名前に含まれる敬称は社会経済的地位に関する情報となりえる可能性があるような気がします。
そこで今回は名前に含まれる敬称(Mr. Mrs. Miss.など)を抽出し、カテゴリパラメータとして追加してみます。
名前に含まれる敬称抽出
名前から敬称を抽出しTitle項目として追加しています。
同じ敬称の個数が10に満たない場合は’etc’とひとまとめにしました。
[ソース]
1
2
3
4
5
6
| # expand=True ⇒ 複数の列に分割してpandas.DataFrameとして取得
df_train['Title'] = df_train['Name'].str.split(', ', expand=True)[1].str.split('.', expand=True)[0]
title_names = df_train['Title'].value_counts() < 10
df_train['Title'] = df_train['Title'].apply(lambda x: 'etc' if title_names.loc[x] == True else x)
df_train
|
[出力]
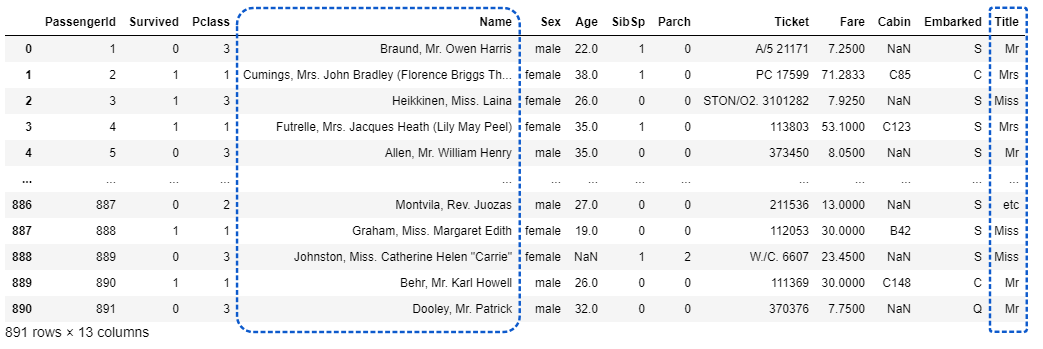
名前から敬称がきちんと抽出できていることが分かります。
各敬称の個数を表示すると下記のようになります。
[ソース]
1
| df_train.groupby('Title')['Title'].count()
|
[出力]
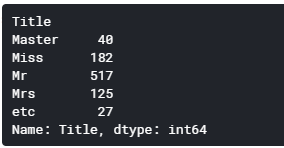
メジャーな敬称が問題なく抽出されていると思います。
データの読み込みとデータクレンジング改善5
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けます。
データクレンジングの改善5として、名前から敬称を抽出しカテゴリパラメータとしています。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
# データ前処理
def preprocessing(df):
df['Deck'] = df['Cabin'].apply(lambda s:s[0] if pd.notnull(s) else 'M') # 改善2
df['Title'] = df['Name'].str.split(', ', expand=True)[1].str.split('.', expand=True)[0] # 改善5
title_names = df['Title'].value_counts() < 10 # 改善5
df['Title'] = df['Title'].apply(lambda x: 'etc' if title_names.loc[x] == True else x) # 改善5
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
df['Age'] = df.groupby(['Pclass', 'Sex'])['Age'].apply(lambda x: x.fillna(x.median())) # 改善1
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
df['Fare'] = pd.qcut(df['Fare'], 10, labels=False) # 改善3
df['Age'] = pd.cut(df['Age'], 10, labels=False) # 改善4
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked', 'Deck', 'Title']) # 改善2、5
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
|
Random Forest分割交差検証
Random Forestのインスタンスを作成し、cross_val_score関数で分割交差検証を行い、どのくらいの正解率になるか調べてみます。
[ソース]
1
2
3
4
5
6
7
8
| from sklearn import ensemble, model_selection
clf = ensemble.RandomForestClassifier()
score = model_selection.cross_val_score(clf, x_titanic, y_titanic, cv=4) # cv=4は4分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[出力]

正解率は80.25%となりました。
Kaggleに提出
訓練データ全体で学習を行います。
その後、検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 学習
clf.fit(x_titanic, y_titanic)
# 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
df_test['Deck_T'] = 0
pre = clf.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
result.to_csv('result0314.csv', index=False)
|
[提出結果]
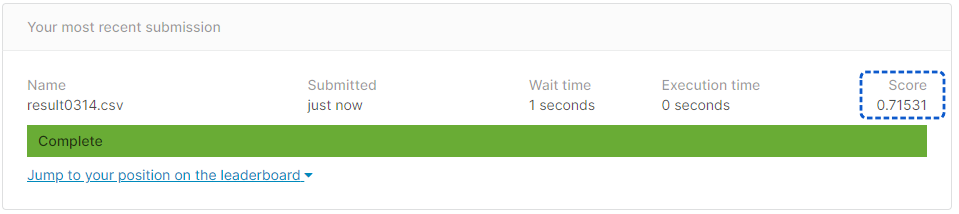
正解率71.53%となりました。
・・・だいぶ正解率が落ちてしまいました。敬称は生存率には影響しないのかもしれません。