
アナフィラキシー
アナフィラキシーに関する例題として、特定の症状やアレルギーの情報を使用して、ある人がアナフィラキシーを経験するかどうかを予測する二値分類タスクを考えます。
この例題では、scikit-learnを使用してランダムフォレストモデルを構築し、その結果をグラフ化します。
1 | import pandas as pd |
このコードでは、ランダムフォレストモデルを構築し、テストデータで予測結果を評価しています。
また、ROC曲線とAUCを計算してモデルの予測性能を評価し、結果をグラフ化しています。
上記のコードを実行すると、ランダムなサンプルデータに対するモデルの予測性能を確認することができます。
[実行結果]
ソースコード解説
このコードは、アナフィラキシーを経験するかどうかを予測するためのランダムフォレストモデルを構築し、その性能を評価して可視化するためのPythonコードです。
以下に各部分の説明を提供します:
1. ライブラリのインポート:
import pandas as pd:
pandasライブラリをインポートし、データを扱うためのデータフレームを作成するために使用します。import numpy as np:
NumPyライブラリをインポートし、数値計算やランダムなサンプルデータの生成に使用します。import matplotlib.pyplot as plt:
Matplotlibライブラリをインポートし、グラフを描画するために使用します。from sklearn.model_selection import train_test_split:
scikit-learnのtrain_test_split関数をインポートし、データをトレーニングセットとテストセットに分割するために使用します。from sklearn.ensemble import RandomForestClassifier:
scikit-learnのRandomForestClassifierクラスをインポートし、ランダムフォレストモデルを構築するために使用します。from sklearn.metrics import accuracy_score, confusion_matrix, roc_curve, roc_auc_score:
scikit-learnの各種評価指標をインポートし、モデルの性能評価に使用します。
2. サンプルデータの生成:
np.random.seed(42):
乱数のシードを設定して、再現性を確保します。num_samples = 100:
サンプルデータの件数を100件として設定します。age,gender,allergy_symptom_1,allergy_symptom_2,allergy_symptom_3,anaphylaxis_experience:
乱数を使用して、年齢や性別、アレルギー症状の有無、アナフィラキシーの経験をランダムに生成します。
3. サンプルデータをデータフレームに変換:
data = pd.DataFrame({ ... }):
ランダムに生成したサンプルデータを辞書形式でデータフレームに変換します。pd.get_dummies(data, columns=['性別']):
性別のようなカテゴリカル変数をダミー変数化して、特徴量のデータを数値データに変換します。
4. データの前処理:
X = data.drop('アナフィラキシー経験', axis=1):
特徴量を抽出します。y = data['アナフィラキシー経験']:
ラベル(アナフィラキシー経験の有無)を抽出します。X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42):
データをトレーニングセットとテストセットに分割します。
5. ランダムフォレストモデルの構築と評価:
model = RandomForestClassifier(random_state=42):
ランダムフォレストモデルを構築します。model.fit(X_train, y_train):
モデルをトレーニングデータに適合させます。y_pred = model.predict(X_test):
テストデータで予測を行います。accuracy = accuracy_score(y_test, y_pred):
正解率を計算します。conf_matrix = confusion_matrix(y_test, y_pred):
混同行列を作成します。y_prob = model.predict_proba(X_test)[:, 1]:
テストデータに対するアナフィラキシーの経験の確率を予測します。fpr, tpr, _ = roc_curve(y_test, y_prob):
ROC曲線を計算します。roc_auc = roc_auc_score(y_test, y_prob):
AUCを計算します。
6. 結果のグラフ化:
plt.plot(fpr, tpr, ... ):
ROC曲線をグラフ化します。plt.xlabel('False Positive Rate'):
X軸のラベルを設定します。plt.ylabel('True Positive Rate'):
Y軸のラベルを設定します。plt.title('Receiver Operating Characteristic (ROC)'):
グラフのタイトルを設定します。plt.legend(loc='lower right'):
グラフに凡例を表示します。plt.show():
グラフを表示します。
これにより、ランダムフォレストモデルの性能評価が実行され、ROC曲線が可視化されます。
結果解説
結果を詳しく説明します。
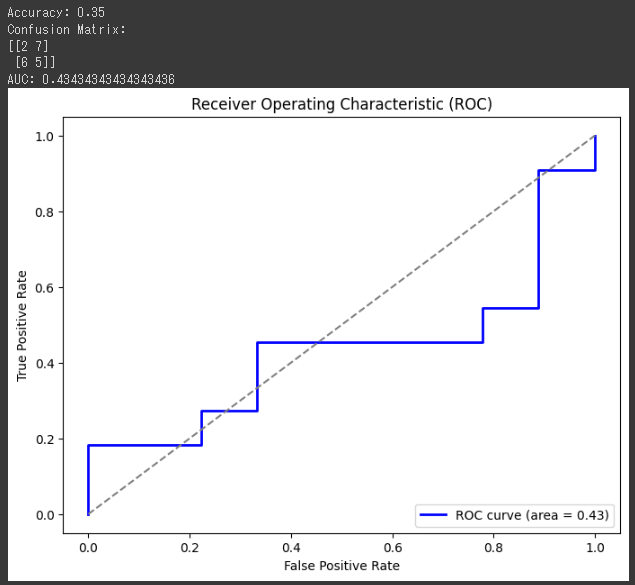
1. 正解率 (Accuracy): 0.35
正解率は、モデルが全体の予測において正確だった割合を示します。
この値は0から1の間で取ることができます。
今回の結果では、正解率が0.35(または35%)となっています。
つまり、テストセットに対してモデルの予測が正確だった割合は35%であることを意味します。
2. 混同行列 (Confusion Matrix):
混同行列は、モデルの予測結果と実際の真のラベルとの一致状況を示す行列です。
この行列は4つの要素から構成されます。
- 真陽性 (True Positive, TP): 正しくアナフィラキシーを経験したと予測されたサンプル数 (5)
- 偽陽性 (False Positive, FP): アナフィラキシーを経験していないのに誤ってアナフィラキシーを経験したと予測されたサンプル数 (7)
- 真陰性 (True Negative, TN): 正しくアナフィラキシーを経験していないと予測されたサンプル数 (2)
- 偽陰性 (False Negative, FN): アナフィラキシーを経験したのに誤ってアナフィラキシーを経験していないと予測されたサンプル数 (6)
今回の混同行列の結果は以下のようになっています:
1
2[[2 7]
[6 5]]
この結果から、実際にアナフィラキシーを経験しているグループに対しては、5つのサンプルを正確に予測し、6つのサンプルを誤って予測しています。
一方、実際にアナフィラキシーを経験していないグループに対しては、2つのサンプルを正確に予測し、7つのサンプルを誤って予測しています。
3. AUC (Area Under the Curve): 0.43434343434343436
AUCは、ROC曲線(Receiver Operating Characteristic curve)の下の面積を示す値です。
ROC曲線は、真陽性率(True Positive Rate, TPR)に対する偽陽性率(False Positive Rate, FPR)の変化を表現します。
AUCは、モデルの分類性能を評価する指標で、0から1の間の値を取ります。
AUCが0.5に近いほど、モデルの分類性能がランダムに近くなります。
今回の結果では、AUCが約0.43であるため、モデルの性能はランダムに近いと評価されます。
この結果から、現在のモデルはアナフィラキシーの経験を予測するにはあまり精度が高くなく、改善の余地があると考えられます。
モデルの性能向上のためには、特徴量の選択やエンジニアリング、ハイパーパラメータの調整、より大きなデータセットの使用などが考えられます。