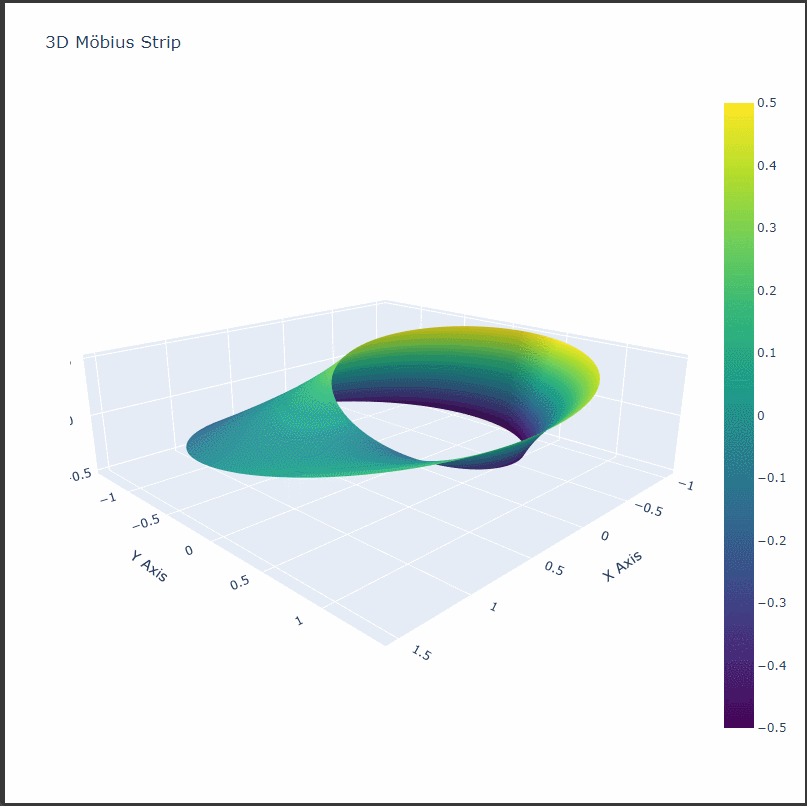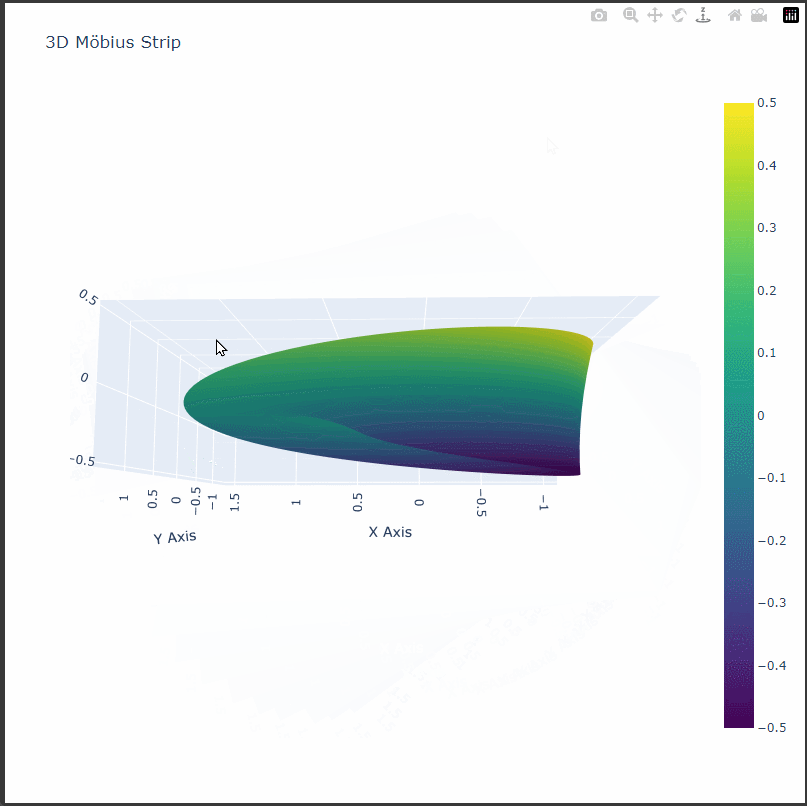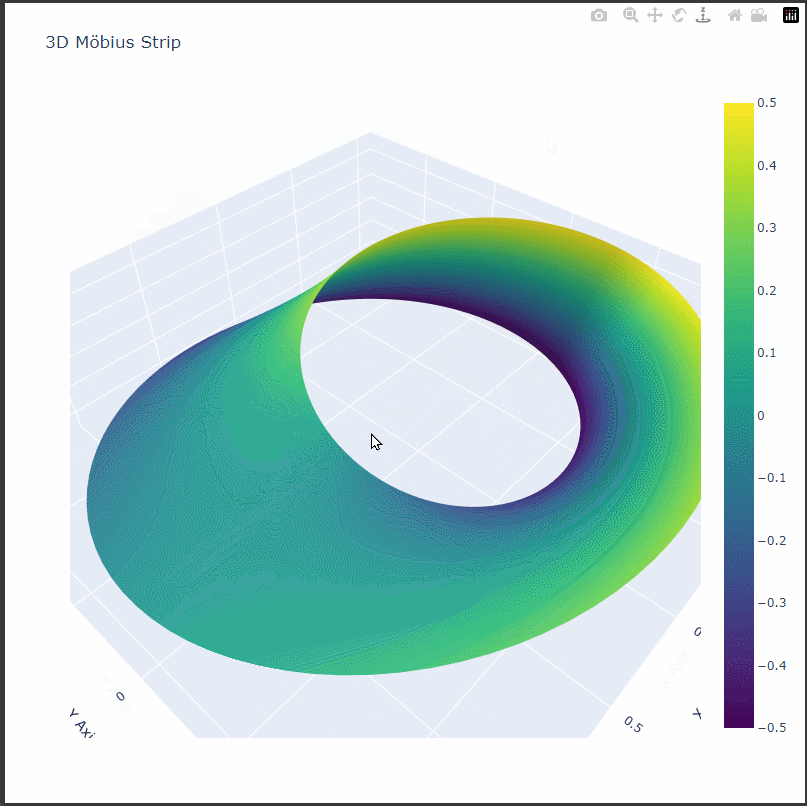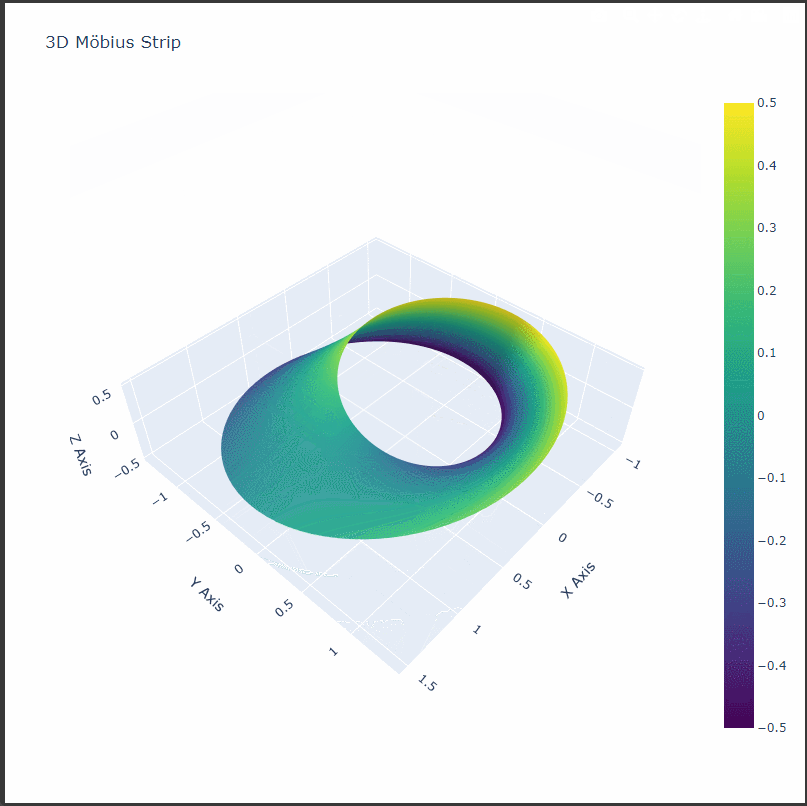
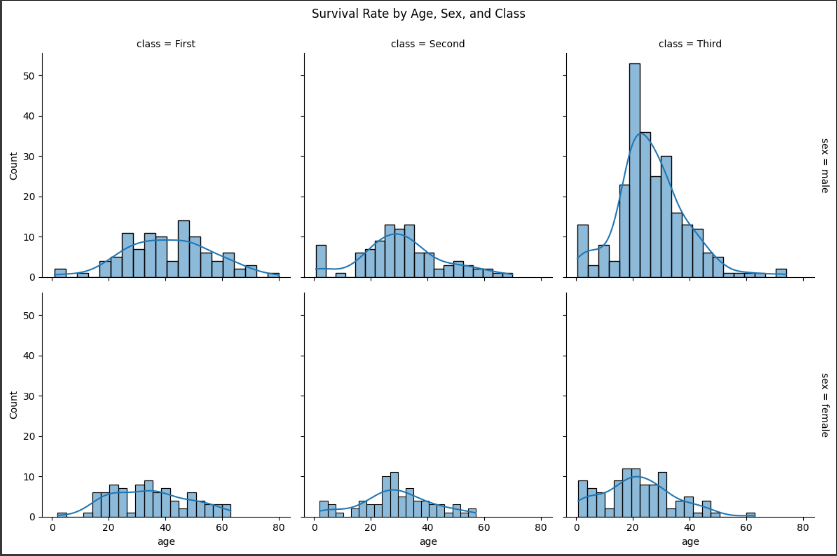
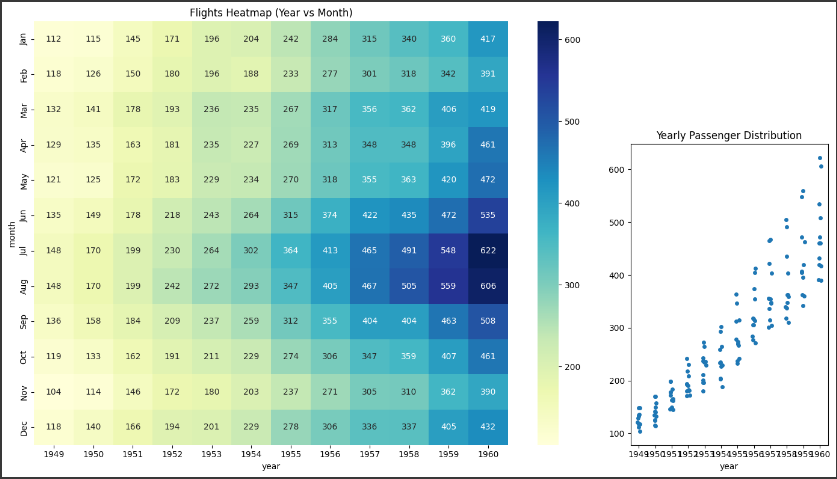
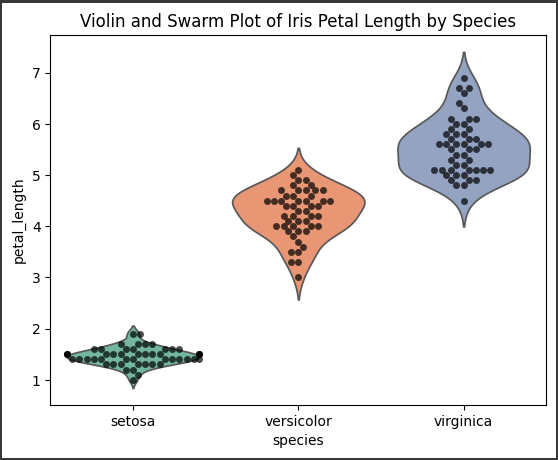
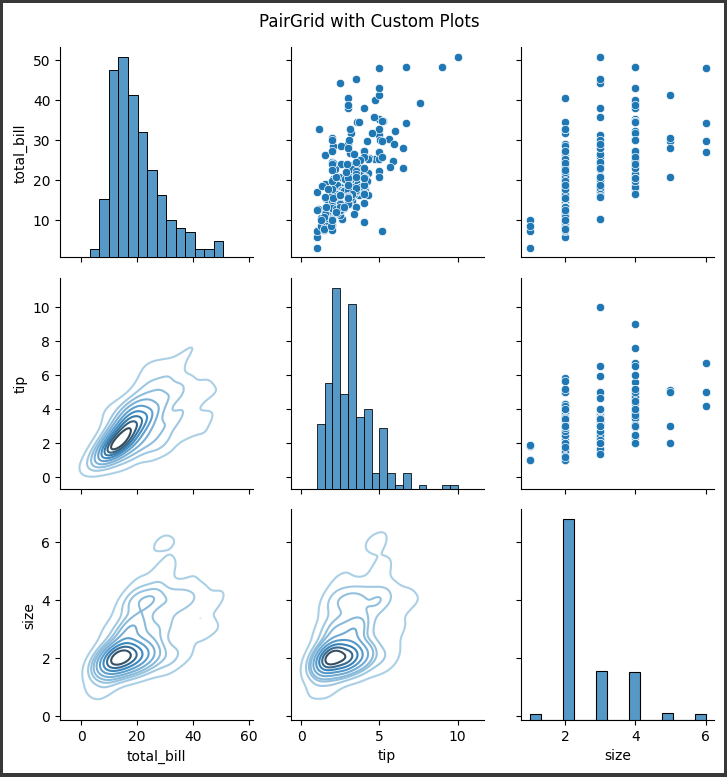
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
G = nx.DiGraph()
G.add_nodes_from(["A", "B", "C", "D", "E", "F", "G", "H"])
edges = [
("A", "B", {"distance": 5, "capacity": 15}),
("A", "C", {"distance": 10, "capacity": 10}),
("B", "D", {"distance": 8, "capacity": 20}),
("C", "D", {"distance": 2, "capacity": 25}),
("C", "E", {"distance": 7, "capacity": 15}),
("D", "F", {"distance": 6, "capacity": 10}),
("E", "F", {"distance": 3, "capacity": 5}),
("F", "G", {"distance": 4, "capacity": 30}),
("E", "H", {"distance": 12, "capacity": 20}),
("H", "G", {"distance": 9, "capacity": 10}),
]
G.add_edges_from(edges)
shortest_path_distance = nx.shortest_path(G, source="A", target="G", weight="distance")
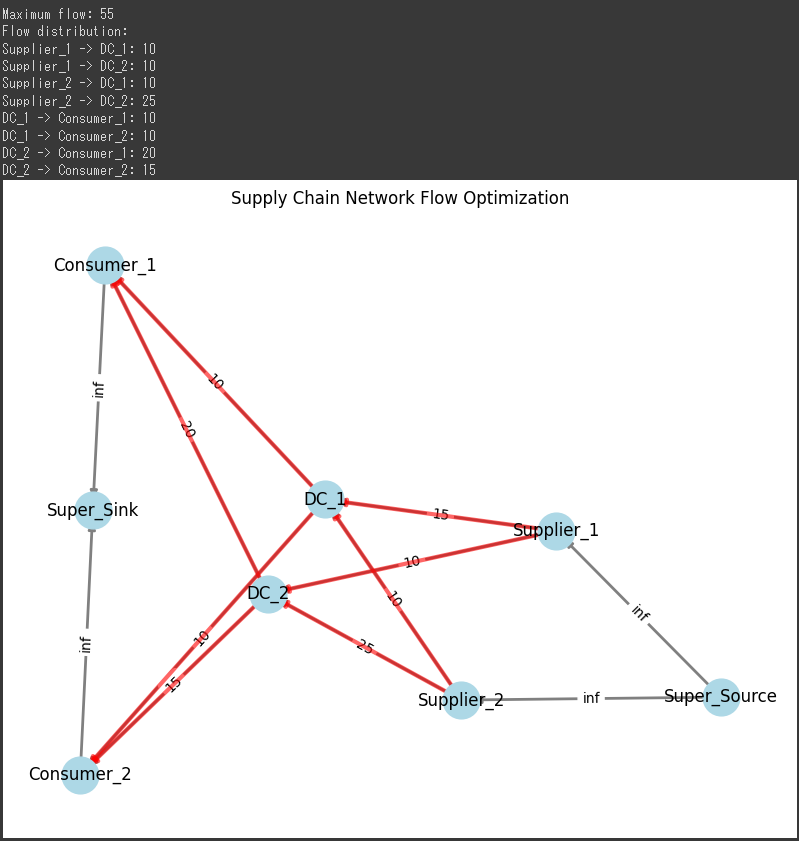
max_flow_value, max_flow_dict = nx.maximum_flow(G, "A", "G", capacity="capacity")
pagerank = nx.pagerank(G)
eigenvector_centrality = nx.eigenvector_centrality_numpy(G)
print("Shortest Path (Distance) from A to G:", shortest_path_distance)
print("Maximum Flow from A to G:", max_flow_value)
print("PageRank:", pagerank)
print("Eigenvector Centrality:", eigenvector_centrality)
pos = nx.spring_layout(G, seed=42)
node_sizes = [5000 * eigenvector_centrality[node] for node in G.nodes()]
edge_widths = [G[u][v]["capacity"] / 10 for u, v in G.edges()]
edge_colors = [G[u][v]["distance"] for u, v in G.edges()]
plt.figure(figsize=(10, 8))
nx.draw_networkx_nodes(G, pos, node_size=node_sizes, node_color='skyblue')
nx.draw_networkx_edges(G, pos, width=edge_widths, edge_color=edge_colors, edge_cmap=plt.cm.Blues)
nx.draw_networkx_labels(G, pos, font_size=12, font_color='black')
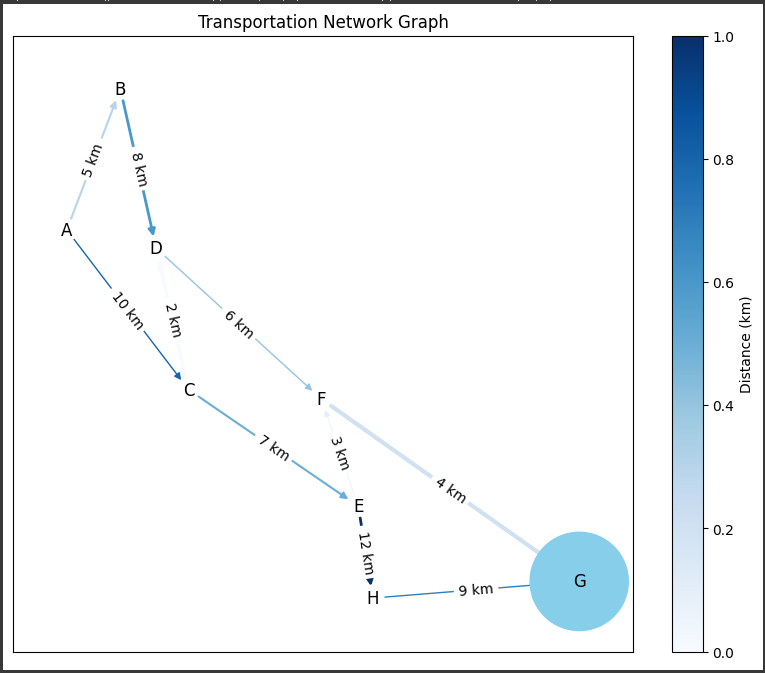
edge_labels = {(u, v): f"{G[u][v]['distance']} km" for u, v in G.edges()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=10)
plt.title("Transportation Network Graph")
plt.colorbar(plt.cm.ScalarMappable(cmap=plt.cm.Blues), label="Distance (km)")
plt.show()
|