いろいろなアルゴリズムを使ってタイタニックの生存予測を行ってきましたが、正解率が上がらなくなってきたので今回からはデータクレンジングを改善していきたいと思います。
予測アルゴリズムとしてはRandom Forestの成績が一番よかったのでこれを使います。
データの読み込みとデータクレンジング改善1
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けます。
年齢の欠損値にはこれまで一律でデータ全体の中央値を設定してきましたが、これを改善します。
年齢の中央値は乗客クラスによって異なるという論文があり、具体的には次のような点があげられていました。
- 社会経済的地位の高い人は平均して年配
- 性別でみると女性の方が若い
上記を踏まえて、乗客クラスと性別にグループ分けして、それぞれの中央値を年齢の欠損値に設定します(12行目)
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
# データ前処理
def preprocessing(df):
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
#df['Age'] = df['Age'].fillna(df['Age'].median())
df['Age'] = df.groupby(['Pclass', 'Sex'])['Age'].apply(lambda x: x.fillna(x.median())) # 改善1
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked'])
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
|
Random Forestで予測
Random Forestのインスタンスを作成し、cross_val_score関数で分割交差検証を行い、どのくらいの正解率になるか調べてみます。
[ソース]
1
2
3
4
5
| from sklearn import ensemble, model_selection
clf = ensemble.RandomForestClassifier()
score = model_selection.cross_val_score(clf, x_titanic, y_titanic, cv=4) # cv=4は4分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[出力]

81.59%という、まずまずの正解率となりました。
Kaggleに提出
訓練データ全体で学習を行います。
その後、検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 学習
clf.fit(x_titanic, y_titanic)
# 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
# 予測
pre = clf.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
result.to_csv('result0310.csv', index=False)
|
[提出結果]
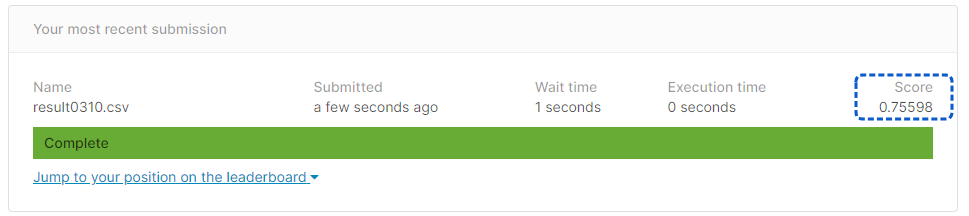
正解率75.59%となりました。
・・・正解率が下がってしまったような気がしますが、あきらめず引き続きデータクレンジングの改善を行っていきます。

