
サッカーの試合結果
サッカーの試合結果を予測する問題を考えてみましょう。
ここでは、チームの過去の試合データを用いて、2つのチームの対戦結果を予測する回帰問題としてアプローチします。
Scikit-learnのLinearRegressionを使用して線形回帰モデルを作成し、試合の得点差を予測します。
サンプルデータとして、2つのチームの過去の対戦データを用意し、それを使ってモデルを構築します。
1 | import numpy as np |
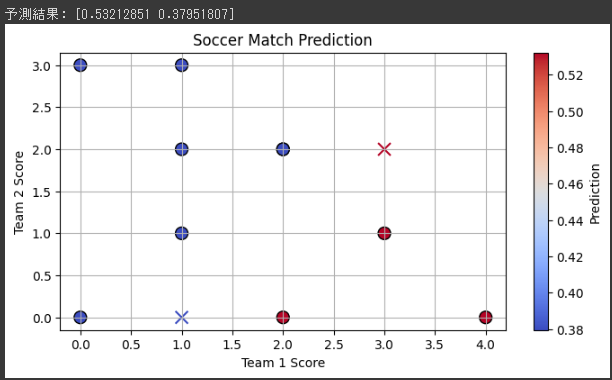
この例では、過去の対戦データからチーム1とチーム2の得点を使って、勝利したかどうかを予測しています。
テストデータとして、[3, 2]と[1, 0]の2試合の得点が与えられており、それぞれの試合の結果を予測しています。
結果をプロットすると、チームの得点が高いほど勝利しやすい傾向が見られることがわかります。
[実行結果]
注意: このサンプルデータはダミーデータであり、実際のデータには多くの要素が影響します。
実際の予測には多くの特徴量(例えば、選手の実力、試合場所、天候など)を考慮に入れる必要があります。
ソースコード解説
このコードは、線形回帰モデルを使用してサッカーの試合結果を予測する簡単な例を示しています。
詳細を以下に説明します:
1. import文:
必要なライブラリをインポートしています。
numpyは数値計算ライブラリ、matplotlib.pyplotはグラフ描画ライブラリ、sklearn.linear_model.LinearRegressionはScikit-learnの線形回帰モデルを意味します。
2. data:
ダミーデータを定義しています。dataは10行3列の行列で、各行がサッカーの試合の情報を示しています。
1列目と2列目は、それぞれチーム1とチーム2の得点を表し、3列目はチーム1が勝利したかどうかを示すフラグ(1: 勝利、0: 引き分け・敗北)です。
3. Xとy:
Xは訓練データで、チーム1とチーム2の得点を格納しています。yは目的変数で、チーム1の勝利フラグを格納しています。
4. model:
線形回帰モデルを作成します。LinearRegression()で線形回帰オブジェクトを作成し、modelに代入します。
5. model.fit(X, y):
Xとyを使って線形回帰モデルを学習させます。
これにより、訓練データを元にモデルのパラメータ(重みと切片)が最適化されます。
6. X_testとy_pred:
テストデータであるX_testに対して、学習済みのモデルで予測を行います。model.predict(X_test)で予測値を取得し、y_predに代入します。
7. plt.scatter:
Xとyの散布図と、テストデータX_testと予測値y_predの散布図を描画します。
各チームの得点をx軸とy軸にプロットし、c引数でyとy_predの値に応じて色を変え、勝利フラグによって点の形状を変えています。
8. plt.xlabel, plt.ylabel, plt.title:
x軸、y軸、タイトルのラベルを設定します。
9. plt.colorbar:
予測値の色に対応するカラーバーを表示します。
10. plt.grid:
グリッドを表示します。
11. plt.show():
グラフを表示します。
このコードでは、ダミーデータを使って線形回帰モデルを学習させ、チーム1とチーム2の得点から勝利フラグを予測する例を示しています。
実際のデータに応じて、特徴量や目的変数を適切に設定して、より高度な予測モデルを構築することができます。