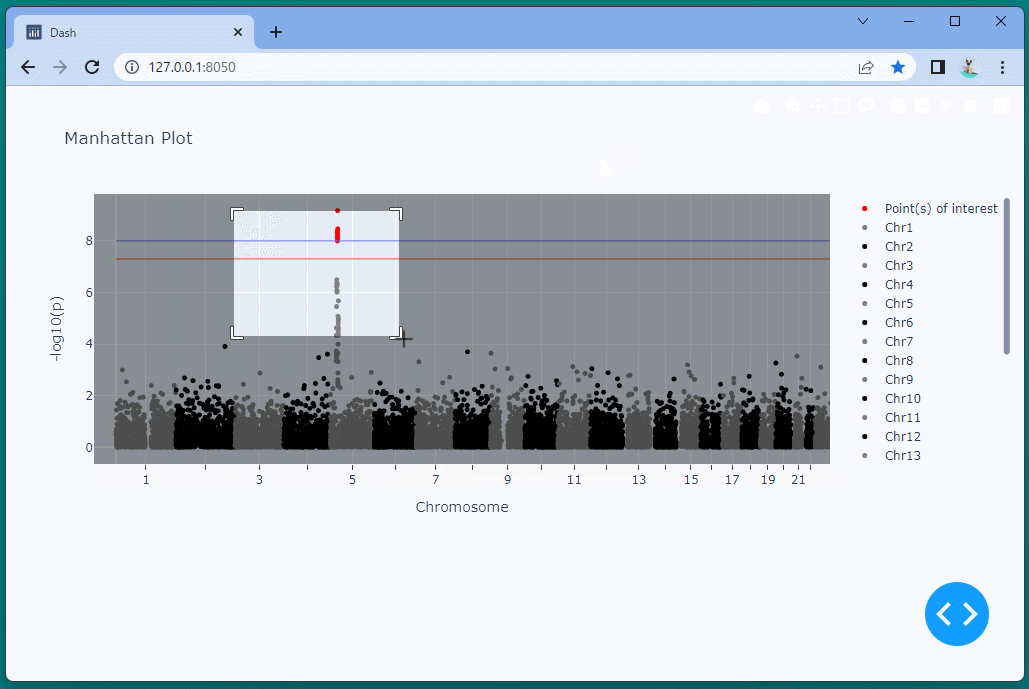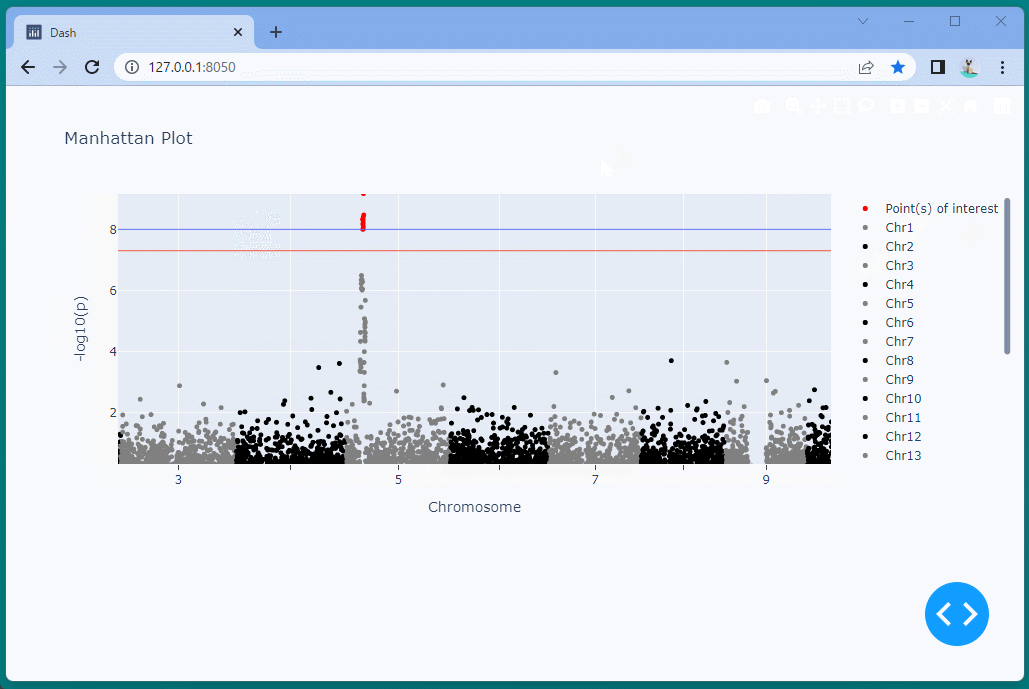
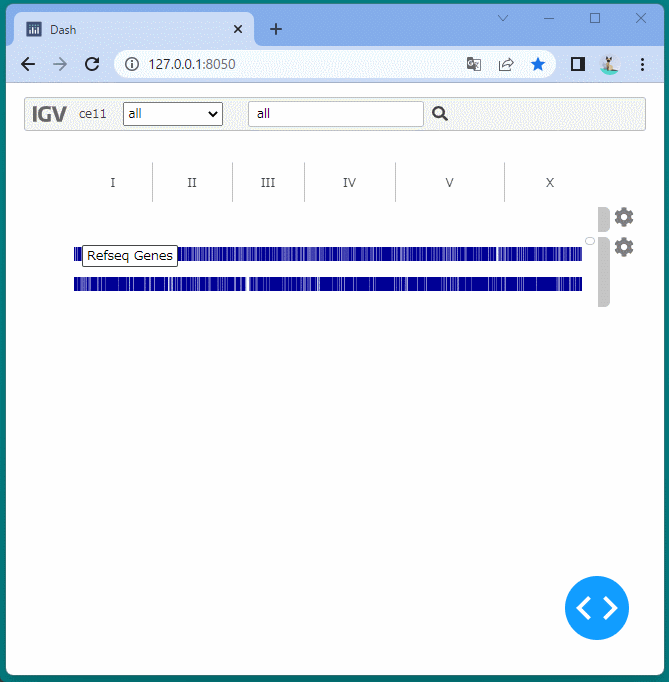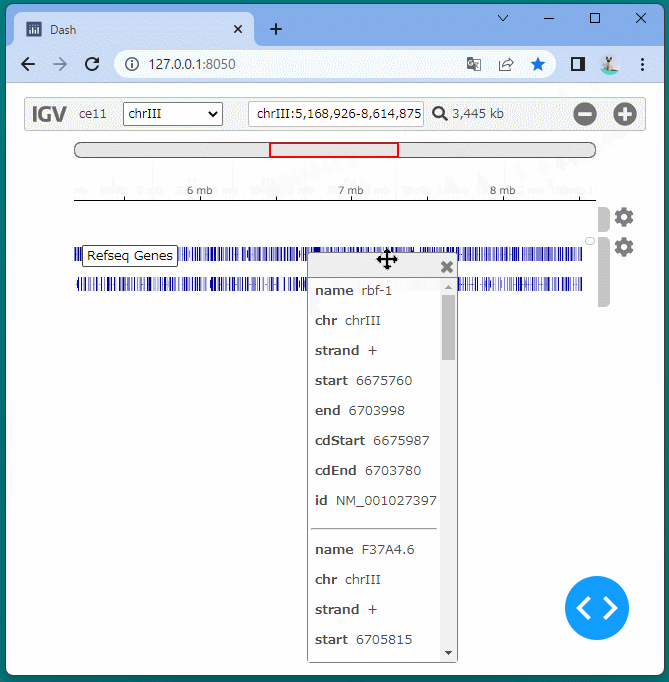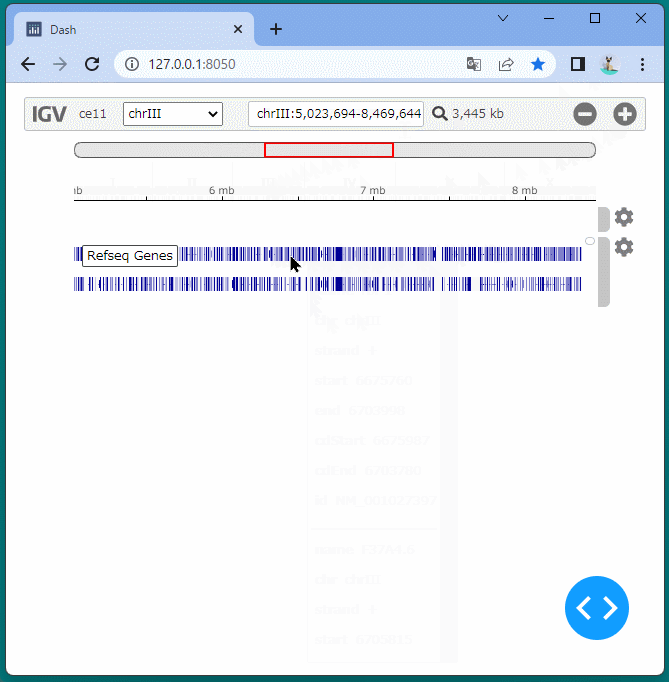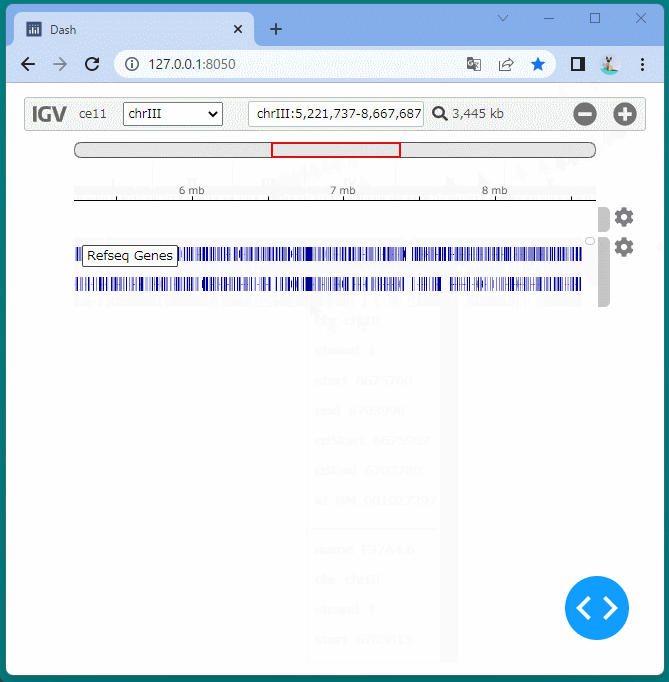
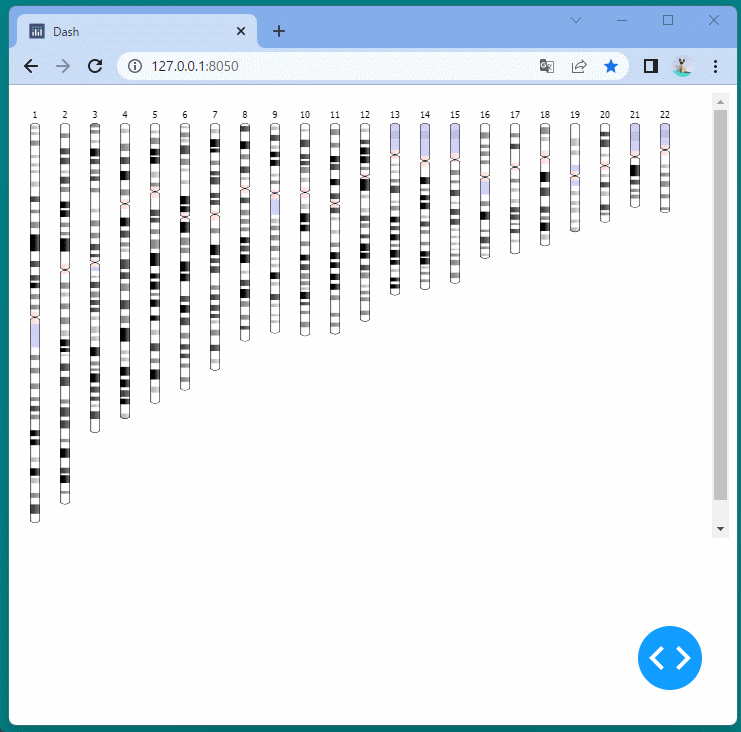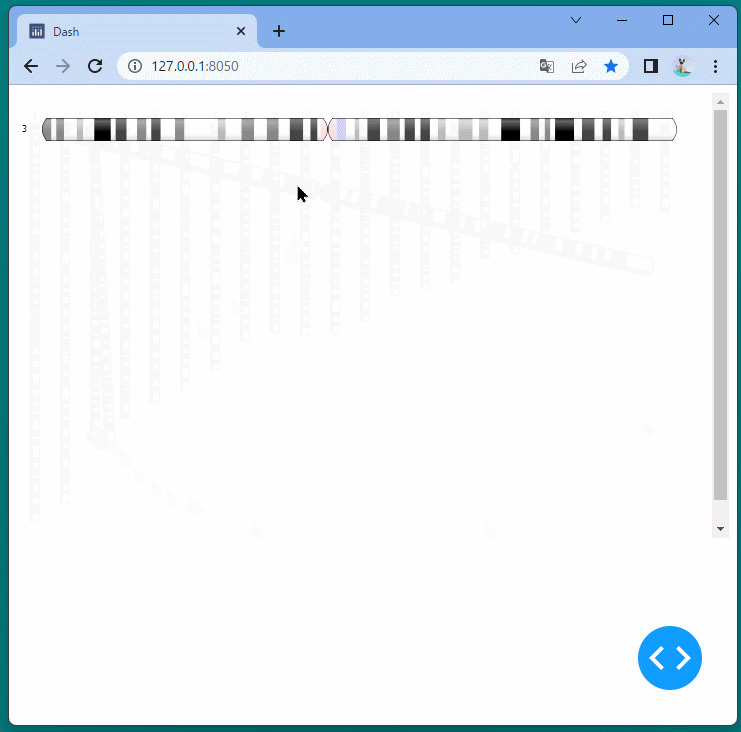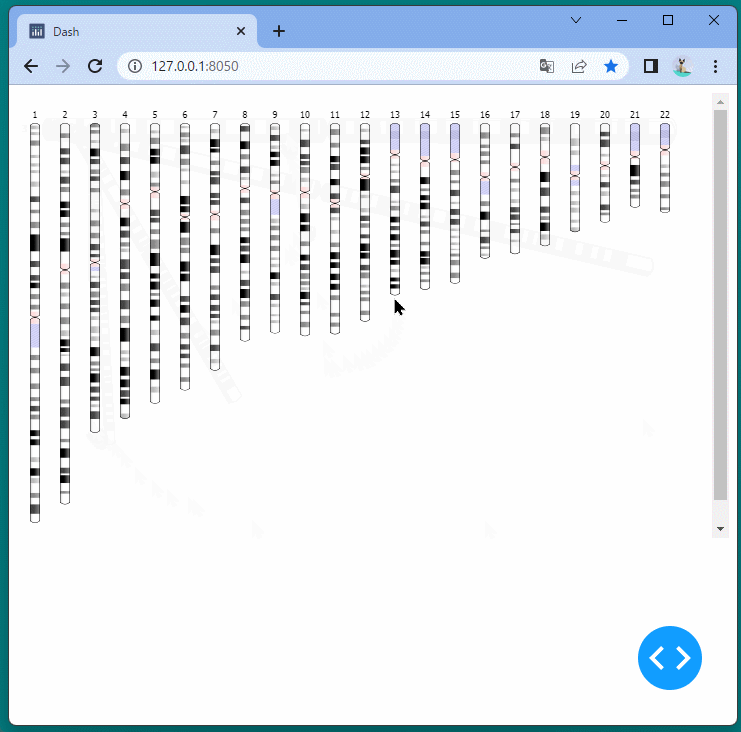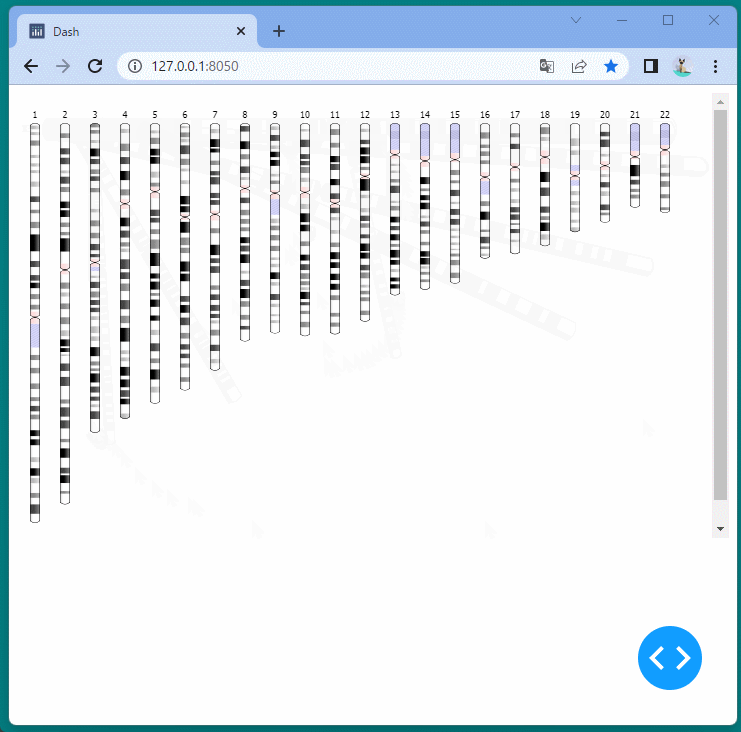
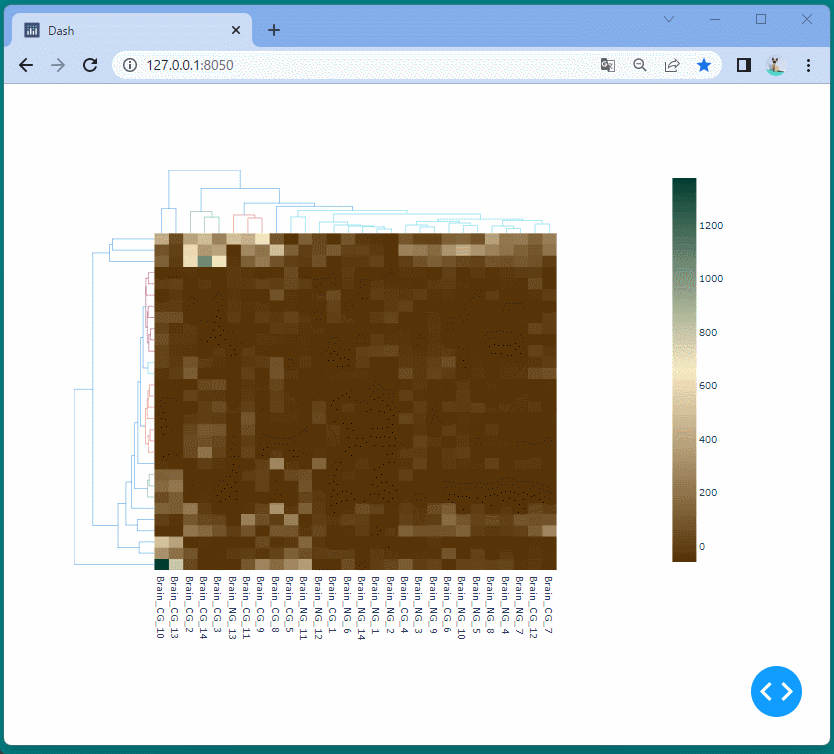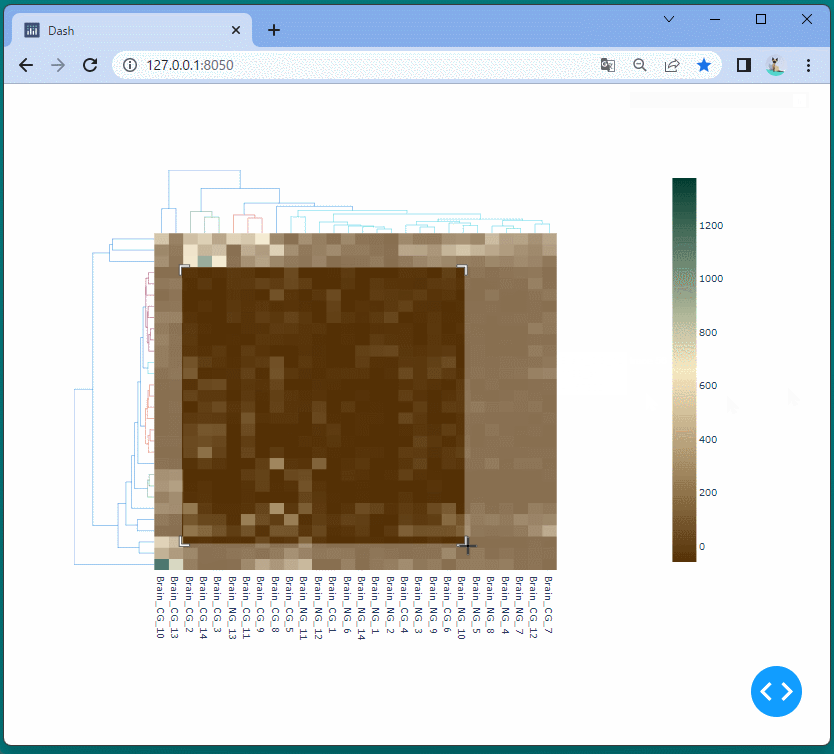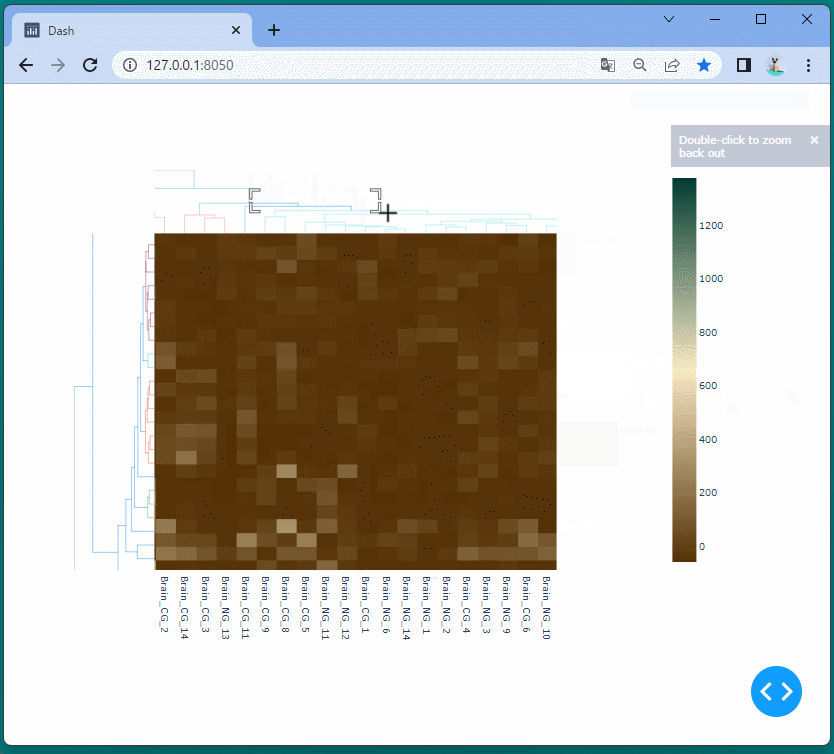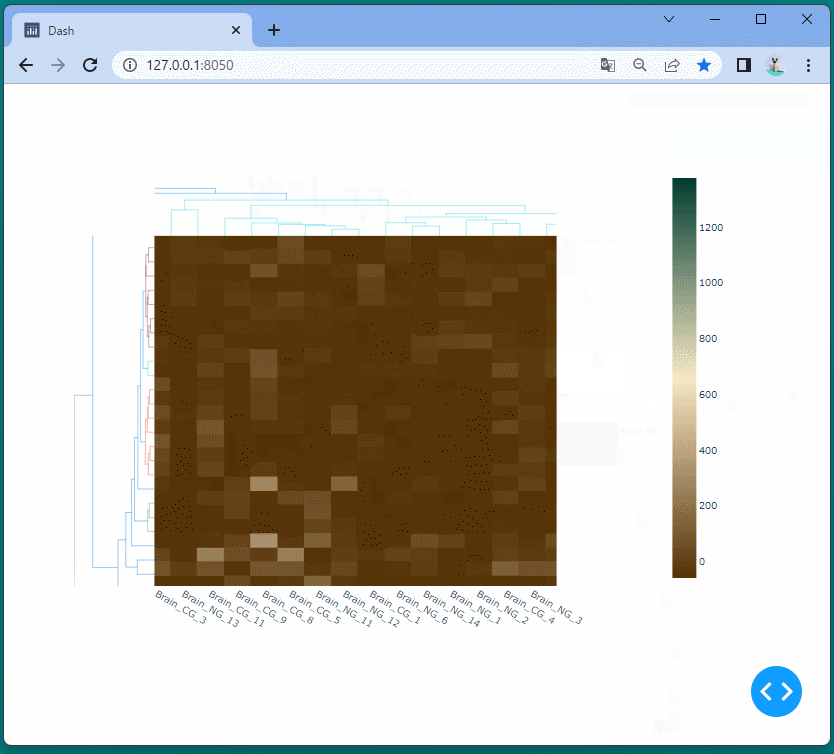
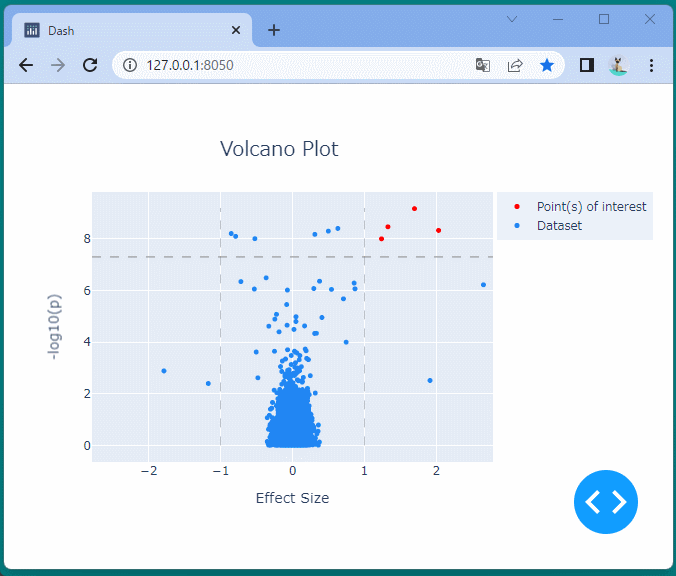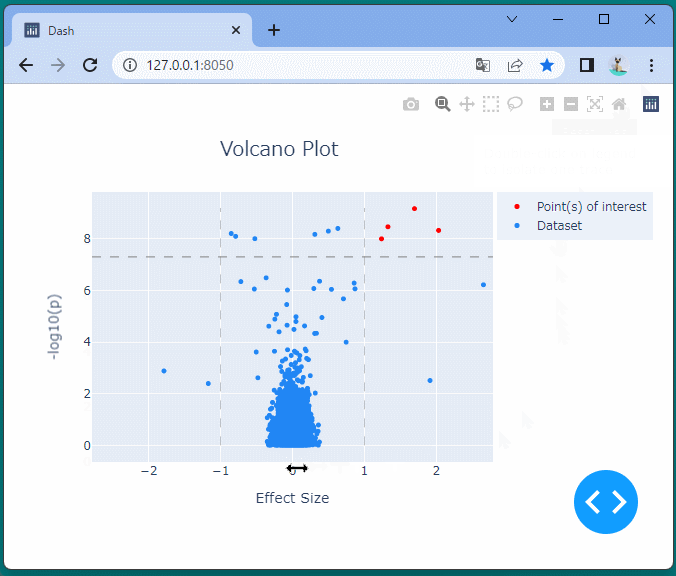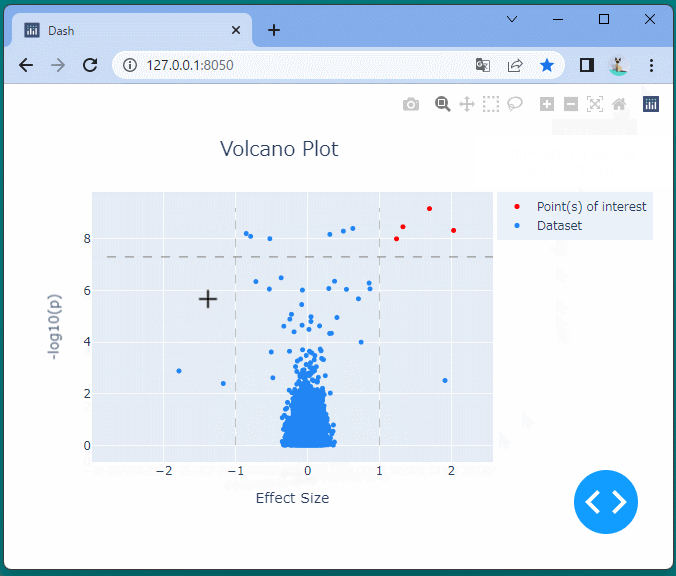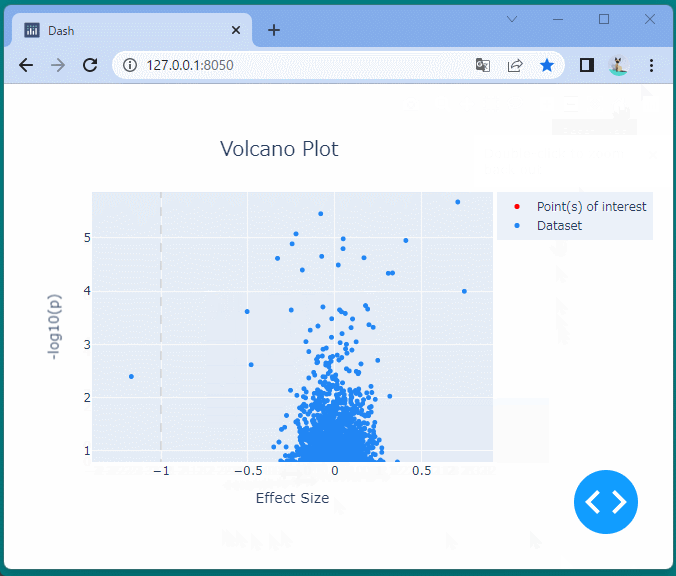
マンハッタンプロットを表示することができました。
ドラッグすることにより、表示位置を変えたり、拡大・縮小したりすることができます。
また凡例を選択して、データの表示・非表示を切り替えることもできます。