以前名前に含まれる敬称(Mr. Mrs. Miss.など)をパラメータ化しましたが、今回はもう少し名前に関する特徴量に関して深堀りしていきたいと思います。
敬称を抽出しグループ化
名前(Name)から敬称(Title)を抽出し、グループ化します。
Officerは乗船員で、Royaltyは王族、貴族といった意味合いです。
Jonkheerはオランダ語で貴族という意味になります。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
| import pandas as pd
import seaborn as sns
df = pd.read_csv('/kaggle/input/titanic/train.csv')
# Nameから敬称(Title)を抽出し、グルーピング
df['Title'] = df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona', 'Jonkheer'], 'Royalty', inplace=True)
df['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['Title'].replace(['Mlle'], 'Miss', inplace=True)
sns.barplot(x='Title', y='Survived', data=df, palette='Set2')
|
[出力]
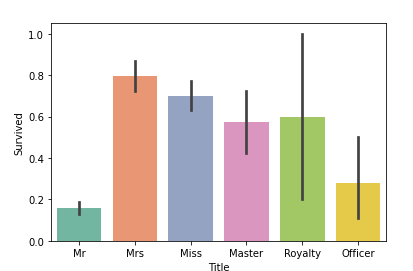
Mrの生存率が一番低く、Mrsの生存率が一番高いことが分かります。
Royalyt(貴族)の生存率も70%を超えていますね。さすがです(?)
同じ苗字のグループ化
名前から苗字を取り出しグループ化します。
家族がいた場合に生存率に影響があったのではないかという視点になります。
[ソース]
1
2
3
4
5
| # NameからSurname(苗字)を抽出
df['Surname'] = df['Name'].map(lambda name:name.split(',')[0].strip())
# 同じSurname(苗字)の出現頻度をカウント(出現回数が2以上なら家族)
df['FamilyGroup'] = df['Surname'].map(df['Surname'].value_counts())
|
家族を16才以下または女性というグループにすると面白い事実が見えてきます。
[ソース]
1
2
3
4
| # 家族で16才以下または女性の生存率
Female_Child_Group=df.loc[(df['FamilyGroup']>=2) & ((df['Age']<=16) | (df['Sex']=='female'))]
Female_Child_Group=Female_Child_Group.groupby('Surname')['Survived'].mean()
print(Female_Child_Group.value_counts())
|
[出力]
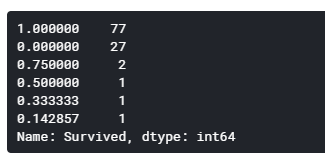
1行目の77グループでは生存率100%ですが、2行目の27グループでは生存率0%となっています。
多くのグループは全員生存しているのに、一部のグループだけ全滅しているということになります。
次に16才を超えかつ男性というグループに注目してみます。
[ソース]
1
2
3
4
| # 家族で16才超えかつ男性の生存率
Male_Adult_Group=df.loc[(df['FamilyGroup']>=2) & (df['Age']>16) & (df['Sex']=='male')]
Male_Adult_List=Male_Adult_Group.groupby('Surname')['Survived'].mean()
print(Male_Adult_List.value_counts())
|
[出力]
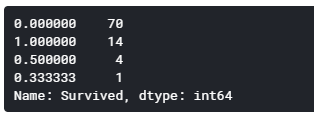
1行目の70グループは生存率0%で、2行目の14グループでは生存率100%となっています。
多くのグループは全滅しているのに、一部のグループだけ全員生存しているということになります。
上記の結果をまとめると、全体の流れとは逆の運命を辿った少数派がいるということになります。
デッドリストとサバイブリストの作成
今回の名前分析を踏まえて、次の2種類のリストを作成しテストデータに反映します。
- デッドリスト(Dead_list)
16才以下または女性のグループで全員死んだ苗字を集めたリスト
- サバイブリスト(Survived_list)
16才を超えかつ男性のグループで全員生存した苗字を集めたリスト
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
| # デッドリストとサバイブリストの作成
Dead_list=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
Survived_list=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
# デッドリストとサバイブリストの表示
print('Dead_list = ', Dead_list)
print('Survived_list = ', Survived_list)
# デッドリストとサバイブリストをSex, Age, Title に反映させる
df.loc[(df['Survived'].isnull()) & (df['Surname'].apply(lambda x:x in Dead_list)),\
['Sex','Age','Title']] = ['male',28.0,'Mr']
df.loc[(df['Survived'].isnull()) & (df['Surname'].apply(lambda x:x in Survived_list)),\
['Sex','Age','Title']] = ['female',5.0,'Mrs']
|
[出力]

テストデータの中で、デッドリストに該当した行(乗客)の場合は、必ず死亡と判断されるようにSex, Age, Titleを典型的な死亡データに書き換え、サバイブリストに該当した行がある場合は、必ず生存と判断されるように Sex, Age, Titleを典型的な生存データに書き換えています。
次回はこのデッドリストとサバイブリストの判定を踏まえて、タイタニック生存予測を行いたいと思います。