
金融不正取引検出
金融取引の不正行為を検出する問題は、クラス不均衡なデータセットを扱うことが一般的です。
ここでは、scikit-learnを使用してランダムフォレストを適用して不正行為を検出する例を示します。
まず、ダミーのデータを用意します。
不正行為は通常レアケースなので、不正行為の例が多く含まれるデータを生成します。
1 | import numpy as np |
次に、ランダムフォレストモデルをトレーニングし、テストデータを用いて予測を行います。
1 | # ランダムフォレストモデルの作成とトレーニング |
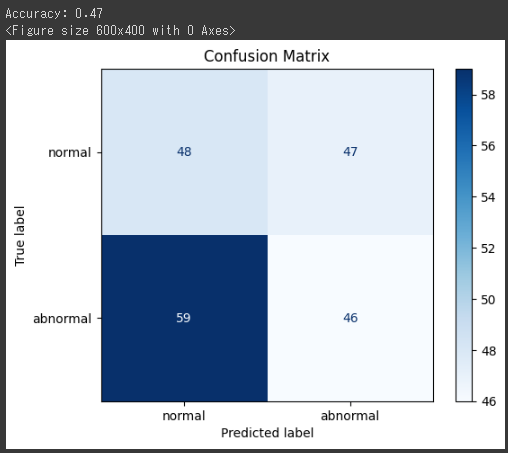
最後に、混同行列をグラフ化して結果を分かりやすく表示します。
1 | # 混同行列の作成 |
これにより、ランダムフォレストを用いて不正行為の検出が行われます。
混同行列は、実際のクラスと予測されたクラスの対応を視覚化するのに役立ちます。
不正行為の検出はクラス不均衡な問題なので、適切な評価指標(Precision、Recall、F1-scoreなど)の使用が重要です。
[実行結果]
ソースコード解説
処理の詳細は以下の通りです。
1. ダミーデータの生成:
np.random.normal(loc=100, scale=20, size=num_samples)により、平均が100、標準偏差が20の正規分布に従う取引金額データが生成されます。np.random.randint(0, 2, num_samples)により、0と1からなる不正行為のデータ(0が正常取引、1が不正取引)が生成されます。dfには、取引金額と不正行為のデータが含まれたDataFrameが格納されます。
2. データの分割:
train_test_splitを使用して、データセットをトレーニングセットとテストセットに分割します。
ここでは、トレーニングセットが80%、テストセットが20%になるように分割しています。
3. モデルのトレーニングと予測:
RandomForestClassifierを使用して、ランダムフォレストモデルを作成します。
ランダムフォレストは、複数の決定木を組み合わせるアンサンブル学習の一種です。rf_model.fit(X_train, y_train)により、トレーニングデータを使用してモデルをトレーニングします。rf_model.predict(X_test)により、テストデータを使って不正行為を予測します。
4. 正解率の評価:
accuracy_score(y_test, y_pred)により、テストデータの予測結果(y_pred)と真のラベル(y_test)を比較し、正解率を計算します。- 正解率は、予測が全体のテストデータのうちどれだけ正確に分類されたかを示す指標です。
5. 混同行列のグラフ化:
confusion_matrix(y_test, y_pred)により、テストデータを使って作成した予測結果と真のラベルを用いて混同行列が作成されます。plot_confusion_matrixを使用して混同行列をグラフ化し、実際のクラスと予測されたクラスの対応を視覚化します。
このようにして、ランダムフォレストモデルを使用して不正行為を検出し、評価指標を用いてモデルの性能を評価しています。
データの性質や使用するアルゴリズムによっては、他の評価指標(Precision、Recall、F1-scoreなど)を使うことが適切な場合もあります。
また、実際の運用ではさまざまな前処理やモデルチューニングが必要になることを考慮してください。