
品質管理
製造工程の品質管理の例として、製造ラインで生成される製品の特徴量データを用いて、不良品を検出するモデルを構築することを考えてみましょう。
以下は、その一例です。
問題の設定: 製造工程の不良品検出
製造ラインで生成される製品の特徴量データを解析し、不良品を検出するためのモデルを構築します。
データには製品のサイズ、重量、温度などの特徴量が含まれます。
ステップ1: データの準備
以下は、ダミーの特徴量データの例です。データには正常品(0)と不良品(1)のラベルが含まれます。
1 | import numpy as np |
ステップ2: モデルの構築と評価
ランダムフォレスト分類器を使用してモデルを構築し、テストデータで評価します。
1 | # ランダムフォレスト分類モデルの構築 |
ステップ3: 結果の可視化
混同行列をヒートマップで可視化します。
1 | import seaborn as sns |
このヒートマップは、予測結果の混同行列を視覚化し、正常品と不良品の予測の正確さを示します。
[実行結果]
ソースコード解説
上記のソースコードは、ランダムフォレスト分類器を使用してダミーの特徴量データを分析し、混同行列と分類レポートを表示し、混同行列をヒートマップで可視化する一連の手順を実行するものです。
各部分の詳細を説明します。
データの生成と準備:
np.random.seed(42): 乱数のシードを設定し、結果の再現性を確保します。num_samples,num_features: ダミーデータのサンプル数と特徴量の数を定義します。data:num_samples×num_featuresのランダムな特徴量データを生成します。labels: ダミーのラベルを生成します(0または1)。df: ランダムな特徴量データとラベルを結合したデータフレームを作成します。
訓練データとテストデータの分割:
X: ラベルを除いた特徴量データを選択します。y: ラベルを選択します。train_test_split: データを訓練データとテストデータに分割します。
ここでは、テストデータの割合を0.2に設定しています。
モデルの構築:
RandomForestClassifier: ランダムフォレスト分類器をインスタンス化します。
ここでは100個の決定木を使ってモデルを構築します。model.fit(X_train, y_train): 訓練データを使用してモデルを学習させます。
テストデータの予測:
model.predict(X_test): テストデータを使用してモデルが予測するラベルを取得します。
混同行列と分類レポートの表示:
confusion_matrix(y_test, y_pred): 実際のラベル(y_test)と予測されたラベル(y_pred)から混同行列を計算します。classification_report(y_test, y_pred): 適合率、再現率、F1スコアなどの分類レポートを計算します。
混同行列のヒートマップの可視化:
sns.heatmap: Seabornライブラリを使用して、混同行列をヒートマップとして可視化します。annot=True: セル内に数値を表示します。fmt='d': 数値のフォーマットを整数(デジット)に設定します。cmap='Blues': ヒートマップの色のスキームを設定します。plt.xlabel,plt.ylabel,plt.title: 軸ラベルとタイトルを設定します。
これにより、モデルの性能評価と混同行列の可視化が行われます。
混同行列は、実際のラベルと予測されたラベルの関係を示し、分類モデルの性能を詳細に理解するための重要な情報を提供します。
結果解説
実行結果としては、分類モデルの性能を示す混同行列(Confusion Matrix)と分類レポート(Classification Report)が表示されます。
これらの結果を詳しく説明します。
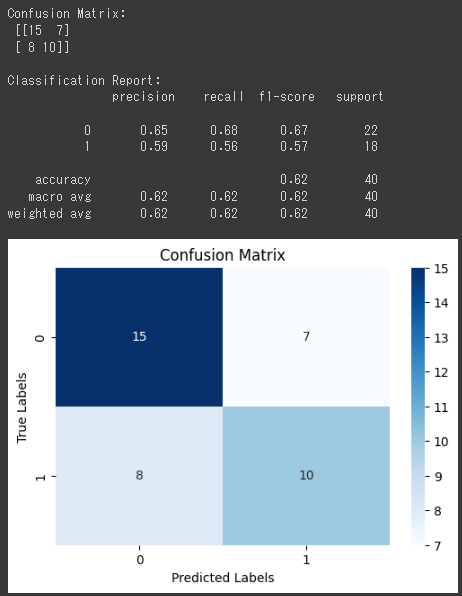
Confusion Matrix:
1 | [[15 7] |
混同行列は、正解ラベル(True Labels)と予測ラベル(Predicted Labels)を比較したものです。
行は実際のラベルを、列は予測されたラベルを表しています。
この行列の要素は以下のようになります。
- 左上のセル (15) は、実際のラベルが0(正常品)であり、モデルが予測したラベルも0(正常品)だったデータの数を示します。
- 右上のセル (7) は、実際のラベルが0(正常品)であり、モデルが予測したラベルが1(不良品)だったデータの数を示します。
- 左下のセル (8) は、実際のラベルが1(不良品)であり、モデルが予測したラベルが0(正常品)だったデータの数を示します。
- 右下のセル (10) は、実際のラベルが1(不良品)であり、モデルが予測したラベルも1(不良品)だったデータの数を示します。
Classification Report:
1 | precision recall f1-score support |
分類レポートは、各クラス(正常品と不良品)の適合率(precision)、再現率(recall)、F1スコア(f1-score)などの性能指標を示します。
以下は各指標の説明です。
- Precision (適合率):
予測した正例(不良品)のうち、実際に正例だった割合です。
クラス0(正常品)とクラス1(不良品)のそれぞれに対して計算されます。 - Recall (再現率):
実際の正例(不良品)のうち、モデルが正例と予測した割合です。
クラス0とクラス1のそれぞれに対して計算されます。 - F1-score:
適合率と再現率の調和平均であり、両指標のバランスを示します。 - Support:
各クラスのサンプル数を示します。 - Accuracy:
全てのサンプルに対する正確な予測の割合です。
マクロ平均(macro avg)は、クラスごとの指標の平均を取ります。
ウェイト付き平均(weighted avg)は、各クラスのサポート(サンプル数)に応じて加重平均を取ります。
この結果を見ると、精度(accuracy)は0.62であり、正確な予測の割合が62%であることがわかります。
適合率、再現率、F1スコアは各クラスごとに計算され、各クラスの性能を示しています。