
欠損値補完
ある企業の従業員に関するデータがあり、その中で給与(Salary)が一部欠損している場合を考えます。
この欠損値をscikit-learnを使用して補完する問題を以下に示します。
1 | import numpy as np |
上記のコードでは、SimpleImputerを使用して欠損値を平均値で補完しています。
strategy='mean'とすることで、平均値を使って欠損値を補完します。
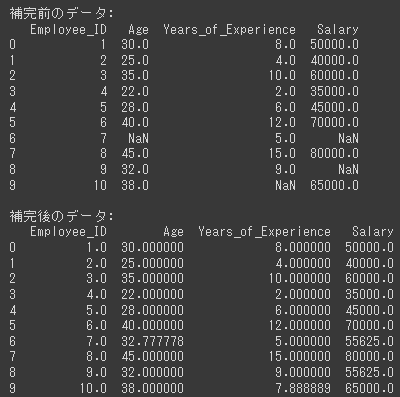
このコードを実行すると、補完前のデータと補完後のデータが表示されます。
補完後のデータでは、欠損値が平均値で補完されていることが確認できるでしょう。
[実行結果]
ソースコード解説
このコードは、NumPyとPandasを使用して仮想的なデータセットを作成し、scikit-learnのSimpleImputerを使って欠損値を平均値で補完しています。
以下にコードの詳細を説明します。
1. import numpy as np:
NumPyライブラリをnpとしてインポートします。
NumPyは数値計算を行うためのPythonライブラリです。
2. import pandas as pd:
Pandasライブラリをpdとしてインポートします。
Pandasはデータ操作や分析を行うためのPythonライブラリで、データフレームというデータ構造を提供します。
3. from sklearn.impute import SimpleImputer:
scikit-learnのimputeモジュールからSimpleImputerをインポートします。SimpleImputerは欠損値補完を行うためのクラスです。
4. data:
仮想的なデータセットを辞書型で定義します。
このデータセットには、従業員のID(Employee_ID)、年齢(Age)、経験年数(Years_of_Experience)、給与(Salary)が含まれています。np.nanは欠損値を示す特別な値です。
5. df:
PandasのDataFrameを使って、上記のデータセットを作成します。
6. imputer = SimpleImputer(strategy='mean'):
SimpleImputerクラスのインスタンスを作成します。strategy='mean'とすることで、平均値を使って欠損値を補完する設定にします。
7. df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns):
SimpleImputerを用いて、dfの欠損値を補完します。fit_transformメソッドを使って、補完処理を行い、新しいデータフレームdf_imputedに補完後のデータを格納します。
8. print("補完前のデータ:")およびprint("補完後のデータ:"):
補完前と補完後のデータを表示するためのメッセージを出力します。
9. print(df)およびprint(df_imputed):
dfとdf_imputedの中身を表示します。
これにより、補完前後のデータがわかります。
このコードでは、欠損値があるデータを補完する方法として、SimpleImputerを使って平均値で補完しています。