
地震発生パターン・クラスタリング
地震の発生予測は非常に複雑な問題であり、現時点では確実な予測は困難です。
地震の発生は地球の地殻の複雑な動きによるものであり、さまざまな要因が影響を与えます。
従って、地震の予測はscikit-learnなどの単純な機械学習ライブラリだけでは達成できるものではありません。
ただし、地震データの解析や震源推定など、地震の研究には機械学習を応用することがあります。
以下は、地震データのクラスタリングを例として示します。
これは地震の発生パターンを把握するために用いられる手法の一つです。
まず、以下のような仮想的な地震データを生成します:
1 | import numpy as np |
次に、scikit-learnのKMeansを用いて地震データをクラスタリングします:
1 | from sklearn.cluster import KMeans |
最後に、クラスタリング結果を散布図でグラフ化します:
1 | import matplotlib.pyplot as plt |
この例では、仮想的な地震データを生成し、そのデータをKMeansアルゴリズムでクラスタリングしています。
ただし、これは地震予測ではなく、地震データの解析・可視化に関する簡単な例です。
地震予測には、より高度な手法や複数のデータソースを組み合わせた専門的なアプローチが必要です。
[実行結果]
ソースコード解説
上記のソースコードは、仮想的な地震データを生成し、そのデータをKMeansアルゴリズムを用いてクラスタリングしています。
このソースコードを詳しく説明します。
1. データの生成:
最初に、仮想的な地震データを生成します。このデータは3つの列からなります。
- 列1(緯度): 30から40の範囲でランダムな緯度を500個生成します。
- 列2(経度): 130から140の範囲でランダムな経度を500個生成します。
- 列3(マグニチュード): 4.0から7.5の範囲でランダムなマグニチュード(地震の大きさ)を500個生成します。
2. KMeansによるクラスタリング:
次に、scikit-learnのKMeansアルゴリズムを使用してデータをクラスタリングします。
KMeansアルゴリズムは非教師あり学習の一つで、データを指定されたクラスタ数に分割します。
クラスタリングは次の手順で行われます:
- データポイントをランダムに選んでクラスタの中心を初期化します。
- 各データポイントを最も近いクラスタの中心に割り当てます。
- クラスタの中心を再計算します。
- 上記の2つのステップを繰り返します。中心の変化が小さくなるか、最大反復回数に達するまで続けます。
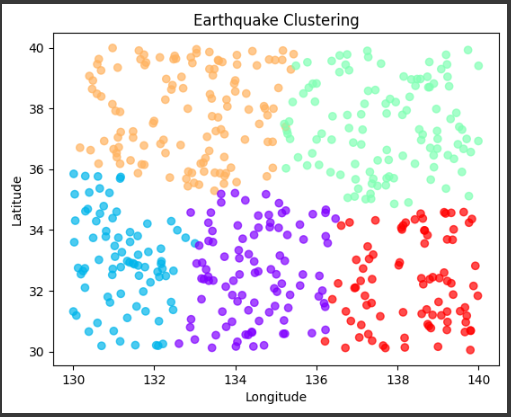
3. グラフ化:
最後に、クラスタリング結果を散布図としてグラフ化します。
緯度がy軸、経度がx軸になります。
各データポイントはクラスタに基づいて異なる色で表示されます。
同じ色のデータポイントは同じクラスタに所属しています。
この結果を通じて、KMeansアルゴリズムが地震データをいくつかのクラスタに分割したことがわかります。
各クラスタは地震データの特徴的なパターンを表していると考えることができます。
ただし、今回の例は仮想的なデータを用いた簡単なクラスタリングであり、実際の地震の予測や解析にはより高度な手法と実際の地震データが必要です。