欠測値が多いため列ごと削除していたCabinですが、先頭のアルファベットが船の階層を表しているとの情報を見つけました。
Aが船の一番上の階層で、Gが一番下の階層とのことです。
船の階層ごとの生存率チェック
船の上の方にいる方が救命ボートまでの距離が近くて、生存率が高いはずです。
この仮説をデータをチェックして確認したいと思います。
Cabinの頭文字を取得しDeckとして新しい列を追加します。欠損値の場合はとりあえず’M’を仮設定しました。
[ソース]
1
2
3
4
5
6
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
df_train['Deck'] = df_train['Cabin'].apply(lambda s:s[0] if pd.notnull(s) else 'M')
df_train
|
[出力]
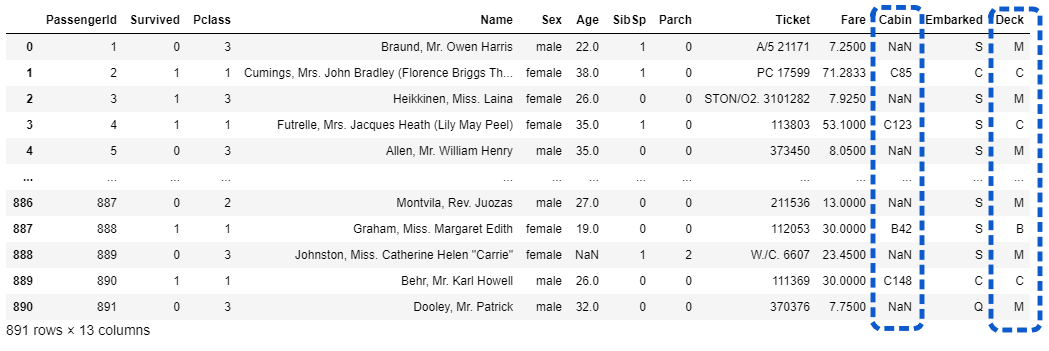
問題なくDeckのデータが設定されていることが確認できます。
次にDeckでグループ化して、平均生存率を棒グラフで表示します。
[ソース]
1
| df_train.groupby('Deck')['Survived'].mean().plot(kind='bar', figsize=(10,6))
|
[出力]
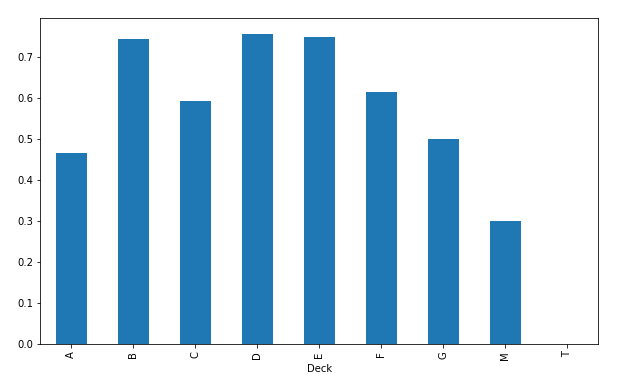
上の階層ほど生存率が高く、下の階層ほど生存率が低いという結果を期待していたのですが、そういう感じの結果にはなりませんでした。
ただ、これまで欠損値として扱っていたパラメータ(Cabin)を分析パラメータとして変換できたので、この修正を踏まえてKaggleに提出しておきます。
データの読み込みとデータクレンジング改善2
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けます。
CabinをDeckに変換する処理も追加しておきます。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
# データ前処理
def preprocessing(df):
df['Deck'] = df['Cabin'].apply(lambda s:s[0] if pd.notnull(s) else 'M') # 改善2
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
df['Age'] = df.groupby(['Pclass', 'Sex'])['Age'].apply(lambda x: x.fillna(x.median())) # 改善1
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked', 'Deck']) # 改善2
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
|
Random Forestのインスタンスを作成し、cross_val_score関数で分割交差検証を行い、どのくらいの正解率になるか調べてみます。
[ソース]
1
2
3
4
5
6
| from sklearn import ensemble, model_selection
clf = ensemble.RandomForestClassifier()
score = model_selection.cross_val_score(clf, x_titanic, y_titanic, cv=4) # cv=4は4分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[出力]

81.93%という、まずまずの正解率となりました。
Kaggleに提出
訓練データ全体で学習を行います。
その後、検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 学習
clf.fit(x_titanic, y_titanic)
# 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
df_test['Deck_T'] = 0
pre = clf.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
result.to_csv('result0311.csv', index=False)
|
[提出結果]
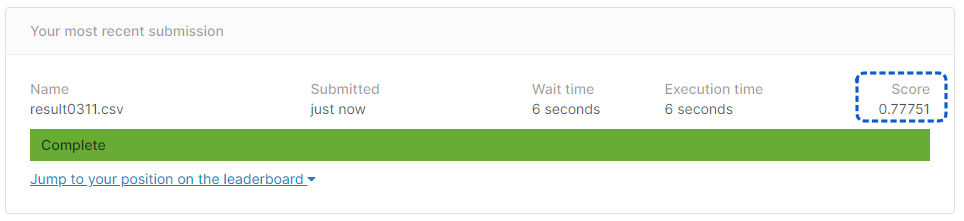
正解率77.51%となりました。
悪くはない正解率だとは思いますが、なんとか8割以上の結果を出したいものです。