「同一のチケット番号だと一緒に旅行していることの指標となり、チケットの重複数と生存率には関係がある」という記事を見かけました。
今回はチケットの重複数をパラメータ化してタイタニックの生存予測を行います。
チケットの重複数をチェック
チケットの重複数をTicketFrequency項目として追加、重複数ごとに平均生存率を表示します。
[ソース]
1
2
3
4
5
6
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
df_train['TicketFrequency'] = df_train.groupby('Ticket')['Ticket'].transform('count')
df_train[['TicketFrequency', 'Survived']].groupby('TicketFrequency').mean()
|
[出力]
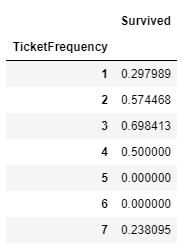
次にチケットの重複数ごとの平均生存率をグラフ化します。
[ソース]
1
| df_train[['TicketFrequency', 'Survived']].groupby('TicketFrequency').mean().plot(kind='bar', figsize=(10,6))
|
[出力]
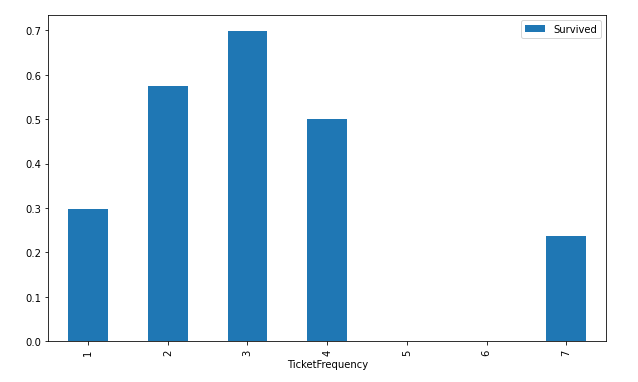
チケット重複が2から3の場合は、生存率が高いように見受けられます。
データの読み込みとデータクレンジング改善6
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けます。
データクレンジングの改善6として、チケットの重複数をパラメータとして追加しています。(8行目)
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
# データ前処理
def preprocessing(df):
df['Deck'] = df['Cabin'].apply(lambda s:s[0] if pd.notnull(s) else 'M') # 改善2
df['TicketFrequency'] = df.groupby('Ticket')['Ticket'].transform('count') # 改善6
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
df['Age'] = df.groupby(['Pclass', 'Sex'])['Age'].apply(lambda x: x.fillna(x.median())) # 改善1
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
df['Fare'] = pd.qcut(df['Fare'], 10, labels=False) # 改善3
df['Age'] = pd.cut(df['Age'], 10, labels=False) # 改善4
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked', 'Deck']) # 改善2
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
# x_titanic.isnull().sum()
x_titanic
|
[出力]
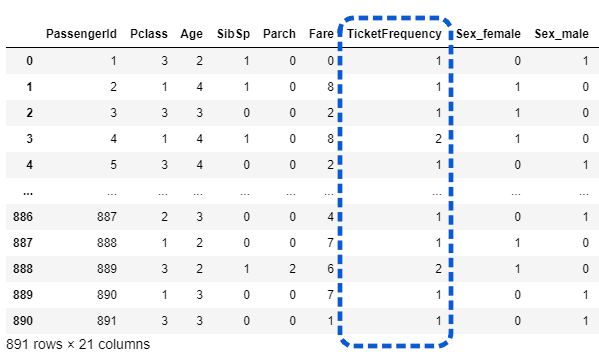
チケットの重複数としてTicketFrequencyが追加されていることが確認できます。
Random Forest分割交差検証
Random Forestのインスタンスを作成し、cross_val_score関数で分割交差検証を行い、どのくらいの正解率になるか調べてみます。
実行するたびに微妙に正解率が違うことに気づいたので、5回ほど連続実行しています。
[ソース]
1
2
3
4
5
6
7
| from sklearn import ensemble, model_selection
clf = ensemble.RandomForestClassifier()
for _ in range(5):
score = model_selection.cross_val_score(clf, x_titanic, y_titanic, cv=4) # cv=4は4分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[出力]
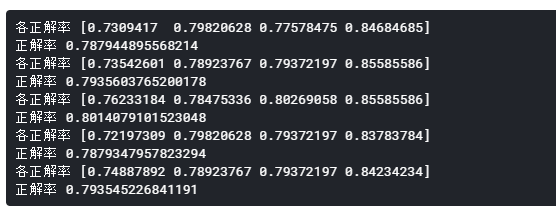
正解率は78%~80%となりました。
Kaggleに提出
訓練データ全体で学習を行います。
その後、検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 学習
clf.fit(x_titanic, y_titanic)
# 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
df_test['Deck_T'] = 0
pre = clf.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
result.to_csv('result0315.csv', index=False)
|
[提出結果]
正解率76.55%となりました。正解率あげるのってホントに難しいんですね。
パラメータの追加・削除だけではなくて他の切り口でいく必要があると感じ始めています。