# Google Colabでの設定 from IPython.display import HTML import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from matplotlib.animation import FuncAnimation
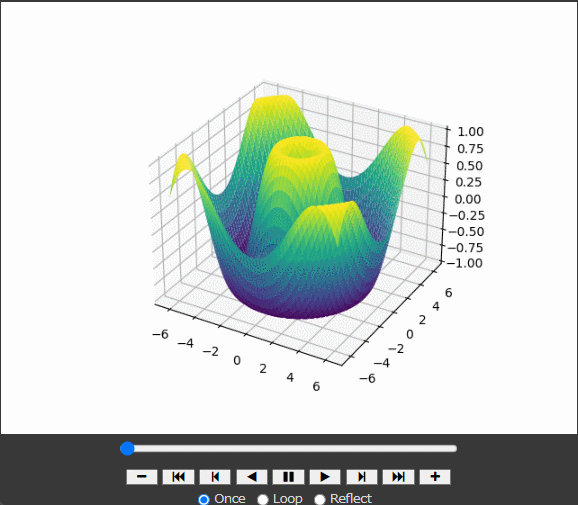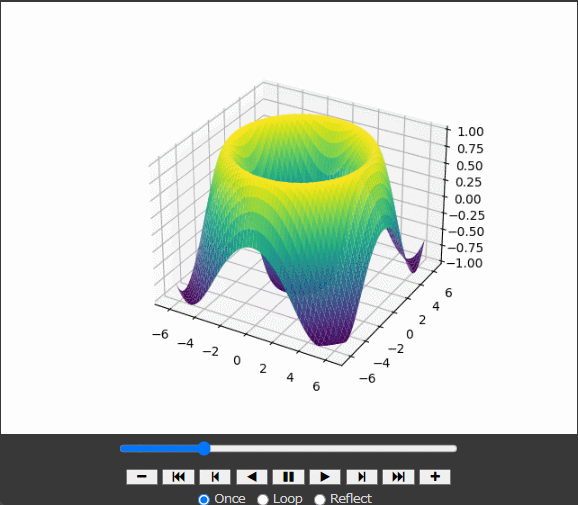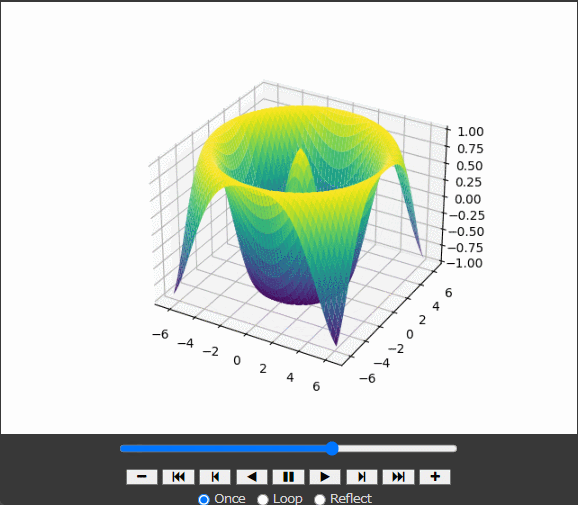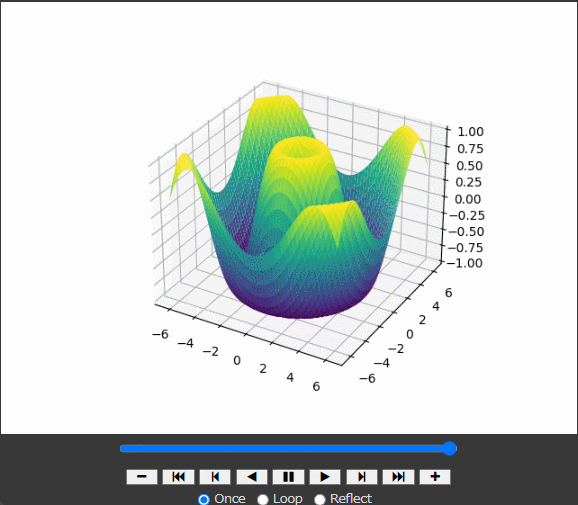
# データの生成 x = np.linspace(-2 * np.pi, 2 * np.pi, 200) y = np.linspace(-2 * np.pi, 2 * np.pi, 200) x, y = np.meshgrid(x, y) z = np.sin(np.sqrt(x**2 + y**2))
from IPython.display import HTML import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from matplotlib.animation import FuncAnimation
ax.plot_surface(x, y, z, cmap='viridis'): x, y, zのデータを用いて3Dサーフェスプロットを作成。 cmap='viridis'はカラーマップを指定。
5. アニメーションの更新関数
1 2 3 4 5 6 7
defupdate(frame): global z, line ax.clear() z = np.sin(np.sqrt(x**2 + y**2) + frame / 10.0) line = ax.plot_surface(x, y, z, cmap='viridis') ax.set_zlim(-1, 1) return line,
update(frame): アニメーションの各フレームで呼び出される関数。
ax.clear(): 現在のプロットをクリア。
z = np.sin(np.sqrt(x**2 + y**2) + frame / 10.0): zの値をフレームごとに更新。
line = ax.plot_surface(x, y, z, cmap='viridis'): 更新されたzの値で新しいサーフェスプロットを作成。
ax.set_zlim(-1, 1): z軸の範囲を設定。
return line,: 更新されたプロットを返す。
6. アニメーションの設定
1
ani = FuncAnimation(fig, update, frames=200, interval=50, blit=False)