これまではLightGBMの初期パラメータで学習を行ってきました。
LightGBMは各種パラメータを設定することができますので、今回はそのパラメータを調整して学習・推測を行ってみます。
データの読み込み
タイタニックのデータセットを読み込み、データの前処理を行って、正解ラベルとそれ以外にデータを分割します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import numpy as np
import pandas as pd
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
# データ前処理
def preprocessing(df):
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# カテゴリ変数の型変換
df['Sex'] = df['Sex'].astype('category')
df['Embarked'] = df['Embarked'].astype('category')
return df
x_titanic = preprocessing(df_train.drop(['Survived'], axis=1))
y_titanic = df_train['Survived']
|
パラメータの表示
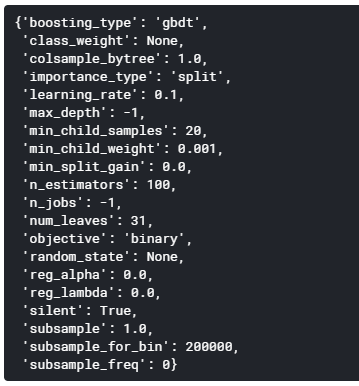
まず、LightGBMの各種パラメータを表示します。
[ソース]
1
2
3
4
5
6
| import lightgbm as lgb
# LightGBMの分類器をインスタンス化
gbm = lgb.LGBMClassifier(objective='binary')
gbm.get_params()
|
[出力]
グリッドサーチ
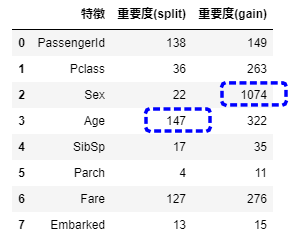
いろいろなパラメータが表示されましたが、今回はこのうち次の3パラメータに対してチューニングを行います。
- num_leaves
木にある分岐の個数です。大きくすると精度は上がるが過学習しやすくなります。
- reg_alpha
L1正則化に相当するものです。デフォルトでは 0.1 ぐらいを使うことが多いです。
L1正則化にあたるのであまり大きな値を使用するとかなり重要な変数以外を無視するようなモデルになってしまうため、精度を求めている場合あまり大きくしないほうが良いでしょう。
- reg_lambda
L2 正則化に相当するものです。デフォルトでは L1 と同様に 0.1 ぐらいを指定します。
L1と違い大きな値を設定してもその変数が使われないということはありませんので、特徴量の数が多い時や、徐々に木を大きくしたいすぐにオーバーフィットするような問題に対して大きく取ることが多いです。
params変数に候補となるパラメータのリストを指定し、グリッドサーチを使って最適パラメータを探索します。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from sklearn.model_selection import GridSearchCV
# 試行するパラメータを羅列
params = {
'num_leaves': [3, 4, 5, 6, 7, 8, 9, 10],
'reg_alpha': [0, 1, 2, 3, 4, 5,10, 100],
'reg_lambda': [10, 15, 18, 20, 21, 22, 23, 25, 27, 29]
}
grid_search = GridSearchCV(gbm, param_grid=params, cv=3)
grid_search.fit(x_titanic, y_titanic)
print(grid_search.best_score_)
print(grid_search.best_params_)
|
[出力]

チューニングしたパラメータの性能確認
グリッドサーチでのパラメータ探索の結果、num_leaves=5、reg_alpha=0、reg_lambda=22が交差検証でのスコアがベストであることが分かりました。
デフォルトのパラメータの場合と、このパラメータを使った場合の正解率の違いを確認してみます。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from sklearn import model_selection
print('== デフォルト・パラメータの場合 ==')
gbm = lgb.LGBMClassifier(objective='binary')
score = model_selection.cross_val_score(gbm, x_titanic, y_titanic, cv=3) # cv=3は3分割の意
print('各正解率', score)
print('正解率', score.mean())
print('\n== パラメータをチューニングした場合 ==')
gbm = lgb.LGBMClassifier(objective='binary', num_leaves=5, reg_alpha=0, reg_lambda=22)
score = model_selection.cross_val_score(gbm, x_titanic, y_titanic, cv=3) # cv=3は3分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[出力]

デフォルト・パラメータの正解率が74.41%、チューニングしたパラメータでの正解率が82.49%となっており、だいぶ正解率が向上しています。
学習・推論
チューニングしたパラメータを使って、学習・推論を行います。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
| from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 訓練データをtrainとvalidに分割
train_x, valid_x, train_y, valid_y = train_test_split(x_titanic, y_titanic, test_size=0.33, random_state=0)
# 学習
gbm.fit(train_x, train_y)
# 推論
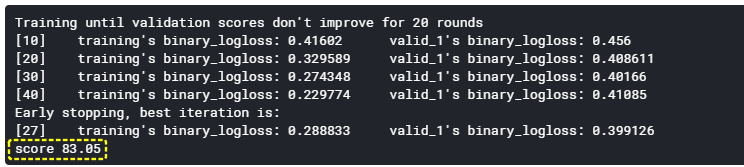
pre = gbm.predict(valid_x, num_iteration=gbm.best_iteration_)
print('score', round(accuracy_score(valid_y, pre) * 100, 2))
|
[出力]

Kaggleに提出
検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出してみます。
[ソース]
1
2
3
4
5
6
7
8
9
| # 検証データの読み込み
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
df_test = preprocessing(df_test)
pre = gbm.predict(df_test)
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre
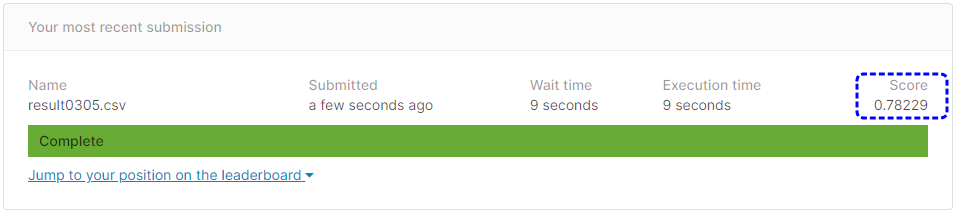
result.to_csv('result0306.csv', index=False)
|
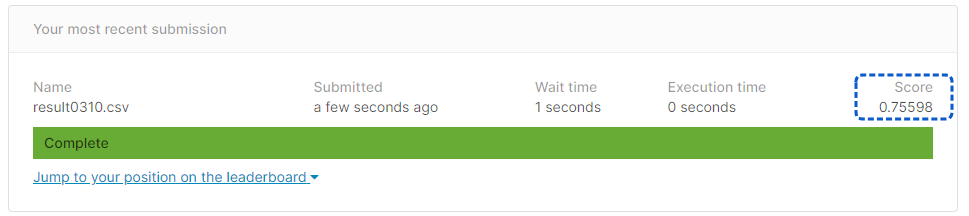
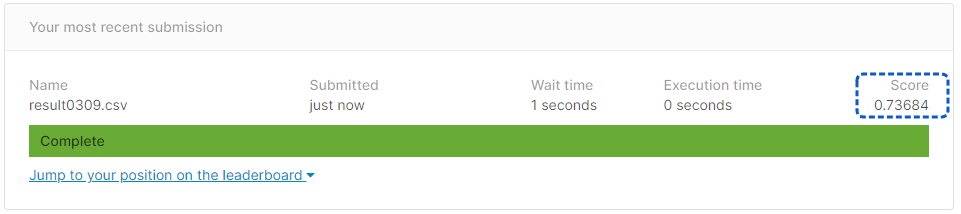
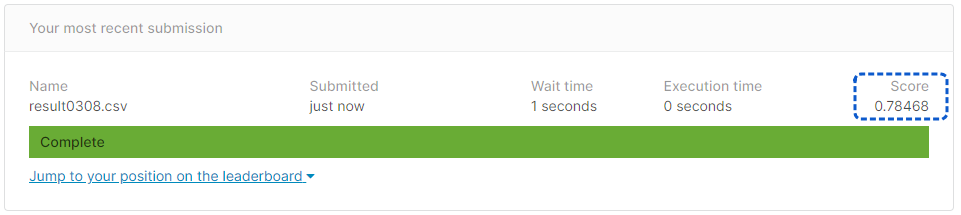
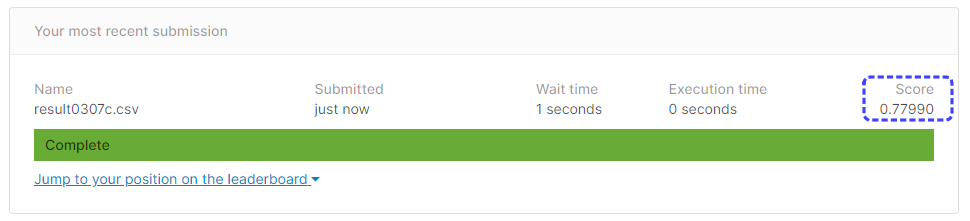
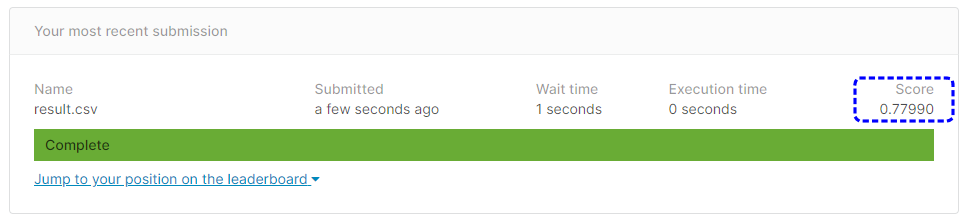
[提出結果]
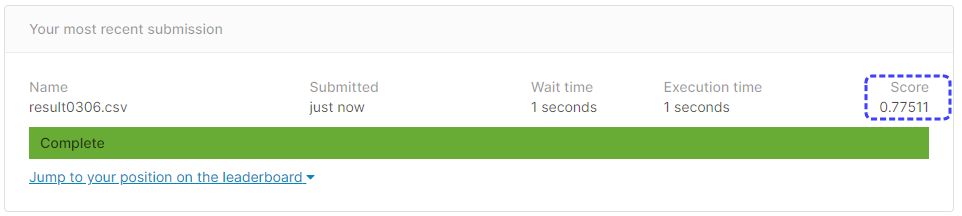
正解率77.51%と、チューニング前よりも成績が悪くなってしまいました。
reg_lambdaの指定リストがよくなかったような気がします。
グリッドサーチ機能は便利なのですが、最適なパラメータ候補を指定するのがなかなかに難しいです。
ハイパーパラメータを自動最適化するOptunaというツールがあるらしいので今度使ってみたいと思います。