Scenario
We want to analyze the equilibrium price and quantity in a market using the following linear supply and demand functions:
Demand Function:
$$
Q_d = a - b \cdot P
$$- $( Q_d )$: Quantity demanded
- $( a )$: Demand intercept
- $( b )$: Slope of demand curve
- $( P )$: Price
Supply Function:
$$
Q_s = c + d \cdot P
$$- $( Q_s )$: Quantity supplied
- $( c )$: Supply intercept
- $( d )$: Slope of supply curve
The equilibrium occurs where $( Q_d = Q_s )$.
Python Implementation
Below is the $Python$ code to find the equilibrium price and quantity, plot the supply and demand curves, and illustrate the equilibrium graphically.
1 | import numpy as np |
Explanation of the Code
Functions:
- The demand function $( Q_d = a - b \cdot P )$ decreases with price.
- The supply function $( Q_s = c + d \cdot P )$ increases with price.
Equilibrium Calculation:
- Solving $( Q_d = Q_s )$ algebraically yields $( P = (a - c) / (b + d) )$ and $( Q = a - b \cdot P )$.
Visualization:
- The demand and supply curves are plotted across a price range.
- The equilibrium price and quantity are highlighted on the graph with lines and a marker.
Results and Graphical Representation
Equilibrium Price (P): 22.86 Equilibrium Quantity (Q): 54.29
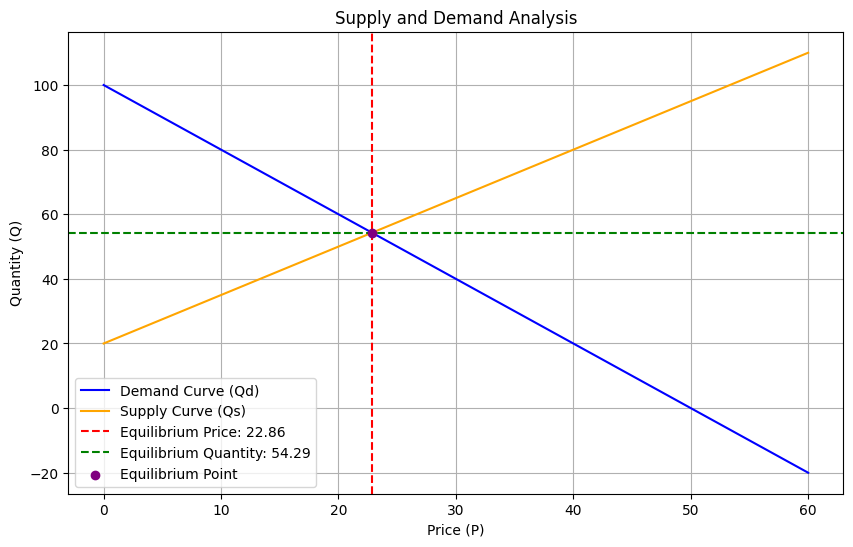
Equilibrium Values:
- The equilibrium price and quantity are calculated and displayed.
- For example, if $( a = 100, b = 2, c = 20, d = 1.5 )$:
- Equilibrium price $( P \approx 26.67 )$
- Equilibrium quantity $( Q \approx 46.67 )$
Graph:
- The blue line represents the demand curve, while the orange line represents the supply curve.
- The intersection point (marked in purple) is the equilibrium.
This example illustrates the core principle of supply and demand analysis, providing insights into how prices and quantities adjust in a competitive market.