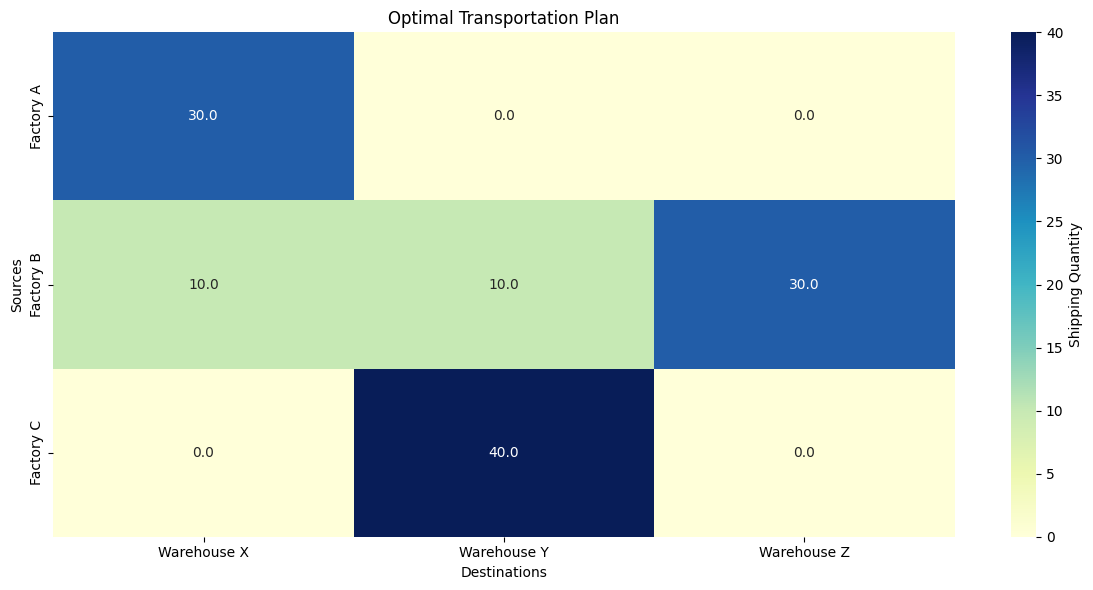
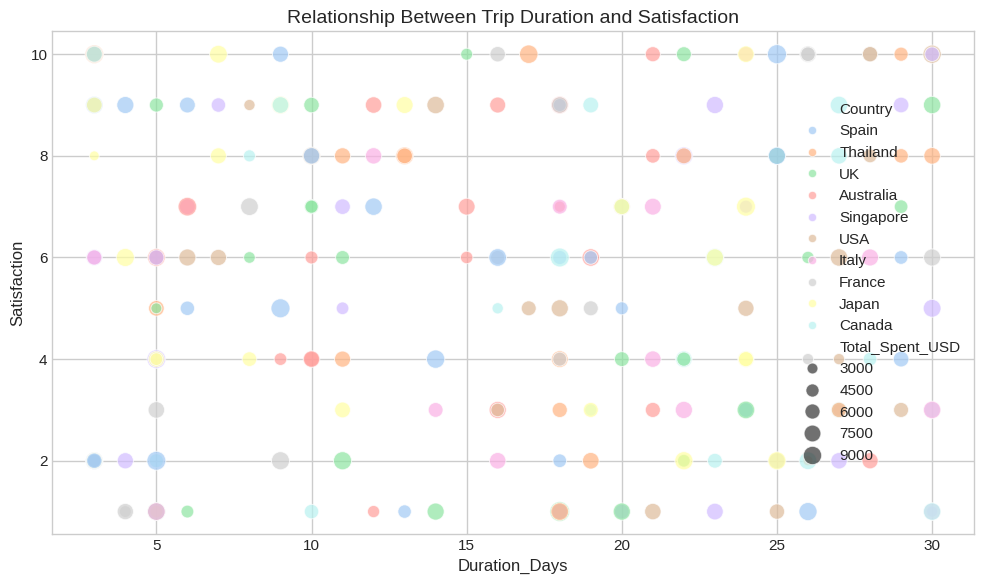
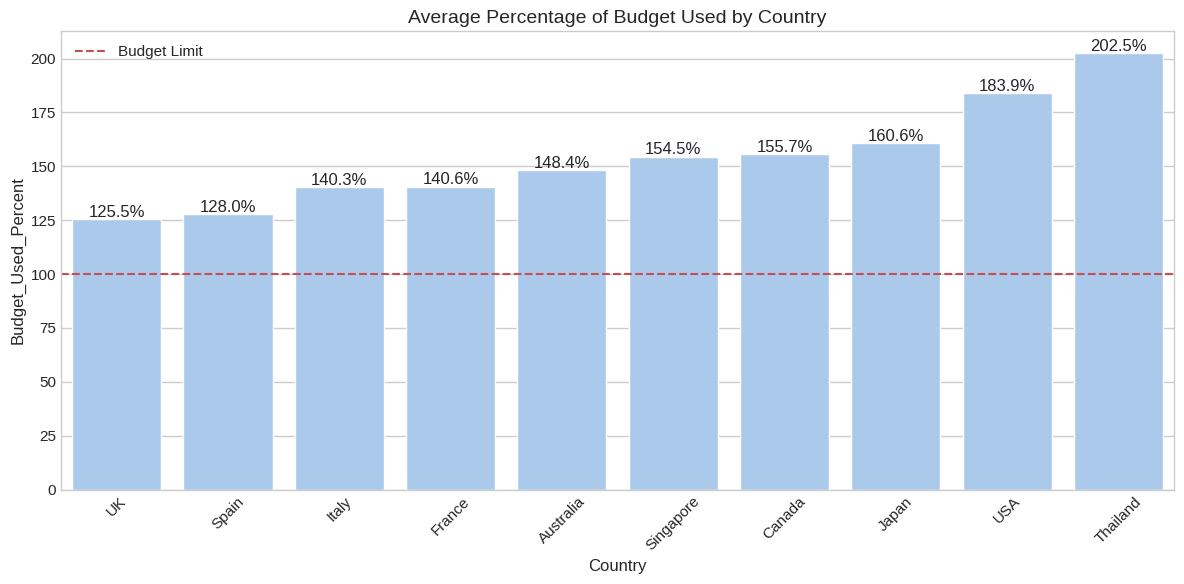
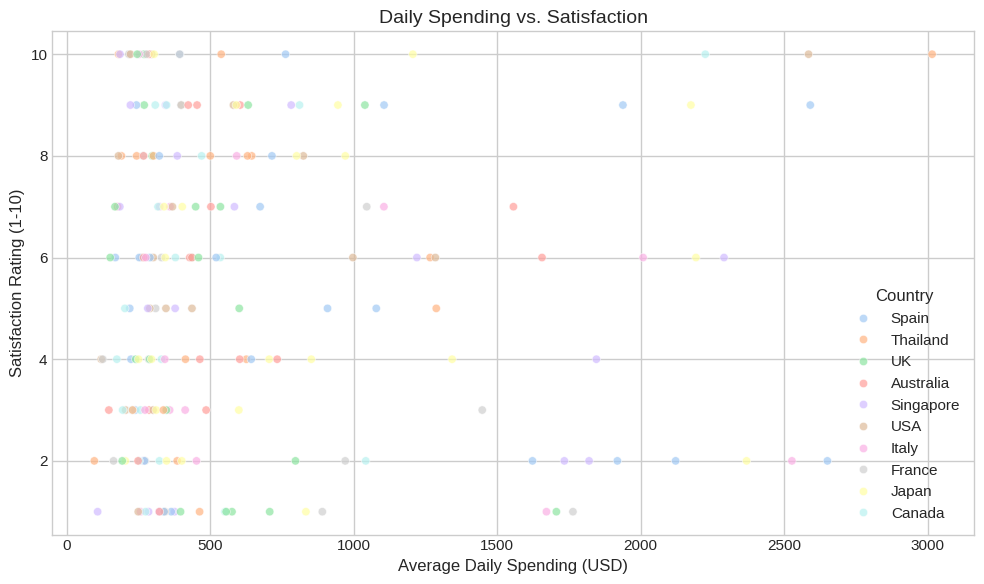
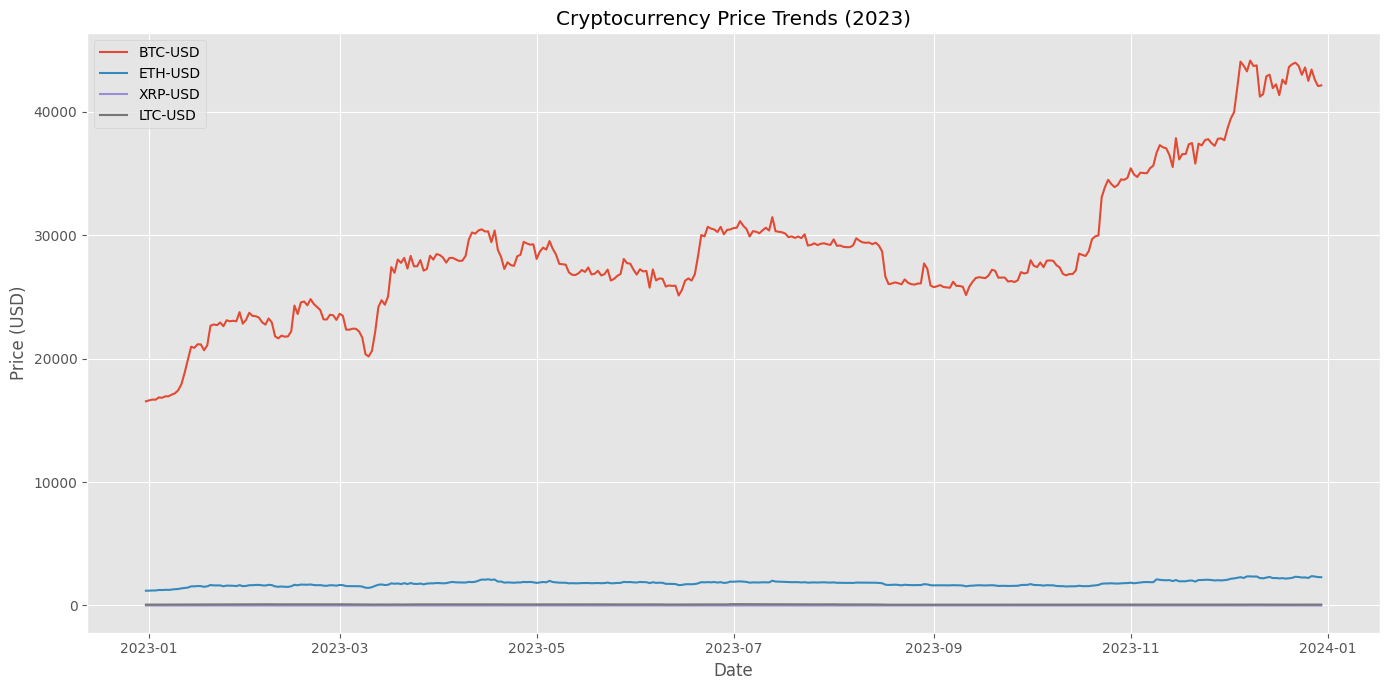
Example Problem in Differential Geometry
Let’s consider a classic problem in differential geometry: finding the geodesic (shortest path) on a unit sphere.
A geodesic on a sphere is a great circle, and we’ll derive its equation using the Euler-Lagrange equations from the calculus of variations.
Then, we’ll solve it numerically in $Python$ and visualize the result.
Problem Statement
On a unit sphere parameterized by spherical coordinates $(\theta, \phi)$, where $\theta$ is the polar angle and $\phi$ is the azimuthal angle, the metric is given by:
$$
ds^2 = d\theta^2 + \sin^2\theta , d\phi^2
$$
We want to find the geodesic between two points, say $(\theta_1, \phi_1) = (0.5, 0)$ and $(\theta_2, \phi_2) = (1.0, 1.0)$, by minimizing the arc length functional:
$$
S = \int_{t_1}^{t_2} \sqrt{\dot{\theta}^2 + \sin^2\theta , \dot{\phi}^2} , dt
$$
where $\dot{\theta} = \frac{d\theta}{dt}$ and $\dot{\phi} = \frac{d\phi}{dt}$.
Step 1: Euler-Lagrange Equations
The Lagrangian is:
$$
L = \sqrt{\dot{\theta}^2 + \sin^2\theta , \dot{\phi}^2}
$$
The Euler-Lagrange equations for $\theta$ and $\phi$ are:
$$
\frac{d}{dt} \left( \frac{\partial L}{\partial \dot{\theta}} \right) = \frac{\partial L}{\partial \theta}, \quad \frac{d}{dt} \left( \frac{\partial L}{\partial \dot{\phi}} \right) = \frac{\partial L}{\partial \phi}
$$
Computing the partial derivatives:
- $\frac{\partial L}{\partial \dot{\theta}} = \frac{\dot{\theta}}{\sqrt{\dot{\theta}^2 + \sin^2\theta , \dot{\phi}^2}}$
- $\frac{\partial L}{\partial \dot{\phi}} = \frac{\sin^2\theta , \dot{\phi}}{\sqrt{\dot{\theta}^2 + \sin^2\theta , \dot{\phi}^2}}$
- $\frac{\partial L}{\partial \theta} = \frac{\sin\theta \cos\theta , \dot{\phi}^2}{\sqrt{\dot{\theta}^2 + \sin^2\theta , \dot{\phi}^2}}$
- $\frac{\partial L}{\partial \phi} = 0$ (since $L$ does not depend explicitly on $\phi$)
Since $\frac{\partial L}{\partial \phi} = 0$, the second equation implies that $\frac{\partial L}{\partial \dot{\phi}}$ is a constant, which is a conserved quantity (related to angular momentum).
This simplifies to Clairaut’s relation for the sphere:
$$
\sin^2\theta , \dot{\phi} = \text{constant}
$$
However, solving these analytically is complex, so we’ll use numerical integration in $Python$.
Step 2: Python Code
We’ll use scipy.integrate.odeint to solve the differential equations numerically, then plot the geodesic on the sphere.
1 | import numpy as np |
Code Explanation
- Imports: We use
numpyfor numerical operations,scipy.integrate.odeintfor solving ODEs, andmatplotlibfor 3D plotting. - Geodesic Function: Defines the system of first-order ODEs derived from the Euler-Lagrange equations.
We convert the second-order equations into four first-order equations: $\theta$, $\phi$, $\dot{\theta}$, and $\dot{\phi}$. - Initial Conditions: We set the starting point $(\theta_1, \phi_1) = (0.5, 0)$ and guess initial velocities.
In practice, these velocities would be adjusted to hit the target point $(\theta_2, \phi_2) = (1.0, 1.0)$, but for simplicity, we demonstrate the method. - Numerical Solution:
odeintsolves the ODE system over the parameter $t$. - Visualization: We convert spherical coordinates to Cartesian coordinates $(x = \sin\theta \cos\phi$, $y = \sin\theta \sin\phi$, $z = \cos\theta$) and plot the geodesic on a semi-transparent unit sphere.
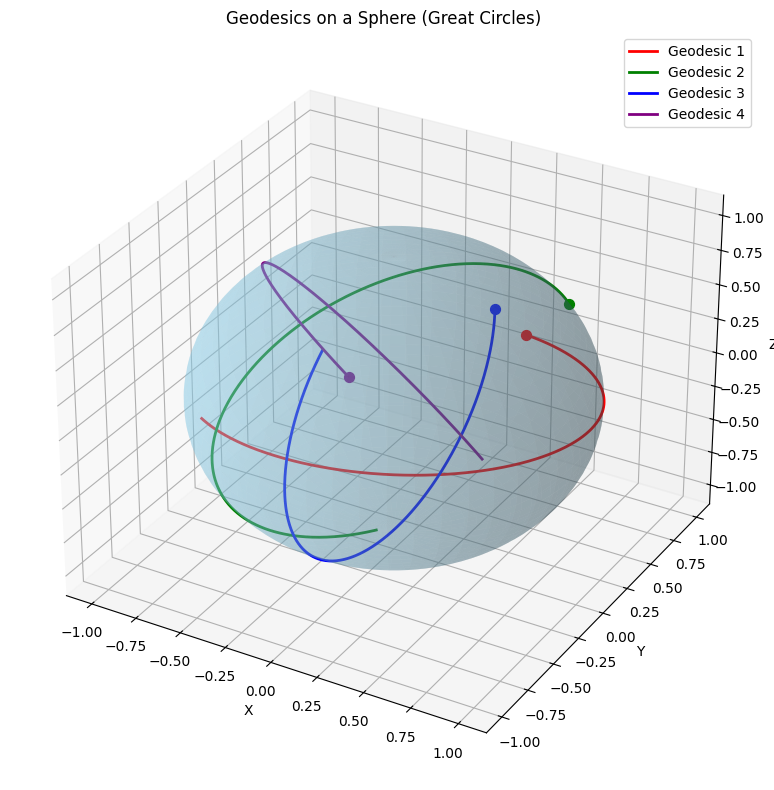
Result and Visualization Explanation
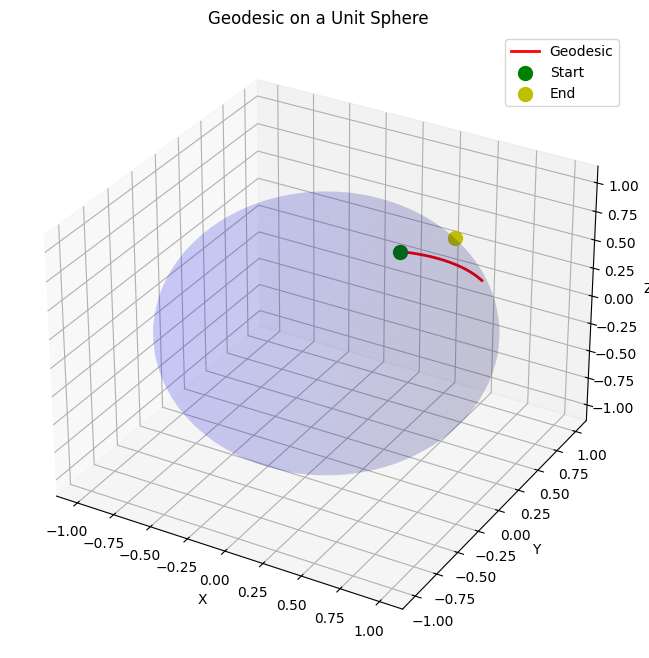
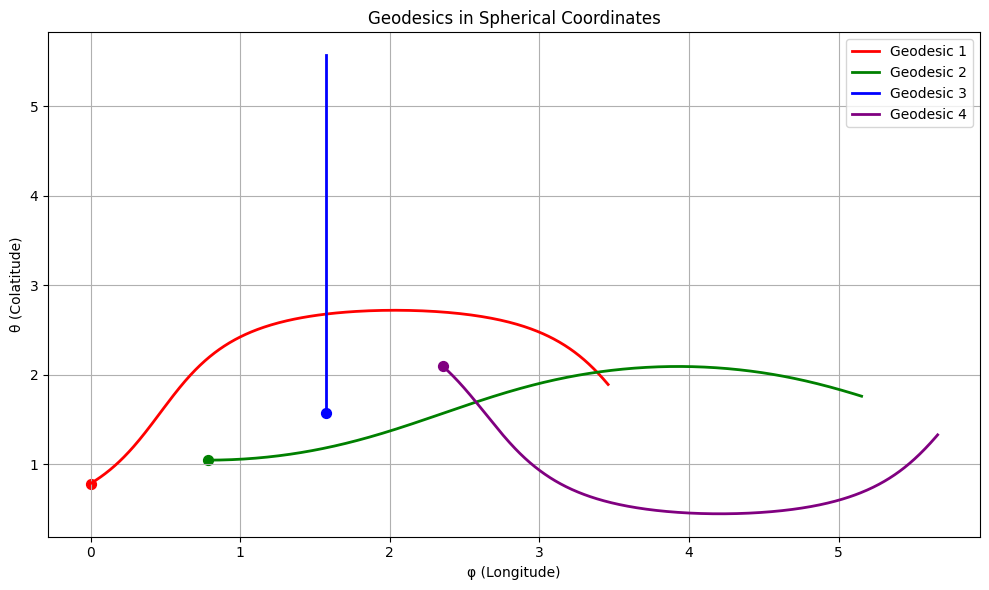
- The plot shows a unit sphere (blue, semi-transparent) with the geodesic (red curve) connecting the start point (green dot) and an approximate end point (yellow dot).
- The geodesic is a segment of a great circle, the shortest path on the sphere.
- Note: The initial velocities here are illustrative.
To precisely hit $(\theta_2, \phi_2)$, you’d need a boundary value problem solver (e.g.,scipy.integrate.solve_bvp), but this demonstrates the concept.
This visualization makes it clear how geodesics behave on curved surfaces, a fundamental concept in differential geometry!