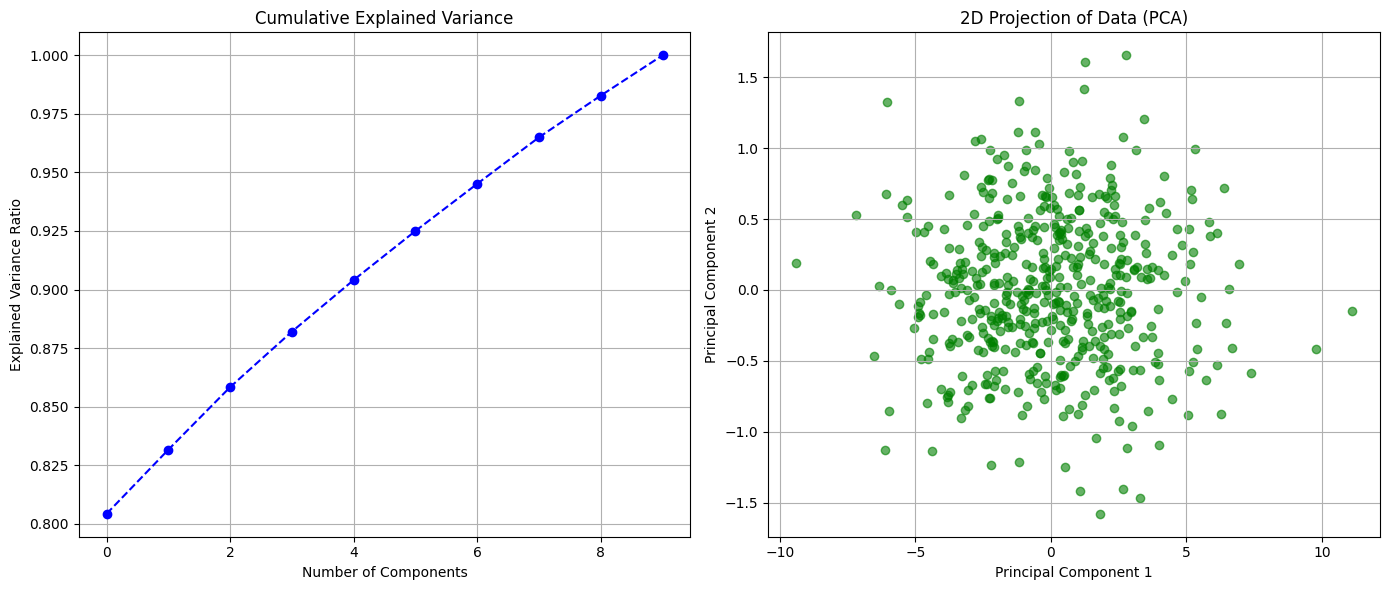
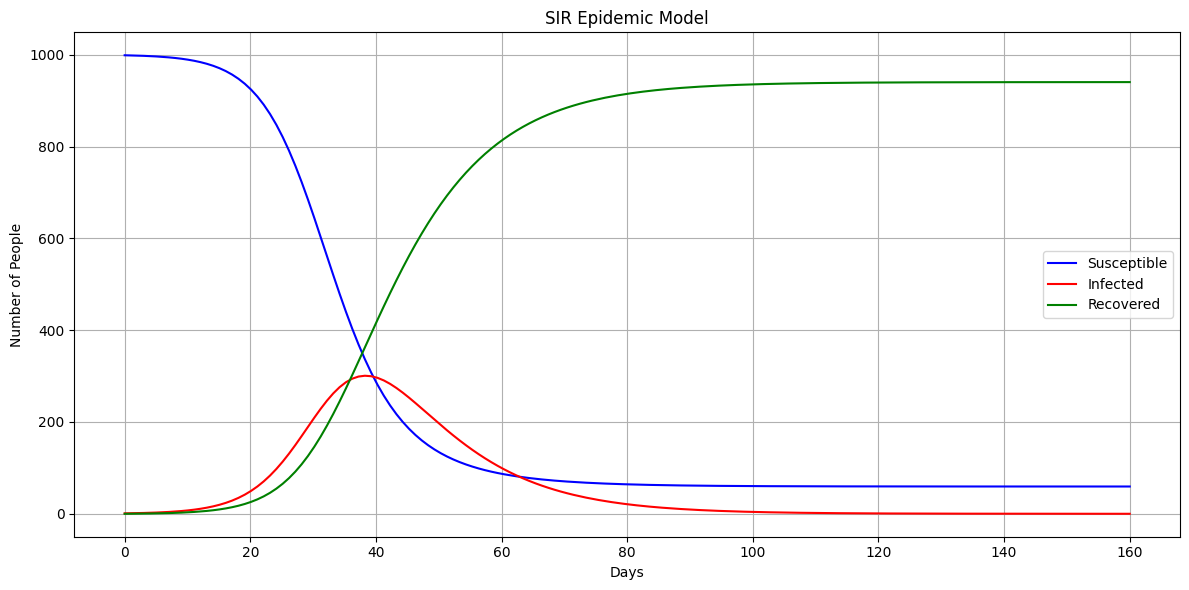
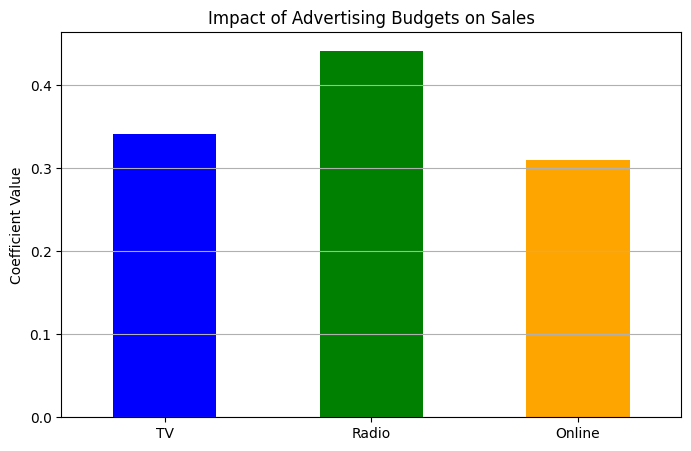
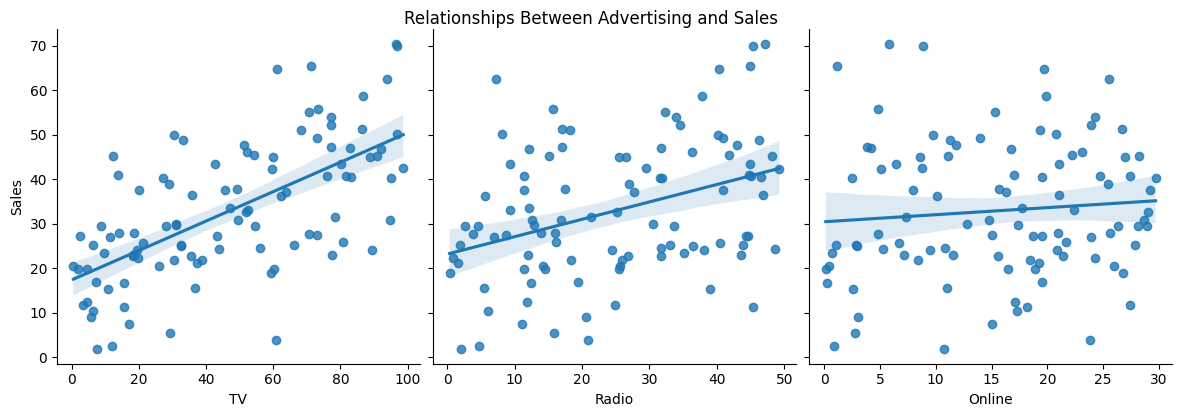
Example Problem: Inflation Targeting Simulation
In this example, we aim to simulate the inflation dynamics under a basic monetary policy rule, such as the $Taylor Rule$.
The $Taylor Rule$ adjusts the nominal interest rate based on deviations of inflation and output from their target levels.
We’ll model how inflation converges to the target over time under this rule.
Problem
Given:
- Inflation starts at a level significantly higher than the target.
- A central bank adjusts the interest rate to influence inflation.
- The inflation equation is simplified to a function of past inflation, output gap, and the interest rate.
We will simulate how inflation evolves over time with:
- A fixed inflation target.
- Parameters for monetary policy responsiveness.
Python Code
1 | import numpy as np |
Explanation
- Taylor Rule:
- Sets the nominal interest rate based on inflation deviation and output gap.
- Inflation Dynamics:
- Inflation adjusts gradually in response to interest rate changes.
- Visualization:
- The top graph shows how inflation converges to the target.
- The bottom graph displays the interest rate adjustments over time.
Results
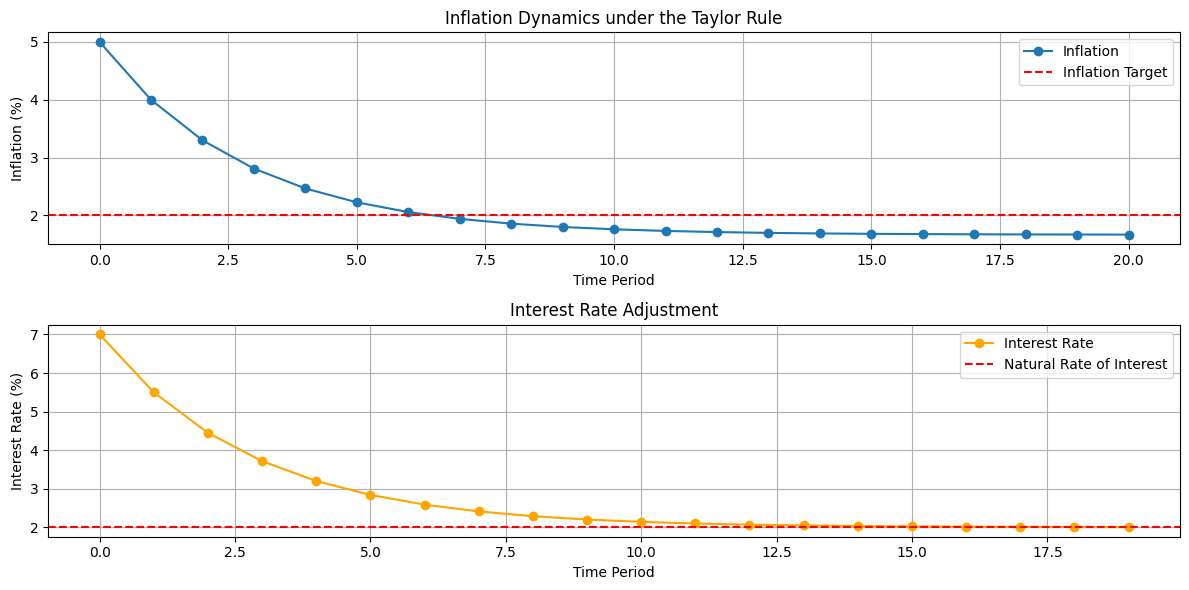
- Inflation converges toward the target ($2$%) over time due to the central bank’s interest rate adjustments.
- Interest rates stabilize as inflation reaches the target.
This illustrates the effectiveness of inflation targeting under the $Taylor Rule$.