Fraud Detection in Financial Networks using NetworkX
Problem Statement: In financial networks, fraud detection involves identifying unusual patterns of transactions or interactions between different entities (like bank accounts or individuals).
These patterns often deviate from normal behavior and can signal fraudulent activity such as money laundering, unauthorized transfers, or suspicious account activities.
In this example, we will build a financial transaction network where nodes represent entities (e.g., accounts), and edges represent transactions between them.
We will use anomaly detection techniques based on network properties such as transaction volume, degree centrality, and clustering to identify potentially fraudulent nodes.
Problem Setup
We have a network of financial transactions between different accounts. Each transaction is represented by an edge, and its amount is recorded as a weight on the edge.
Our goal is to:
Identify suspicious accounts based on abnormal transaction volumes or unusually high connectivity.
Detect suspicious clusters of transactions that may indicate fraud rings (i.e., groups of accounts working together for illegal purposes).
Highlight anomalies using graph metrics like betweenness centrality, degree centrality, and transaction flow patterns.
Example Transaction Network
Let’s create a financial network with accounts and transactions between them.
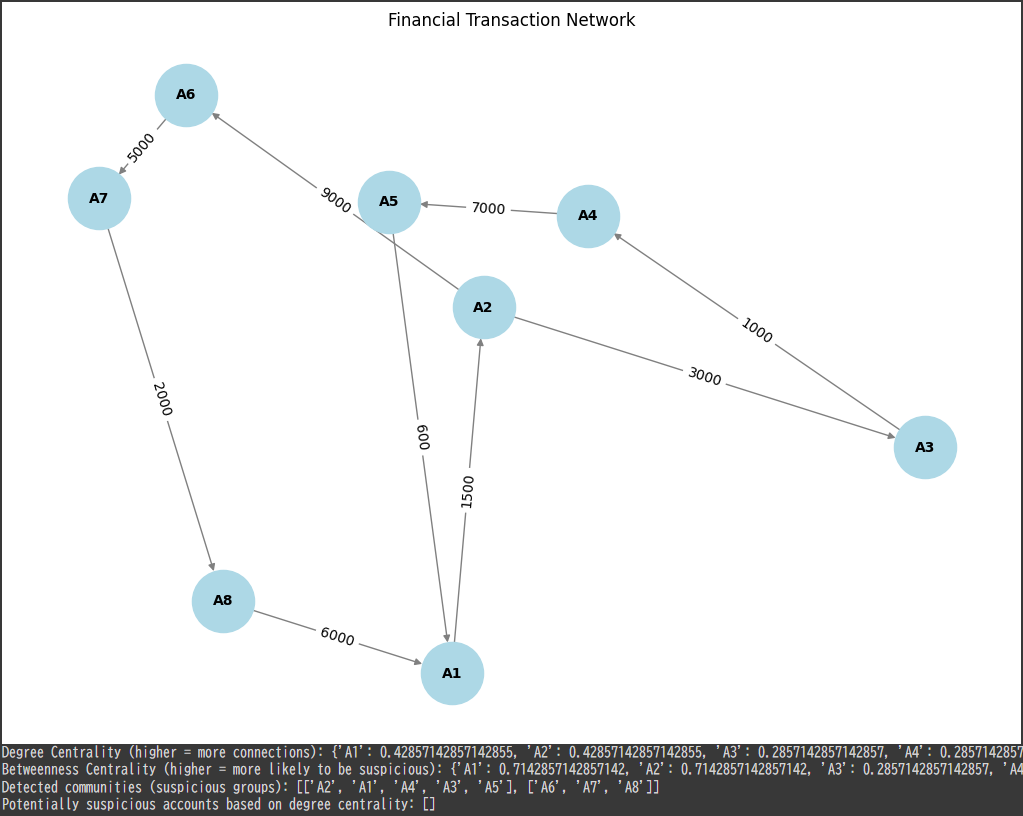
# Analyze betweenness centrality to find accounts with high transaction traffic passing through betweenness_centrality = nx.betweenness_centrality(G, weight='weight') print("Betweenness Centrality (higher = more likely to be suspicious):", betweenness_centrality)
# Detect communities (clusters of accounts) using greedy modularity communities = nx.community.greedy_modularity_communities(G) community_list = [list(c) for c in communities] print("Detected communities (suspicious groups):", community_list)
# Highlight suspicious accounts based on threshold (e.g., degree centrality > 0.5) suspicious_accounts = [node for node, centrality in degree_centrality.items() if centrality > 0.5] print("Potentially suspicious accounts based on degree centrality:", suspicious_accounts)
Explanation of the Code
Graph Representation:
The financial network is modeled as a directed graph using nx.DiGraph(). Each node represents an account, and each edge represents a financial transaction between two accounts. The edge weight represents the transaction amount.
We added transactions between the accounts and assigned specific amounts to each transaction.
Visualizing the Network:
The financial transaction network is plotted, with nodes representing accounts and edges representing transactions. The weights on the edges (shown as labels) indicate the amount of money transferred.
Centrality Analysis:
Degree Centrality is used to identify nodes with a large number of connections. Accounts with higher degree centrality (either sending or receiving a lot of transactions) may be considered suspicious.
Betweenness Centrality measures how often a node appears on the shortest path between other nodes. Nodes with high betweenness centrality are considered critical for the flow of transactions and might be hubs in a fraud ring.
Community Detection:
Greedy Modularity Community Detection is used to find groups of nodes (accounts) that are closely interconnected. These communities might represent clusters of accounts collaborating in fraudulent activities.
Anomaly Detection:
Accounts that have high degree centrality (e.g., > $0.5$) or high betweenness centrality are flagged as potentially suspicious. These accounts are highly active or serve as intermediaries in suspicious transactions.
Example Output
The results show the following insights from the financial network analysis:
Degree Centrality: Accounts A1 and A2 have the highest degree centrality ($0.43$), meaning they are more connected to other accounts and involved in more transactions compared to other nodes.
Betweenness Centrality: Accounts A1 and A2 also have the highest betweenness centrality ($0.71$), indicating that they act as intermediaries for many transactions, potentially linking different parts of the network.
Detected Communities: The accounts were split into two groups. The first group, which includes A1, A2, A3, A4, and A5, may represent a cluster of closely interacting accounts. The second group consists of A6, A7, and A8, forming another cluster.
Suspicious Accounts: No accounts were flagged based on degree centrality, as none exceeded a predefined threshold for suspicious connectivity.
In summary, while no specific accounts were flagged as suspicious based on degree centrality, accounts A1 and A2 are key players in the network with significant connections and high transaction flow.
The detected communities could indicate potential collaboration or coordinated activity between the accounts in each group.
Real-World Relevance of Fraud Detection in Financial Networks
Money Laundering Detection: Accounts with unusually high connectivity or transactions passing through multiple accounts are often involved in money laundering schemes.
Transaction Monitoring: Banks and financial institutions use such network-based techniques to monitor and detect suspicious patterns in real time.
Fraud Rings: Community detection helps in identifying fraud rings where multiple accounts work together to conduct fraudulent transactions.
Conclusion
This example demonstrates how NetworkX can be used for fraud detection in financial networks by analyzing transaction patterns, centrality measures, and community structures.
By identifying suspicious accounts and transaction routes, we can flag potentially fraudulent activities for further investigation.
Supply Chain Optimization with Multiple Products and Routes
In this version of Supply Chain Optimization, we focus on a more complex network where different products are transported from multiple suppliers to customers through various warehouses.
The goal is to minimize the transportation costs and meet customer demands while considering different routes and the availability of each product.
Problem Definition
Consider a supply chain network with:
Suppliers: Provide two types of products (Product A and Product B).
Warehouses: Store both types of products and distribute them to retailers.
Retailers: Require a specific amount of each product to meet customer demand.
Supply Chain Layout
Suppliers:
Supplier 1 (S1) provides Product A.
Supplier 2 (S2) provides Product B.
Warehouses:
Warehouse 1 (W1)
Warehouse 2 (W2)
Retailers:
Retailer 1 (R1) requires both Product A and Product B.
Retailer 2 (R2) requires both Product A and Product B.
Objective:
Model the supply chain network with multiple products and multiple routes as a directed graph.
Minimize the transportation cost from suppliers to retailers while meeting the demands for each product.
import networkx as nx import matplotlib.pyplot as plt
# Create a directed graph for the supply chain network G = nx.DiGraph()
# Define demands for Product A and Product B at the retailers demands = { 'R1_A': 15, # Retailer 1 demands 15 units of Product A 'R1_B': 10, # Retailer 1 demands 10 units of Product B 'R2_A': 10, # Retailer 2 demands 10 units of Product A 'R2_B': 20# Retailer 2 demands 20 units of Product B }
# Add edges with capacities (max units of goods that can be transported) and costs (weights) # Supplier 1 supplies Product A to warehouses G.add_edge('S1_A', 'W1_A', capacity=20, weight=5) # From Supplier 1 to Warehouse 1 for Product A G.add_edge('S1_A', 'W2_A', capacity=15, weight=7) # From Supplier 1 to Warehouse 2 for Product A
# Supplier 2 supplies Product B to warehouses G.add_edge('S2_B', 'W1_B', capacity=25, weight=4) # From Supplier 2 to Warehouse 1 for Product B G.add_edge('S2_B', 'W2_B', capacity=10, weight=6) # From Supplier 2 to Warehouse 2 for Product B
# Warehouses distribute Product A and B to retailers G.add_edge('W1_A', 'R1_A', capacity=20, weight=3) # Product A from Warehouse 1 to Retailer 1 G.add_edge('W1_B', 'R1_B', capacity=10, weight=3) # Product B from Warehouse 1 to Retailer 1 G.add_edge('W2_A', 'R2_A', capacity=10, weight=4) # Product A from Warehouse 2 to Retailer 2 G.add_edge('W2_B', 'R2_B', capacity=20, weight=5) # Product B from Warehouse 2 to Retailer 2
# Add super source (SS) and super sink (TS) for combining the flows of Product A and B G.add_edge('SS', 'S1_A', capacity=20) G.add_edge('SS', 'S2_B', capacity=25) G.add_edge('R1_A', 'TS', capacity=15) # Retailer 1 requires 15 units of Product A G.add_edge('R1_B', 'TS', capacity=10) # Retailer 1 requires 10 units of Product B G.add_edge('R2_A', 'TS', capacity=10) # Retailer 2 requires 10 units of Product A G.add_edge('R2_B', 'TS', capacity=20) # Retailer 2 requires 20 units of Product B
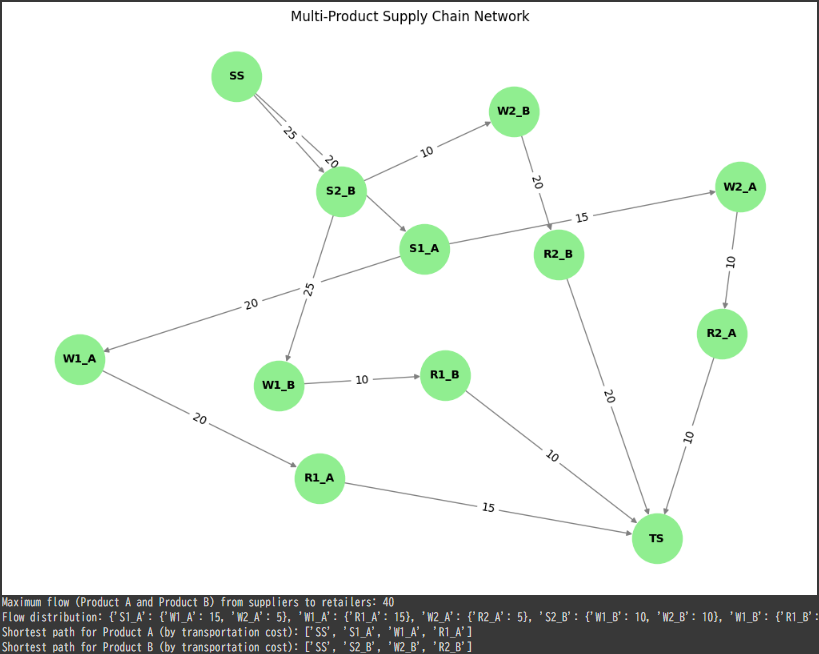
# Compute maximum flow from super source to super sink flow_value, flow_dict = nx.maximum_flow(G, 'SS', 'TS') print("Maximum flow (Product A and Product B) from suppliers to retailers:", flow_value) print("Flow distribution:", flow_dict)
# Shortest path by transportation cost (for cost minimization) shortest_path_A = nx.shortest_path(G, source='SS', target='R1_A', weight='weight') shortest_path_B = nx.shortest_path(G, source='SS', target='R2_B', weight='weight') print("Shortest path for Product A (by transportation cost):", shortest_path_A) print("Shortest path for Product B (by transportation cost):", shortest_path_B)
Explanation of the Code
Graph Construction:
We represent the supply chain as a directed graph. The products (Product A and Product B) are treated separately, and the nodes and edges are labeled accordingly.
Each edge has two attributes: capacity (maximum units of product that can be transported) and weight (cost of transportation).
Super Source and Sink:
We add a super source node (“SS”) to represent both suppliers and a super sink node (“TS”) to represent both retailers.
This setup helps combine the flow of both products (Product A and Product B) for analysis.
Maximum Flow Calculation:
The maximum flow algorithm calculates the maximum amount of both products that can be transported through the supply chain while respecting capacity constraints.
Shortest Path Calculation:
The shortest path algorithm (minimizing the transportation cost) calculates the least expensive transportation route for both Product A and Product B from suppliers to retailers.
Explanation of Results
Supply Chain Network Visualization:
The network shows how products are routed from suppliers to retailers via warehouses. The capacity labels on the edges represent how many units of each product can be transported along each route.
Maximum Flow:
The maximum flow result gives the total amount of Product A and Product B that can be transported from suppliers to retailers while considering warehouse capacities.
The result also includes a flow dictionary that shows how much of each product is transported along each edge.
Example Output:
1 2
Maximum flow (Product A and Product B) from suppliers to retailers: 40 Flow distribution: {'S1_A': {'W1_A': 15, 'W2_A': 5}, 'W1_A': {'R1_A': 15}, 'W2_A': {'R2_A': 5}, 'S2_B': {'W1_B': 10, 'W2_B': 10}, 'W1_B': {'R1_B': 10}, 'W2_B': {'R2_B': 10}, 'R1_A': {'TS': 15}, 'R1_B': {'TS': 10}, 'R2_A': {'TS': 5}, 'R2_B': {'TS': 10}, 'SS': {'S1_A': 20, 'S2_B': 20}, 'TS': {}}
Shortest Path (by cost):
The shortest path for each product indicates the least expensive routes to transport Product A and Product B to their respective retailers.
Example Output:
1 2
Shortest path for Product A (by transportation cost): ['SS', 'S1_A', 'W1_A', 'R1_A'] Shortest path for Product B (by transportation cost): ['SS', 'S2_B', 'W2_B', 'R2_B']
Supply Chain Optimization Relevance
Maximum Flow Analysis: Helps to understand how efficiently both products (Product A and Product B) can be transported through the supply chain to meet the demands of both retailers.
Cost Minimization: The shortest path analysis provides the optimal route for minimizing transportation costs for each product, allowing businesses to operate more cost-effectively.
Product Separation: By modeling different products separately, businesses can better allocate resources and optimize individual product flows across the supply chain.
Conclusion
This example illustrates how NetworkX can be used for Supply Chain Optimization involving multiple products and transportation routes.
The code efficiently models the supply chain, computes the maximum flow of goods, and identifies the most cost-effective transportation routes.
In Social Network Analysis (SNA), we examine how individuals (nodes) are connected to each other via social relationships (edges).
These connections may represent friendships, collaborations, or communication links between people.
The goal of the analysis is to identify key individuals, communities, and understand the structure of the network.
Problem Definition
We are given a simple social network where:
Nodes represent individuals (users).
Edges represent friendships or interactions between these individuals.
Objective:
Build a social network graph representing individuals and their connections.
Calculate centrality measures to identify the most influential individuals in the network.
Detect communities (groups of tightly connected individuals).
Visualize the social network using NetworkX.
Social Network Layout:
User A is friends with User B, User C, and User D.
User B is also friends with User C.
User C is friends with User D and User E.
User D is friends with User F.
User E is friends with User F and User G.
Approach
We’ll use NetworkX to model this social network and perform analysis, such as calculating centrality, community detection, and shortest paths between users.
# Visualize the social network plt.figure(figsize=(8, 6)) pos = nx.spring_layout(G) # Position nodes using a force-directed layout nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=2000, font_size=12, font_weight='bold') plt.title("Social Network Graph") plt.show()
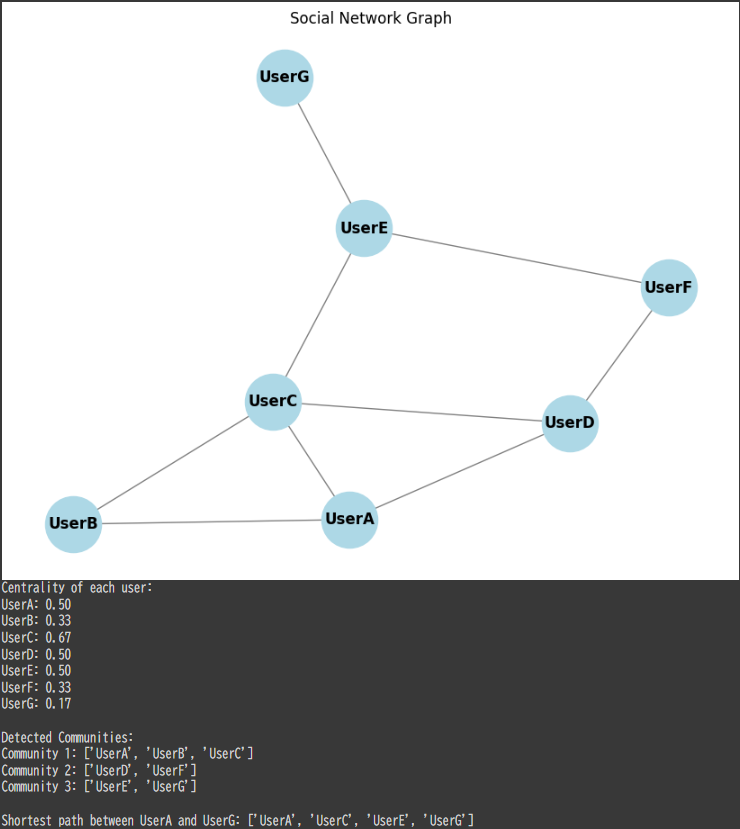
# Calculate centrality (degree centrality: importance based on number of connections) centrality = nx.degree_centrality(G) print("Centrality of each user:") for user, centrality_value in centrality.items(): print(f"{user}: {centrality_value:.2f}")
# Identify communities using a simple modularity-based method from networkx.algorithms.community import greedy_modularity_communities communities = list(greedy_modularity_communities(G))
# Display detected communities print("\nDetected Communities:") for i, community inenumerate(communities): print(f"Community {i+1}: {sorted(community)}")
# Shortest path between UserA and UserG shortest_path = nx.shortest_path(G, source='UserA', target='UserG') print(f"\nShortest path between UserA and UserG: {shortest_path}")
Explanation of the Code
Graph Construction:
We represent each user as a node and each friendship as an edge between two users. This graph is undirected since friendships are mutual.
Visualization:
We use a force-directed layout (spring_layout) to position the nodes, which spreads them out naturally, and visualize the connections between users.
Centrality Calculation:
Degree centrality is calculated to determine which users have the most connections (i.e., who are the most “influential” in terms of direct friendships).
Community Detection:
We use modularity-based community detection (greedy_modularity_communities) to identify groups of users that are more closely connected to each other than to other users. This helps in understanding sub-groups or clusters within the network.
Shortest Path Calculation:
The shortest path between two users (UserA and UserG) is computed using NetworkX’s shortest_path function. This shows the minimal number of steps required to connect one user to another, which can represent the minimum number of interactions or connections needed for information to travel between them.
Explanation of Results
Social Network Visualization:
The graph shows how different users are connected, visually representing the structure of the social network.
Centrality of Each User:
Degree centrality measures the number of direct connections each user has:
Users like UserC will have higher centrality because they are directly connected to more users (hence, more influential).
Users like UserG will have lower centrality, as they are connected to fewer users.
Example Output:
1 2 3 4 5 6 7 8
Centrality of each user: UserA: 0.50 UserB: 0.33 UserC: 0.67 UserD: 0.50 UserE: 0.50 UserF: 0.33 UserG: 0.17
Community Detection:
The detected communities represent groups of users who are more tightly connected. For example:
One community might be: ['UserA', 'UserB', 'UserC'].
Another community might be: ['UserD', 'UserF'].
Example Output:
1 2 3 4
Detected Communities: Community 1: ['UserA', 'UserB', 'UserC'] Community 2: ['UserD', 'UserF'] Community 3: ['UserE', 'UserG']
Shortest Path:
The shortest path between UserA and UserG represents the minimal number of connections needed to “reach” UserG from UserA. This is useful for understanding how information or influence could spread in the network.
Example Output:
1
Shortest path between UserA and UserG: ['UserA', 'UserC', 'UserE', 'UserG']
Social Network Analysis Relevance
Centrality helps identify key individuals who can influence the network, such as community leaders or highly connected individuals.
Community Detection reveals subgroups or clusters of individuals, which may represent teams, friend groups, or any other cohesive social unit.
Shortest Path analysis helps in understanding how quickly information (or influence) can propagate across the network.
Conclusion
This example demonstrates how to use NetworkX to perform Social Network Analysis ($SNA$).
The code covers essential aspects such as network visualization, centrality calculations, community detection, and shortest path analysis.
These tools are critical for understanding social structures and identifying key individuals or groups in a network.
In Electrical Circuit Analysis, components such as resistors, capacitors, and inductors are connected in a network to control the flow of electrical current.
This network can be modeled using a graph, where the nodes represent connection points (or junctions), and the edges represent the components (resistors, capacitors, etc.) between the junctions.
Problem Definition
We are given a simple circuit with the following components and connections:
Nodes represent junctions where multiple components are connected.
Edges represent electrical components (resistors) with specified resistance values.
Objective:
Build a circuit graph where nodes represent junctions and edges represent resistors.
Calculate the equivalent resistance between two points using series and parallel combinations of resistors.
Visualize the circuit using $NetworkX$.
Circuit Layout:
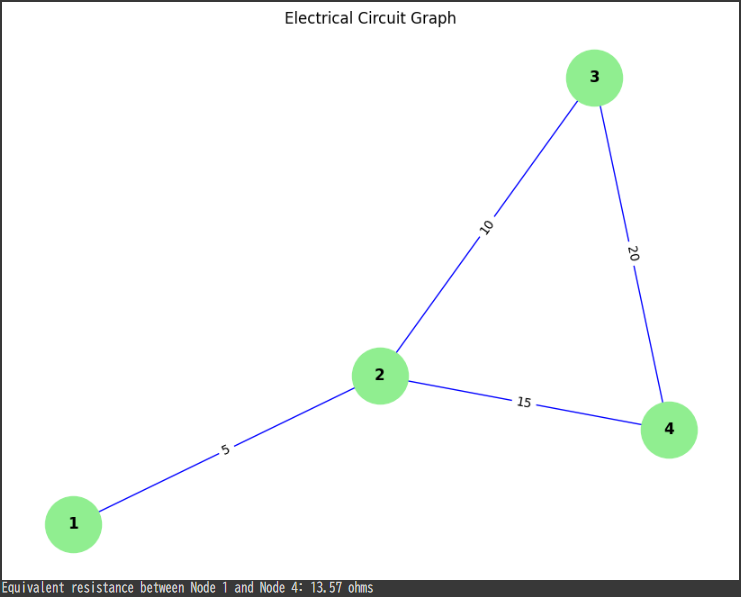
Node $1$ connects to Node $2$ through a $5$-ohm resistor.
Node $2$ connects to Node $3$ through a $10$-ohm resistor.
Node $3$ connects to Node $4$ through a $20$-ohm resistor.
Node $2$ connects to Node $4$ through a parallel path with a $15$-ohm resistor.
Approach
We’ll use $NetworkX$ to model this electrical circuit and calculate the equivalent resistance between Node $1$ and Node $4$.
# Calculate the equivalent resistance using series and parallel rules # Helper function to compute equivalent resistance in parallel defparallel_resistance(*resistances): return1 / sum(1 / r for r in resistances)
# Step-by-step calculation of the equivalent resistance R_23 = G[2][3]['resistance'] # Resistor between Node 2 and 3 (10 ohms) R_34 = G[3][4]['resistance'] # Resistor between Node 3 and 4 (20 ohms) R_24 = G[2][4]['resistance'] # Resistor between Node 2 and 4 (15 ohms)
# Resistors R_34 and R_24 are in parallel R_parallel = parallel_resistance(R_34, R_24)
# The equivalent resistance from Node 1 to Node 4 is the series combination R_12 = G[1][2]['resistance'] # Resistor between Node 1 and 2 (5 ohms) R_eq = R_12 + R_parallel # Series combination
# Output the equivalent resistance print(f"Equivalent resistance between Node 1 and Node 4: {R_eq:.2f} ohms")
Explanation of the Code
Graph Construction:
Each node represents a junction in the circuit.
Each edge represents a resistor, with the resistance stored as an edge attribute.
Visualization:
We use nx.spring_layout() to visually represent the circuit graph, showing the connections between nodes and labeling each edge with its resistance value.
Resistance Calculations:
For resistors in series, the total resistance is the sum of individual resistances.
For resistors in parallel, we use the formula $( R_{eq} = \frac{1}{\frac{1}{R_1} + \frac{1}{R_2} + \dots} )$.
In this case, the resistors between Nodes $2$ and $4$ ($20$ ohms and $15$ ohms) are in parallel, so we calculate their equivalent resistance first, then add it to the resistance between Nodes $1$ and $2$ ($5$ ohms) to get the total resistance.
Explanation of Results
The visualization shows the circuit with its components labeled by resistance values.
The equivalent resistance is calculated step by step:
The parallel combination of the $20$-ohm and $15$-ohm resistors gives: $$ R_{parallel} = \frac{1}{\frac{1}{20} + \frac{1}{15}} \approx 8.57 , \text{ohms} $$
The total resistance between Node $1$ and Node $4$ is: $$ R_{eq} = 5 , \text{ohms (series with the parallel combination)} + 8.57 , \text{ohms} = 13.57 , \text{ohms} $$
Therefore, the equivalent resistance between Node 1 and Node 4 is approximately 13.57 ohms.
Example Output
Electrical Relevance
In real-world electrical circuits, it is important to calculate the equivalent resistance to determine the total current flow and the voltage distribution in the circuit.
$NetworkX$ provides an excellent tool for modeling and analyzing such circuits by treating them as graphs, where components (like resistors) can be easily analyzed for their contributions to the overall circuit behavior.
Conclusion
This example demonstrates how to use $NetworkX$ to model and analyze an electrical circuit.
The approach can be extended to more complex circuits involving capacitors, inductors, and more intricate resistor networks.
This graph-based method provides a flexible and scalable way to understand and compute circuit properties, such as equivalent resistance.
Biological Network Analysis is a powerful method used to understand the relationships and interactions among biological entities.
One common example is the Protein-Protein Interaction (PPI) Network, where proteins interact with each other to carry out various biological functions.
Problem Definition
We are given a set of proteins and their known interactions. The goal is to:
Identify important proteins (hubs) in the network.
Find clusters of proteins that work together in specific biological pathways.
Detect the shortest interaction paths between two proteins, which can indicate how quickly biological signals can propagate between them.
Approach
We will use NetworkX to:
Build a graph where nodes represent proteins, and edges represent interactions between them.
Analyze the network to find important proteins using centrality measures.
Cluster the network using community detection to find groups of proteins working together.
Find the shortest path between two proteins to understand how they communicate.
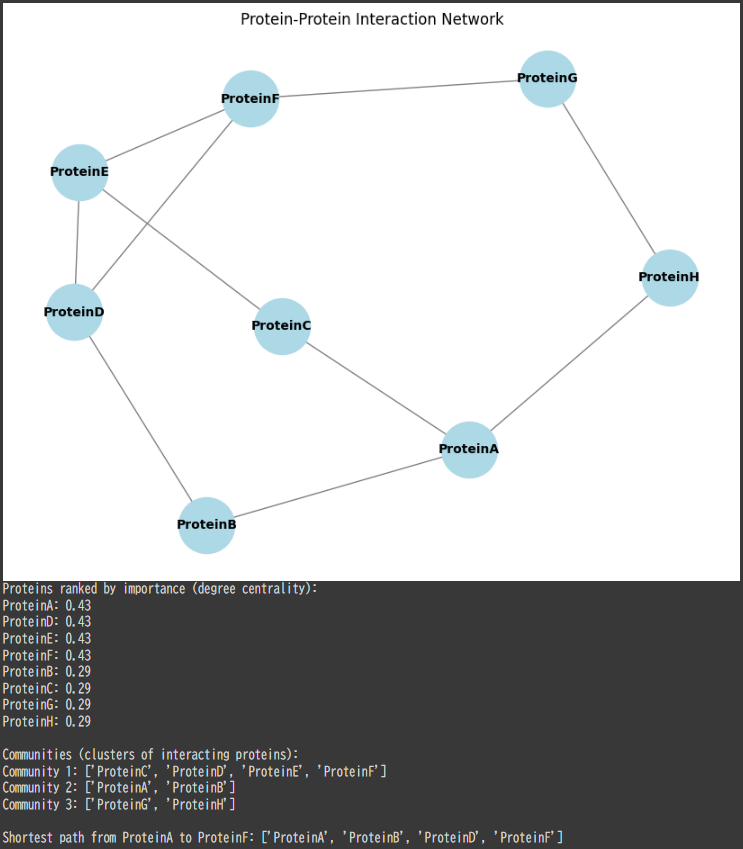
# 2. Find the most important proteins (based on degree centrality) degree_centrality = nx.degree_centrality(G) most_important_proteins = sorted(degree_centrality, key=degree_centrality.get, reverse=True) print("Proteins ranked by importance (degree centrality):") for protein in most_important_proteins: print(f"{protein}: {degree_centrality[protein]:.2f}")
# 3. Community detection (finding clusters of proteins) from networkx.algorithms.community import greedy_modularity_communities
communities = list(greedy_modularity_communities(G)) print("\nCommunities (clusters of interacting proteins):") for i, community inenumerate(communities, 1): print(f"Community {i}: {sorted(community)}")
# 4. Shortest path between two proteins protein_start = 'ProteinA' protein_end = 'ProteinF' shortest_path = nx.shortest_path(G, source=protein_start, target=protein_end) print(f"\nShortest path from {protein_start} to {protein_end}: {shortest_path}")
Explanation
Graph Construction:
We create a graph where each node represents a protein, and each edge represents an interaction between two proteins.
The edges indicate that two proteins interact and may participate in the same biological function.
Visualizing the Network:
We use $NetworkX$’s draw() function to visualize the network of proteins. This gives us a clear overview of how proteins are connected.
Proteins that are highly connected (with many edges) may play more important roles in the biological system.
Finding Important Proteins:
We compute degree centrality, which measures the number of direct connections a protein has. Proteins with higher centrality scores are likely to be hubs and may be crucial for the biological processes.
In this example, proteins like ProteinE, ProteinD, and ProteinF might be highly connected and thus important for signal transduction.
Community Detection:
Using greedy modularity communities, we group proteins into clusters. These clusters represent proteins that are more likely to be involved in the same biological processes or pathways.
For example, ProteinA, ProteinB, and ProteinC might belong to the same functional pathway.
Shortest Path Between Proteins:
We use the shortest path algorithm to find the shortest sequence of interactions between two proteins. This can represent how a biological signal propagates through the network.
For example, the shortest path from ProteinA to ProteinF might reveal how a signal passes through a series of interactions from one protein to another.
Example Output
The output shows the results of a Protein-Protein Interaction (PPI) Network Analysis using $NetworkX$. Here’s a summary of the results:
The network graph shows proteins (ProteinA, ProteinB, etc.) as nodes, and their interactions as edges (lines between nodes). This represents how different proteins interact with one another in a biological system.
2. Proteins Ranked by Importance (Degree Centrality):
The ranking of proteins is based on their degree centrality, which indicates how many other proteins they interact with:
ProteinA, ProteinD, and ProteinF have the highest centrality ($0.43$), meaning they are highly connected and likely important in the network.
ProteinB, ProteinC, ProteinG, and ProteinH have lower centrality scores ($0.29$), indicating fewer connections.
3. Communities of Interacting Proteins:
The network is divided into three clusters (or communities):
Community 1: ProteinC, ProteinD, ProteinE, ProteinF, and ProteinA, suggesting these proteins interact closely and may participate in a common biological function.
Community 2: ProteinA and ProteinB, indicating that these two proteins have a special relationship or function.
Community 3: ProteinG and ProteinH, forming another distinct interaction pair.
4. Shortest Path from ProteinA to ProteinF:
The shortest interaction path between ProteinA and ProteinF is: ['ProteinA', 'ProteinB', 'ProteinD', 'ProteinF'].
This indicates how signals or interactions might propagate through the network between these two proteins.
In conclusion, this analysis identifies important proteins, clusters of interacting proteins, and the shortest path between specific proteins, providing valuable insights into the structure and function of the biological network.
Biological Relevance
In a real-world PPI network, discovering central proteins (hubs) is crucial because they may be involved in key biological processes such as signal transduction, cellular regulation, or metabolism.
Community detection is useful for identifying groups of proteins that are likely to function together in pathways or biological modules.
Shortest path analysis helps biologists understand how proteins communicate or influence each other, which is important for designing experiments or drugs that target specific pathways.
Conclusion
This example demonstrates how to analyze a protein-protein interaction network using $NetworkX$.
The analysis helps in identifying important proteins, detecting functional clusters, and understanding the propagation of biological signals between proteins.
Such an approach is widely used in computational biology to study disease mechanisms, drug targets, and cellular functions.
Let’s create a recommendation system that suggests new products to users based on their past interactions with products and the preferences of other similar users.
This type of system can be found in e-commerce platforms like Amazon or content platforms like Netflix.
Problem Definition
Imagine a small e-commerce platform where users have purchased or liked certain products. We want to recommend new products to a user based on:
Products that similar users liked or purchased.
Products that are connected to the user through a series of recommendations or interactions.
We will model the system as a bipartite graph where:
One set of nodes represents users.
The other set of nodes represents products.
An edge between a user and a product indicates that the user has purchased or liked that product.
Objective
Our goal is to recommend new products to a user by:
Identifying users who are similar in behavior to the target user.
Finding products that the similar users have interacted with, but the target user has not yet interacted with.
Graph Model
Nodes: Users and products.
Edges: A connection between a user and a product (representing an interaction such as a purchase or a like).
Approach
We will use NetworkX to create the bipartite graph and implement a recommendation system using a simple collaborative filtering approach:
Build a bipartite graph of users and products.
Compute neighbors of the target user (users who interacted with similar products).
Recommend products that are liked by those similar users but not yet interacted with by the target user.
import networkx as nx from networkx.algorithms import bipartite
# Sample data: Users and their interactions with products (edges between users and products) user_product_interactions = [ ('User1', 'Product1'), ('User1', 'Product2'), ('User2', 'Product1'), ('User2', 'Product3'), ('User3', 'Product2'), ('User3', 'Product3'), ('User3', 'Product4'), ('User4', 'Product3'), ('User4', 'Product5'), ('User5', 'Product1'), ('User5', 'Product5'), ]
# Create a bipartite graph B = nx.Graph() # Add edges (user-product interactions) B.add_edges_from(user_product_interactions)
# Set of users and products users = {n for n in B if n.startswith('User')} products = set(B) - users
# Function to recommend products for a specific user based on similar users defrecommend_products(target_user, B, users, products): # Find the neighbors of the target user (i.e., products they interacted with) target_user_products = set(B.neighbors(target_user)) # Find users who have interacted with the same products similar_users = set() for product in target_user_products: similar_users.update(B.neighbors(product)) similar_users.discard(target_user) # Remove the target user from the list # Find products that these similar users interacted with, but the target user hasn't recommended_products = set() for similar_user in similar_users: similar_user_products = set(B.neighbors(similar_user)) recommended_products.update(similar_user_products - target_user_products) return recommended_products
print(f"Recommended products for {target_user}: {recommended_products}")
Explanation
Data Structure:
We model the system as a bipartite graph where users are connected to the products they have interacted with.
The interactions are represented as edges between the user and product nodes.
Recommendation Algorithm:
First, we find all the products that the target user has already interacted with.
Then, we identify similar users by finding those who have interacted with the same products.
Finally, we recommend the products that these similar users have interacted with but the target user has not.
Example Output
Let’s say we want to recommend products to User1. The code will output:
1
Recommended products for User1: {'Product3', 'Product5', 'Product4'}
This means that User1 hasn’t interacted with Product3, Product4, or Product5, but similar users (such as User2 and User3) have, so these products are good candidates for recommendation.
Explanation of Results
User1 has interacted with Product1 and Product2.
User2 also interacted with Product1 and liked Product3, making Product3 a candidate for recommendation.
User3 liked Product2 (which User1 also interacted with), but User3 also interacted with Product4, which could be recommended to User1.
User4 interacted with Product3 and Product5, further suggesting that Product3 and Product5 are good recommendations for User1.
Enhancements
This is a basic collaborative filtering approach. More advanced techniques can be used to:
Weight recommendations: Products that multiple similar users interacted with should have higher priority.
Use rating or feedback: If users provide ratings or reviews, this information can further refine the recommendation.
Matrix factorization: Use machine learning techniques like matrix factorization to improve recommendations by discovering latent factors.
Real-World Application
Recommendation systems like this are commonly used in:
E-commerce platforms: Amazon, Alibaba, etc., to recommend products to users based on the preferences of other users.
Streaming services: Netflix, YouTube, to suggest videos or movies based on user viewing history.
Social networks: Facebook, Twitter, to recommend friends, pages, or groups.
Conclusion
This example demonstrates how to build a basic recommendation system using $NetworkX$.
The system leverages user-product interactions to suggest new products for a given user based on the behavior of other similar users.
$NetworkX$’s ability to model and analyze complex graphs makes it a valuable tool for implementing such systems in various domains like e-commerce, social networks, and media platforms.
$( \epsilon_0 )$ is the permittivity of free space.
Problem Definition
We want to find the electric and magnetic field modes inside a rectangular cavity with perfectly conducting walls. The boundary conditions for a perfectly conducting cavity are:
The tangential electric field $( \mathbf{E}_t )$ at the walls must be zero.
The solution to Maxwell’s equations in a rectangular cavity can be written as standing wave solutions, and we are interested in finding the resonant modes (frequencies) and the corresponding field distributions.
For a rectangular cavity with dimensions $( a \times b \times d )$, the resonant frequencies $( f_{m,n,p} )$ are given by:
import numpy as np import matplotlib.pyplot as plt
# Constants c = 3.0e8# Speed of light in vacuum (m/s)
# Cavity dimensions (in meters) a = 0.1# Length in x-direction b = 0.05# Length in y-direction d = 0.02# Length in z-direction
# Function to compute the resonant frequency for a given mode (m, n, p) defresonant_frequency(m, n, p, a, b, d, c): return (c / 2) * np.sqrt((m/a)**2 + (n/b)**2 + (p/d)**2)
# Calculate resonant frequencies for a few modes (m, n, p) modes = [(1, 0, 0), (0, 1, 0), (0, 0, 1), (1, 1, 1), (2, 1, 0), (1, 2, 1)] frequencies = [resonant_frequency(m, n, p, a, b, d, c) for m, n, p in modes]
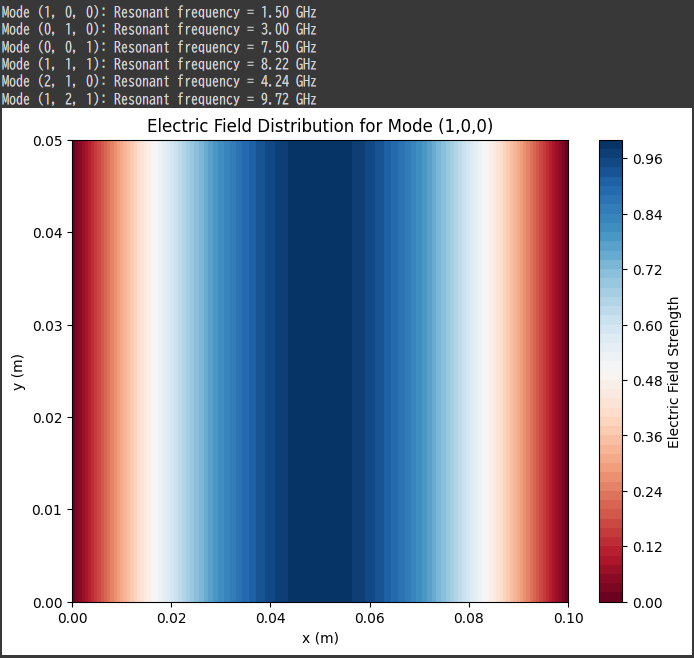
# Print the resonant frequencies for mode, freq inzip(modes, frequencies): print(f"Mode {mode}: Resonant frequency = {freq/1e9:.2f} GHz")
# Visualizing the electric field for the fundamental mode (m=1, n=0, p=0) # Assuming the electric field is sinusoidal along the x-axis x = np.linspace(0, a, 100) y = np.linspace(0, b, 100) X, Y = np.meshgrid(x, y)
# Electric field distribution for the (1,0,0) mode E_x = np.sin(np.pi * X / a)
plt.figure(figsize=(8, 6)) plt.contourf(X, Y, E_x, cmap='RdBu', levels=50) plt.colorbar(label="Electric Field Strength") plt.title("Electric Field Distribution for Mode (1,0,0)") plt.xlabel("x (m)") plt.ylabel("y (m)") plt.show()
Explanation of the Code
Resonant Frequencies:
The function resonant_frequency calculates the resonant frequency for a given mode $( (m, n, p) )$ using the formula for the rectangular cavity.
We calculate the resonant frequencies for a few different modes, including the fundamental mode $( (1, 0, 0) )$, where the field is sinusoidal along the $( x )$-axis.
Field Visualization:
For the fundamental mode $( (1, 0, 0) )$, we assume the electric field has a sinusoidal variation along the $( x )$-axis. The electric field is zero at the conducting walls.
We use matplotlib to visualize the field distribution inside the cavity.
Results
Resonant Frequencies: The output will show the resonant frequencies for various modes. These frequencies are in the GHz range, which is typical for microwave cavities.
Example output:
Electric Field Distribution: The plot shows the electric field distribution for the fundamental mode $( (1, 0, 0) )$, with a sinusoidal variation along the $( x )$-axis. The field is zero at the cavity boundaries, as expected for a mode in a perfectly conducting cavity.
Real-World Applications
Microwave Cavities: Resonant cavities are used in microwave ovens and accelerators to confine and amplify electromagnetic waves.
Waveguides: The same principles are used to design waveguides that carry electromagnetic waves over long distances with minimal loss.
Quantum Computing: Superconducting resonant cavities are critical in designing qubits for quantum computers.
Conclusion
This example demonstrates how to solve an advanced physics problem involving Maxwell’s equations for electromagnetic waves in a rectangular cavity.
Using $Python$, we computed the resonant frequencies for different modes and visualized the electric field distribution for the fundamental mode.
This method is essential for understanding and designing resonant cavities used in a wide range of practical applications, from microwave technologies to quantum devices.
Let’s tackle an optimization problem where we optimize the shape of a building to balance structural efficiency and aesthetic design using $DEAP$.
This type of problem is known as architectural form optimization and is crucial in fields like sustainable design and engineering.
Problem: Shape Optimization of a Building
The goal is to optimize the shape of a building to minimize the material cost and maximize structural efficiency, while also adhering to aesthetic constraints.
The building’s shape is represented by a set of geometric parameters, such as the dimensions of floors and curvature of the walls.
Objective
We aim to balance the following objectives:
Structural efficiency: The building must be stable, with minimal stress in critical areas.
Material cost: The total amount of building material used should be minimized.
Aesthetic constraints: The building should maintain a desired aesthetic, such as symmetry or a specified curvature.
Problem Definition
We will consider a simple tower with the following shape variables:
Height $( h )$ (ranging between $50$ to $200$ meters).
Base radius $( r_b )$ (ranging between $10$ to $50$ meters).
Top radius $( r_t )$ (ranging between $5$ to $30$ meters).
The building’s structure will be a tapering cylindrical shape, where the top radius might be smaller than the base radius. The cost function incorporates structural stress and material usage.
Total Material Volume (Cost):
The material cost is proportional to the volume of the structure:
We define structural efficiency as inversely proportional to the maximum stress in the building. The stress depends on the height, base, and top radius:
$$ S(h, r_b, r_t) = \frac{h}{r_b + r_t} $$
The objective is to minimize the material volume while maintaining structural efficiency by ensuring that the stress $( S )$ does not exceed a given threshold.
Aesthetic Constraint:
To maintain symmetry and aesthetic appeal, the base and top radii must be proportionally related, and a penalty is applied if the relationship deviates too much from a desired ratio $( r_b/r_t \approx 2 )$.
Multi-Objective Optimization:
We want to:
Minimize the material volume $( V(h, r_b, r_t) )$,
Maximize the structural efficiency $( \frac{1}{S(h, r_b, r_t)} )$,
Respect the aesthetic constraint $( \frac{r_b}{r_t} \approx 2 )$.
DEAP Implementation
We will use $DEAP$ to solve this multi-objective optimization problem.
Each individual will represent a set of parameters $( (h, r_b, r_t) )$, and $DEAP$ will evolve the population over generations to find the optimal balance between structural efficiency, material cost, and aesthetic constraints.
toolbox.register("evaluate", fitness_function) toolbox.register("mate", tools.cxBlend, alpha=0.5) toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=10, indpb=0.2) toolbox.register("select", tools.selNSGA2) # Use NSGA-II for multi-objective optimization
# Custom bounds checking function defcheckBounds(individual): for i inrange(len(individual)): if individual[i] < BOUND_LOW[i]: individual[i] = BOUND_LOW[i] elif individual[i] > BOUND_UP[i]: individual[i] = BOUND_UP[i]
# Algorithm parameters population_size = 100 generations = 200 cx_prob = 0.7# Crossover probability mut_prob = 0.2# Mutation probability
# Apply bounds after crossover and mutation defmain(): pop = toolbox.population(n=population_size) hof = tools.HallOfFame(1) # Keep track of the best individual
stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("avg", np.mean) stats.register("min", np.min) # Evolutionary algorithm with bounds checking for gen inrange(generations): offspring = toolbox.select(pop, len(pop)) offspring = list(map(toolbox.clone, offspring))
# Apply crossover and mutation for child1, child2 inzip(offspring[::2], offspring[1::2]): if random.random() < cx_prob: toolbox.mate(child1, child2) checkBounds(child1) checkBounds(child2) del child1.fitness.values del child2.fitness.values
for mutant in offspring: if random.random() < mut_prob: toolbox.mutate(mutant) checkBounds(mutant) del mutant.fitness.values
# Evaluate individuals with invalid fitness invalid_ind = [ind for ind in offspring ifnot ind.fitness.valid] fitnesses = map(toolbox.evaluate, invalid_ind) for ind, fit inzip(invalid_ind, fitnesses): ind.fitness.values = fit
# Replace the old population with offspring pop[:] = offspring
# Gather and print statistics hof.update(pop) record = stats.compile(pop) print(f"Generation {gen}: {record}")
# Output the best solution best_ind = hof[0] print(f"Best individual (h, r_b, r_t): {best_ind}") print(f"Best fitness (volume, -structural_efficiency): {best_ind.fitness.values}") if __name__ == "__main__": main()
Explanation of the Code
Fitness Function: We define the fitness function to minimize the building’s material volume and maximize its structural efficiency. We also include an aesthetic penalty for deviating from the desired ratio between the base and top radii.
Multi-Objective Optimization: Since this is a multi-objective problem (minimizing volume while maximizing efficiency), we use the NSGA-II algorithm (selNSGA2) to handle the trade-offs between conflicting objectives.
Constraints: Bounds are enforced on the height, base radius, and top radius to ensure the building remains within practical limits.
Crossover and Mutation: The algorithm uses blend crossover (cxBlend) and Gaussian mutation (mutGaussian) to evolve the population. These operators modify the building parameters slightly in each generation.
Evolutionary Process: Over $200$ generations, the algorithm evolves the population, selecting individuals based on their fitness in both objectives (volume and structural efficiency).
Running the Algorithm
When you run the genetic algorithm, $DEAP$ will evolve the population of building designs over generations.
The algorithm will return the best-performing design (the individual with the optimal combination of height, base radius, and top radius), balancing material cost, structural efficiency, and aesthetic constraints.
Real-World Applications
Skyscraper Design: Optimizing the structural form of tall buildings for both cost-efficiency and stability.
Sustainable Architecture: Minimizing the environmental impact of construction by reducing material use while maintaining aesthetic integrity.
Bridge Design: Optimizing the shape of bridges to ensure they can support loads efficiently without using excessive materials.
Conclusion
This example demonstrates how $DEAP$ can be used for multi-objective optimization in architectural design, balancing structural efficiency, cost, and aesthetics.
By evolving the shape of the building over generations, the genetic algorithm helps identify an optimal design that satisfies multiple conflicting objectives.
Solving the Quadratic Assignment Problem with DEAP
Let’s tackle a challenging combinatorial optimization problem, specifically the Quadratic Assignment Problem ($QAP$).
This is a classic problem in combinatorial optimization, known for its complexity and difficulty.
Problem: Quadratic Assignment Problem (QAP)
The $QAP$ models scenarios where a set of facilities needs to be assigned to a set of locations, and the cost depends on both the flow between facilities and the distance between locations.
The goal is to minimize the total cost of assignment.
Problem Definition
You are given:
n facilities and n locations.
A flow matrix $( F \in \mathbb{R}^{n \times n} )$ where $( F[i][j] )$ is the flow between facility $( i )$ and facility $( j )$.
A distance matrix $( D \in \mathbb{R}^{n \times n} )$ where $( D[i][j] )$ is the distance between location $( i )$ and location $( j )$.
The objective is to find a permutation $( \pi )$ of $( {1, 2, …, n} )$ that assigns each facility to a location such that the total cost is minimized.
where $( \pi(i) )$ denotes the location assigned to facility $( i )$.
Example Scenario
Imagine you’re optimizing the layout of a factory.
There are multiple machines (facilities) and various spots (locations) where the machines can be placed.
The machines have specific interactions with each other (flow of goods), and the goal is to minimize transportation costs between machines by placing them in optimal spots based on their interactions.
Problem Setup
Objective: Minimize the total cost of assigning facilities to locations.
Constraints:
Each facility must be assigned to exactly one location.
Each location must host exactly one facility.
Method: Use a Genetic Algorithm (GA) via $DEAP$ to find the optimal assignment of facilities to locations.
DEAP Implementation
We will use $DEAP$ to model this problem as a permutation-based optimization problem, where each individual in the population represents a permutation (assignment of facilities to locations).
Step-by-Step Approach:
Representation: Each individual is a permutation of integers representing the assignment of facilities to locations.
Evaluation: The fitness of an individual is the total cost of the assignment (using the cost function described above).
Crossover and Mutation: Since this is a combinatorial problem, specialized crossover (e.g., partially mapped crossover) and mutation (e.g., swap mutation) operators are used.
Selection: Individuals are selected based on their fitness values for the next generation.
Here’s how to solve the $QAP$ using $DEAP$ in $Python$:
n = len(flow_matrix) # Number of facilities and locations
# Define the fitness function (minimize the total cost) deffitness_function(individual): total_cost = 0 for i inrange(n): for j inrange(n): total_cost += flow_matrix[i][j] * distance_matrix[individual[i]][individual[j]] return total_cost,
# Algorithm parameters population_size = 100 generations = 200 cx_prob = 0.7# Crossover probability mut_prob = 0.2# Mutation probability
# Run the Genetic Algorithm defmain(): pop = toolbox.population(n=population_size) hof = tools.HallOfFame(1) # Keep track of the best individual
stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("avg", np.mean) stats.register("min", np.min) # Run the GA pop, log = algorithms.eaSimple(pop, toolbox, cxpb=cx_prob, mutpb=mut_prob, ngen=generations, stats=stats, halloffame=hof, verbose=True)
# Output the best solution best_ind = hof[0] print(f"Best individual: {best_ind}") print(f"Best fitness (cost): {best_ind.fitness.values[0]}") if __name__ == "__main__": main()
Explanation of the Code
Fitness Function: The fitness_function calculates the total cost of assigning facilities to locations based on the flow and distance matrices.
Individual Representation: Each individual is a permutation of the indices $( {0, 1, 2, …, n-1} )$, representing an assignment of facilities to locations.
Crossover: We use partially matched crossover (PMX), which ensures valid permutations after crossover.
Mutation: The mutShuffleIndexes operator randomly swaps the positions of two elements in the permutation, introducing small variations.
Selection: We use tournament selection (selTournament) to select individuals for reproduction.
Running the Algorithm
When you run the genetic algorithm, $DEAP$ will evolve the population over time. The algorithm will keep track of the best solution (the permutation that results in the lowest cost) and report the final best individual and its corresponding cost.
Why This Is Challenging
The Quadratic Assignment Problem is NP-hard, meaning it is computationally difficult to solve optimally for large instances. The problem’s complexity grows rapidly as the number of facilities increases, due to the factorial number of possible assignments $( n! )$. This makes it a perfect candidate for metaheuristic approaches like Genetic Algorithms, which can efficiently search large solution spaces.
Real-World Applications
Facility Layout Planning: Optimizing the layout of machinery in factories to minimize transportation costs.
Data Center Design: Assigning servers to racks in a way that minimizes the cost of communication between servers.
Hospital Design: Assigning departments (facilities) to rooms (locations) to minimize the movement of patients, staff, and resources.
This example illustrates how $DEAP$ can be applied to solve complex combinatorial optimization problems using evolutionary algorithms.
This output represents the progress of the genetic algorithm over $200$ generations as it attempts to solve a combinatorial optimization problem using $DEAP$.
The key columns are:
gen: The current generation number.
nevals: The number of individuals evaluated in that generation.
avg: The average fitness (cost) of the population in that generation.
min: The minimum fitness (best solution) found in that generation.
Explanation:
The algorithm begins with an initial population, and over time, it refines the solutions.
The minimum fitness (cost) starts at 1436 and remains the same throughout the generations, indicating that the optimal solution was found early (possibly in the first generation).
The best individual (solution) is [3, 2, 0, 1], with a cost of 1436.
Despite multiple generations and evaluations, no better solution than $1436$ was found after the initial discovery.
The algorithm successfully converged, finding the optimal or near-optimal solution.
Let’s explore an optimization problem inspired by biological evolution, specifically survival of the fittest in an ecosystem.
In this example, different species of organisms are competing for resources, and the goal is to optimize their fitness over time by evolving traits that help them survive and reproduce.
Biological Evolution Optimization Problem
Consider a simplified model where organisms have three key traits:
Speed: Affects the ability to escape predators.
Strength: Affects the ability to hunt and gather resources.
Intelligence: Affects the ability to adapt to environmental changes.
The goal is to evolve a population of organisms to maximize their overall fitness, which is a function of these traits.
# Check if individuals stay within the bounds defcheckBounds(individual): for i inrange(len(individual)): if individual[i] < BOUND_LOW[i]: individual[i] = BOUND_LOW[i] elif individual[i] > BOUND_UP[i]: individual[i] = BOUND_UP[i] return individual
# Custom mating and mutation functions to enforce bounds defmate_and_checkBounds(ind1, ind2): tools.cxBlend(ind1, ind2, alpha=0.5) checkBounds(ind1) checkBounds(ind2) return ind1, ind2
# Algorithm parameters population_size = 100 generations = 200 cx_prob = 0.5# Crossover probability mut_prob = 0.2# Mutation probability
# Run the Genetic Algorithm defmain(): pop = toolbox.population(n=population_size) hof = tools.HallOfFame(1) # Keep track of the best individual
stats = tools.Statistics(lambda ind: ind.fitness.values) stats.register("avg", np.mean) stats.register("min", np.min) stats.register("max", np.max) # Run the GA pop, log = algorithms.eaSimple(pop, toolbox, cxpb=cx_prob, mutpb=mut_prob, ngen=generations, stats=stats, halloffame=hof, verbose=True)
# Output the best solution best_ind = hof[0] print(f"Best individual: {best_ind}") print(f"Best fitness: {best_ind.fitness.values[0]}") if __name__ == "__main__": main()
Explanation of the Code
Fitness Function: The fitness_function simulates the organism’s fitness based on speed, strength, and intelligence. It rewards combinations of traits that lead to better survival while penalizing extreme values that might be biologically impractical (e.g., overly strong or fast organisms that exhaust themselves quickly).
Bounds: We impose bounds on the traits to ensure that they stay within biologically plausible ranges ($0$ to $10$).
Mating and Mutation:
Mating: cxBlend combines the traits of two parent organisms. We ensure the offspring traits remain within bounds.
Mutation: mutGaussian introduces random mutations to the traits. After mutation, we apply the bounds to keep the traits within the valid range.
Population Evolution: The algorithm evolves the population over $200$ generations. During each generation, selection, crossover, and mutation are applied to produce new offspring, simulating biological evolution.
Running the Algorithm
When you run the genetic algorithm, it will evolve the population over time.
$DEAP$ will track the best individual (the organism with the highest fitness) and the average fitness in the population across generations.
The final result will show the traits of the fittest individual and their fitness score.
Biological Insights
This example mimics the evolutionary process, where organisms with the best combination of traits survive and reproduce.
The fitness landscape is non-linear, with trade-offs between speed, strength, and intelligence.
The genetic algorithm simulates how populations can optimize their traits over time to maximize survival.
This example showcases how $DEAP$ can be used to model and solve optimization problems inspired by biological evolution.
This table shows the results of a genetic algorithm run over $200$ generations.
Here’s a simple breakdown of the columns:
gen: The generation number, starting from $0$ up to $200$.
nevals: Number of evaluations (solutions checked) in each generation.
avg: The average fitness (quality of solutions) in that generation.
min: The minimum fitness in that generation (worst solution).
max: The maximum fitness in that generation (best solution).
The goal of the algorithm is to maximize fitness.
As we can see, the maximum fitness steadily improves across generations, starting from $84.94$ in generation $0$, and reaching the maximum of 110 by the end.
The best individual (solution) found is [10, 10.0, 10] with a fitness value of 110.0. This shows the algorithm successfully found an optimal or near-optimal solution.