シンプソンのパラドックス
シンプソンのパラドックスは、データを解釈する際に生じる混乱を示す統計学上のパラドックスです。
具体的には、集団全体と部分集団の間で、同じデータを用いて異なる結論が導かれることを示します。
このパラドックスは、条件付き確率の誤解やサンプルサイズの影響に関連しています。
例えば、ある特定の属性を持つ集団を部分集団として考えた場合、その属性に関する統計的傾向が逆転することがあります。
つまり、部分集団での割合が高いのに、全体集団での割合が低くなる場合があります。
このパラドックスは、統計的推論やデータ解釈において、慎重な考慮が必要であることを強調します。
サンプルソース
シンプソンのパラドックスは、3つの異なる群のデータを結合した場合に、それぞれのグループの平均値が異なるにも関わらず、結合した全体の平均値が逆にそれらの平均値よりも高い場合を指します。
以下に、シンプソンのパラドックスを示す簡単な例を用いてPythonでグラフ化する方法を示します。
1 | import numpy as np |
このコードでは、3つの異なる群のデータを生成し、それぞれをヒストグラムとしてプロットします。
結合した全体のデータもヒストグラムとしてプロットされ、シンプソンのパラドックスを可視化します。
[実行結果]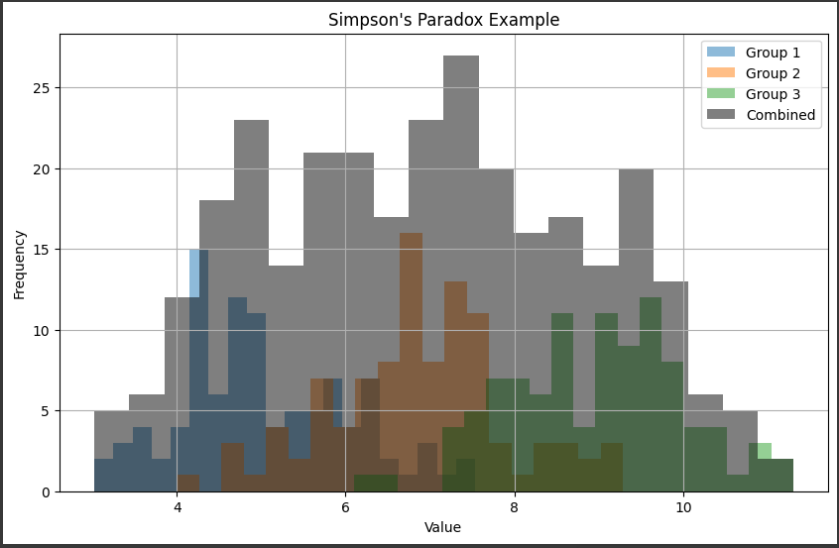
ソースコード解説
ソースコードの部分について詳細に説明します。
1. ライブラリのインポート:
1 | import numpy as np |
numpyは数値計算を行うためのPythonライブラリで、npとしてインポートされています。matplotlib.pyplotはグラフを描画するためのPythonライブラリで、pltとしてインポートされています。
2. グループのデータ生成:
1 | group1_mean = 5 |
group1_meanとgroup1_stdはグループ1のデータの平均値と標準偏差を表します。np.random.normal()関数を使用して、平均値がgroup1_meanで標準偏差がgroup1_stdの正規分布に従うデータを生成します。- これにより、グループ1のデータが
group1_samplesとして格納されます。
$100$個のサンプルが生成されます。
3. 同様に、グループ2とグループ3のデータも生成されます。
4. データの結合:
1 | combined_data = np.concatenate((group1_samples, group2_samples, group3_samples)) |
np.concatenate()関数を使用して、3つのグループのデータを結合して1つの配列にします。- これにより、全体のデータが
combined_dataとして格納されます。
5. プロット:
1 | plt.figure(figsize=(10, 6)) |
plt.figure(figsize=(10, 6))は、図のサイズを設定します。plt.hist()関数は、ヒストグラムを描画します。alphaパラメータは透明度を設定し、labelパラメータは凡例のラベルを設定します。plt.xlabel()とplt.ylabel()は、x軸とy軸のラベルを設定します。plt.title()は図のタイトルを設定します。plt.legend()は、凡例を表示します。plt.grid(True)は、グリッド線を表示します。plt.show()は、図を表示します。
このコードは、3つの異なるグループのデータを生成し、それらをヒストグラムとしてプロットしています。
さらに、結合したデータのヒストグラムもプロットされ、シンプソンのパラドックスが可視化されています。
結果解説
[実行結果]
このグラフでは、シンプソンのパラドックスの例を示しています。
各グループのヒストグラム:
- “Group 1”, “Group 2”, “Group 3” というラベルが付けられた3つのヒストグラムが表示されています。
- 各グループは、それぞれ異なる平均値と標準偏差を持ちます。
- 各グループのヒストグラムは、それぞれのグループが持つデータの分布を示しています。
ヒストグラムは、データの値の範囲をいくつかの階級(ビン)に分割し、各階級に含まれるデータの頻度(個数)を表示します。
結合したデータのヒストグラム:
- “Combined” というラベルが付けられた黒いヒストグラムが表示されています。
- このヒストグラムは、3つの異なるグループからのデータを結合した全体のデータの分布を示しています。
- 結合したデータのヒストグラムは、各グループのデータの組み合わせから得られる全体のデータの分布を示しています。
シンプソンのパラドックスの本質は、個々のグループの平均値が異なる方向に移動する一方で、結合したデータの平均値がそれらの平均値よりも大きくなることです。
これは、データが持つ特定の相関構造や関係性によって引き起こされることがあります。