
宗教選択予想
宗教の例題として、ある地域の人々の宗教信仰に関するデータを使って、その要因から宗教の選択を予測する多クラス分類問題を考えてみましょう。
具体的には、年齢、性別、家族の宗教、教育レベルなどを特徴量とし、宗教をカテゴリで表すターゲットを予測します。
まずは、scikit-learnのライブラリをインポートします。
1 | import numpy as np |
次に、架空の宗教データを作成します。
1 | # 架空の宗教データを生成 |
次に、K近傍法(K-Nearest Neighbors)を使って多クラス分類モデルを構築し、トレーニングデータを用いて学習させます。
1 | # K近傍法のモデルを初期化 |
モデルを学習させた後は、テストデータを用いて予測を行い、性能を評価してみましょう。
1 | # テストデータを用いて予測 |
最後に、結果をグラフ化してみます。
宗教が5つのカテゴリに分かれるため、t-SNE(t-distributed Stochastic Neighbor Embedding)を使って特徴量を2次元に圧縮し、散布図として表示します。
1 | from sklearn.manifold import TSNE |
これにより、宗教の要因から宗教の選択を予測する多クラス分類問題を解くためのK近傍法モデルを構築し、性能評価とともに宗教の選択を2次元散布図で可視化しました。
ただし、実際のデータではさまざまな要因が複雑に絡み合うため、より多くの特徴量やより複雑なモデルを検討する必要があるかもしれません。
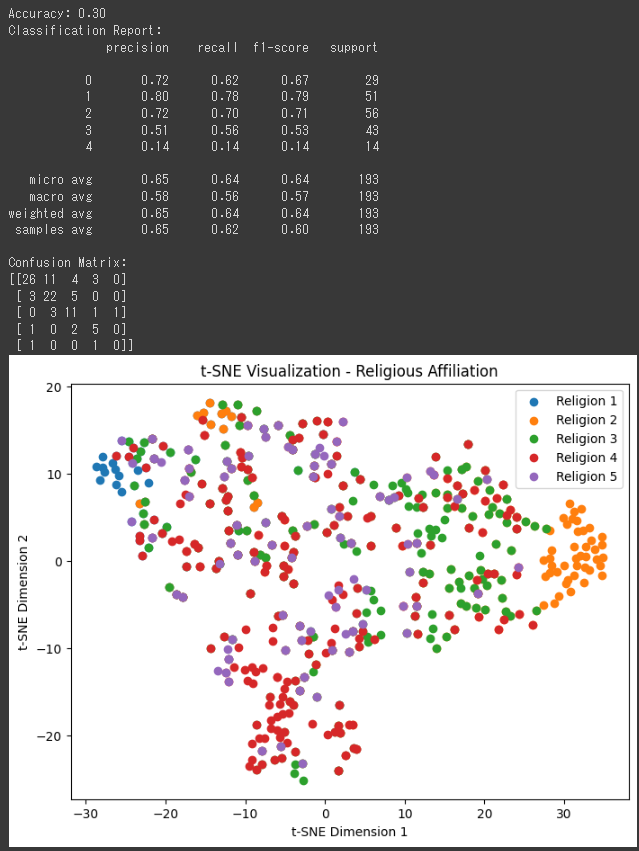
[実行結果]
ソースコード解説
このコードは、架空の宗教データを生成し、K近傍法(K-Nearest Neighbors)を使って多クラス分類モデルを構築し、その性能を評価する一連の処理を行っています。
また、t-SNEを用いて特徴量を2次元に圧縮し、宗教の選択を可視化しています。
具体的な処理について説明します。
1. 架空の宗教データの生成
make_multilabel_classification関数を使って、架空の宗教データを生成しています。
n_samplesでサンプル数、n_featuresで特徴量の数、n_classesでクラス数、n_labelsで各サンプルにおけるラベルの数(多クラス分類の場合は1以上)を指定しています。
2. 特徴量のスケーリング
StandardScalerを使って特徴量をスケーリングしています。
スケーリングを行うことで、特徴量の範囲を揃え、モデルの学習を安定化させることができます。
3. データの分割
train_test_splitを使って、トレーニングデータとテストデータにデータを分割しています。
トレーニングデータはモデルの学習に使用し、テストデータはモデルの性能評価に使用します。
test_sizeでテストデータの割合を指定します。
4. K近傍法モデルの初期化と学習
KNeighborsClassifierを使ってK近傍法モデルを初期化し、トレーニングデータを用いてモデルを学習させています。
n_neighborsで近傍点の数を指定します。
5. テストデータを用いた予測と評価
学習したK近傍法モデルを使って、テストデータの特徴量から宗教の選択を予測します。
予測結果と正解データを用いて、正解率、分類レポート、混同行列を計算し、結果を表示します。
6. t-SNEによる可視化
TSNEを使って特徴量を2次元に圧縮します。
次元圧縮を行うことで、多次元の特徴量を2次元にプロットし、可視化します。
散布図を描画し、各クラスごとに色分けして宗教の選択を可視化しています。
このコードは、架空の宗教データを使って多クラス分類モデルを構築し、その性能評価と特徴量の可視化を行っているものです。
ただし、架空のデータであるため、実際のデータに対してはより多くの試行と評価が必要です。
結果解説
この結果は、多クラス分類モデル(K近傍法)による宗教の選択の予測の評価結果です。
1. Accuracy(正解率): 0.30
- 正解率は、全体の予測がどれだけ正確だったかを示す指標で、0から1までの値を取ります。
この結果では、30%の正解率が得られています。
つまり、全体の予測のうち、30%が正しく宗教の選択を予測できているということを意味します。
2. Classification Report(分類レポート):
- 分類レポートは、各クラスごとに、precision(適合率)、recall(再現率)、f1-score(F1スコア)、support(サポート数)の評価指標を示しています。
- precision: 正例と予測したサンプルのうち、実際に正例だった割合を示します。
値が高いほど、偽陽性(誤って正と予測した場合)が少なくなります。 - recall: 実際の正例のうち、正しく正例と予測できた割合を示します。
値が高いほど、偽陰性(誤って負と予測した場合)が少なくなります。 - f1-score: 適合率と再現率の調和平均であり、両者をバランスよく考慮した指標です。
値が高いほど、適合率と再現率がバランス良く高いことを示します。 - support: 各クラスのサンプル数を示します。
3. Confusion Matrix(混同行列):
- 混同行列は、予測結果と実際のラベルの対応を示す行列です。行が実際のラベル、列が予測結果を表します。
- 行列の (i, j) の要素は、実際のラベルが i であり、予測結果が j であったサンプル数を表します。
この結果を見ると、モデルの性能はあまり高くないことがわかります。
正解率が30%と低いため、全体的な予測があまり精度よくありません。
各クラスの適合率、再現率、f1-scoreを見ると、クラスごとにばらつきがあります。
特にクラス4の適合率、再現率、f1-scoreは低く、このクラスの予測が困難であることが示唆されます。
これらの結果を元にモデルの改善点を考えると、特徴量の選択や追加、モデルのハイパーパラメータの調整、より複雑なモデルの検討などが考えられます。
実際のデータに対しては、より多くの試行と評価が必要です。