前2回の記事で行ったデータクレンジング処理を踏まえてタイタニックコンペに提出します。
改善内容は以下の通りです。
- ランダムフォレストで年齢の欠損値を推定。
- 名前(Name)から特徴量抽出し、デッドリストとサバイブリストを作成し、テストデータに反映。
年齢の欠損値を推定する処理を関数化
ランダムフォレストで年齢の欠損値を推定する処理を関数化します。
[ソース]
1 | def age_trans(df): |
年齢の欠損値を推定する処理を関数デッドリストとサバイブリストを作成
名前(Name)から特徴量抽出し、デッドリストとサバイブリストを作成する処理を関数化します。
[ソース]
1 | def make_list(df): |
デッドリストに該当した行(乗客)の場合は、必ず死亡と判断されるようにSex, Age, Titleを典型的な死亡データに書き換え、サバイブリストに該当した行がある場合は、必ず生存と判断されるように Sex, Age, Titleを典型的な生存データに書き換える処理を関数化します。
[ソース]
1 | def trans_by_list(df): |
データの読み込みとデータクレンジング改善
Kaggleに準備されているタイタニックの訓練データを読み込み、デッドリストとサバイブリストを作成しておきます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けます。
データの前処理の中では、ランダムフォレストで年齢の欠損値を推定する処理age_trans)とデッドリストとサバイブリストを作成する処理(trans_by_list)をコールしています。
[ソース]
1 | import pandas as pd |
Random Forest分割交差検証
Random Forestのインスタンスを作成し、cross_val_score関数で分割交差検証を行い、どのくらいの正解率になるか調べてみます。
[ソース]
1 | from sklearn import ensemble, model_selection |
[出力]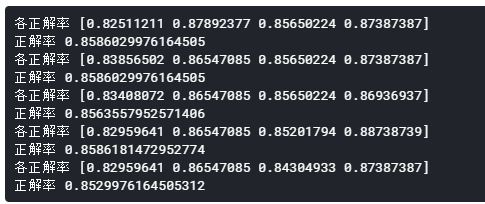
正解率は全て85%台となりました。
これまでにない高正解率だったので早速Kaggleに提出しようとしたのですが、提出処理に戸惑ってしまったので、明日の記事に持ち越します。すいません。。。