タイタニック生存予測の精度を上げるためにあらたな分析方法を探していたところ興味深い記事を見つけました。
それは欠損値がない完全なデータ(Pclass, Sex, SibSp, Parch)を使って、ランダムフォレストで年齢(Age)の欠損値を推定するというものです。
ランダムフォレストで年齢の欠損値を推定
ランダムフォレストで年齢の欠損値を推定する手順は下記の通りです。
- 推定に使用する項目を抽出
- ラベル特徴量をワンホットエンコーディング
- 学習データ(年齢データのあるもの)とテストデータ(年齢データが欠損値)に分離し、numpyに変換
- 学習データをX(年齢), y(それ以外)に分離
- ランダムフォレストで推定モデルを構築
- 推定モデルを使って、テストデータの年齢(Age)を予測し、補完
最後に年齢ごとの生存率と死亡率をグラフ化しています。
[ソース]
1 | import pandas as pd |
[出力]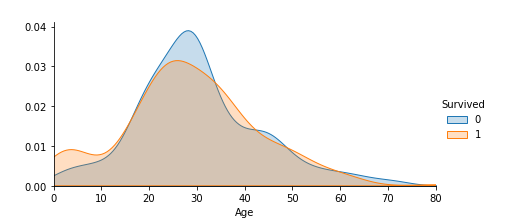
年齢(Age)の欠損値補完をした結果をグラフにしたのが上の図になります。
10歳未満の場合は生存率が上回っていて、20~30歳の場合は死亡率が上回っていることが確認できます。