AdaBoostというアルゴリズムを使って、タイタニックの生存率を予測します。
AdaBoostはアンサンブル学習のブースティングに分類されるアルゴリズムの1つです。
AdaBoostでは、難易度の高いデータを正しく分類できる弱仮説器の分類結果を重視するよう、弱仮説器に対して重みを付けます。
AdaBoostは分類精度が高いですが、学習データのノイズに影響を受けやすい傾向があります。
データの読み込み
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けます。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
# データ前処理
def preprocessing(df):
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
|
AdaBoostで予測
AdaBoostのインスタンスを生成し、cross_val_score関数で分割交差検証を行い、どのくらいの正答率になるか調べてみます。
[ソース]
1
2
3
4
5
6
| from sklearn import ensemble, model_selection
clf = ensemble.AdaBoostClassifier()
score = model_selection.cross_val_score(clf, x_titanic, y_titanic, cv=4) # cv=4は4分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[出力]

68.23%という、これまで試してきた他のアルゴリズムよりも低めの正解率となりました。
Kaggleに提出
訓練データ全体で学習を行います。
その後、検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 学習
clf.fit(x_titanic, y_titanic)
# 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
# df_test.isnull().sum()
pre = clf.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
result.to_csv('result0309.csv', index=False)
|
[提出結果]
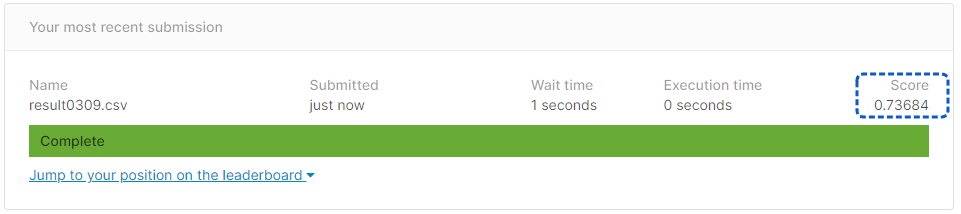
正解率73.68%となりました。
AdaBoostアルゴリズはノイズに弱いという話でしたが、もう少し前処理でノイズの除去をする必要があるのかもしれません。