
乳がんの診断(ランダムフォレストモデル)
乳がんの診断(良性、悪性)を予測するためのランダムフォレストモデルを作ります。
scikit-learnの乳がんデータセットを利用します。
データセットの分割とランダムフォレストモデルの訓練を行い、最後にテストデータを使って予測の精度を計測・表示します。
1 | from sklearn.datasets import load_breast_cancer |
[実行結果]
Model accuracy: 96.49%
次に、診断の重要度を評価し、それを可視化します。
この可視化は、どの特徴が乳がんの診断に最も重要であるかを理解するのに役立ちます。
1 | import numpy as np |
[実行結果]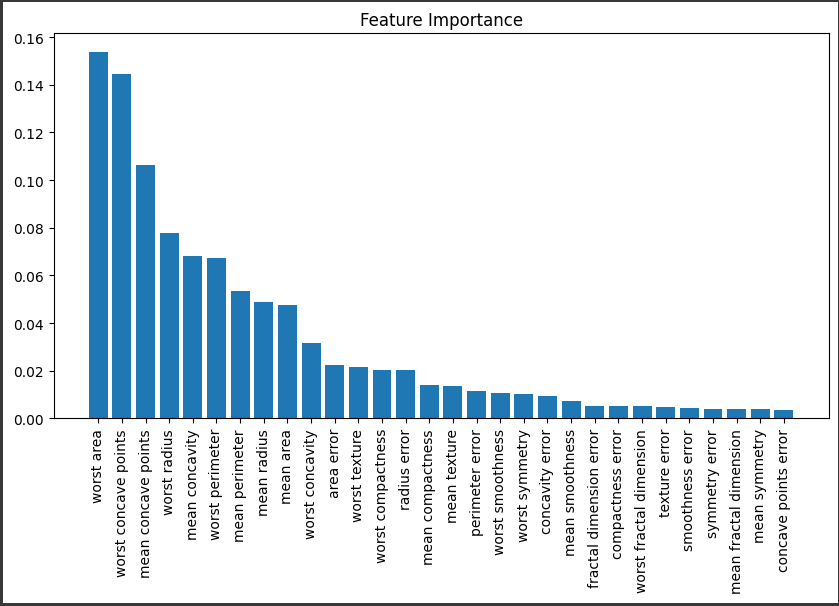
最後に、テストデータの正解ラベルと予測ラベルを比較します。
これによりモデルがどの程度のパフォーマンスを発揮しているかを視覚的に理解することができます。
1 | # テストデータの予測 |
[実行結果]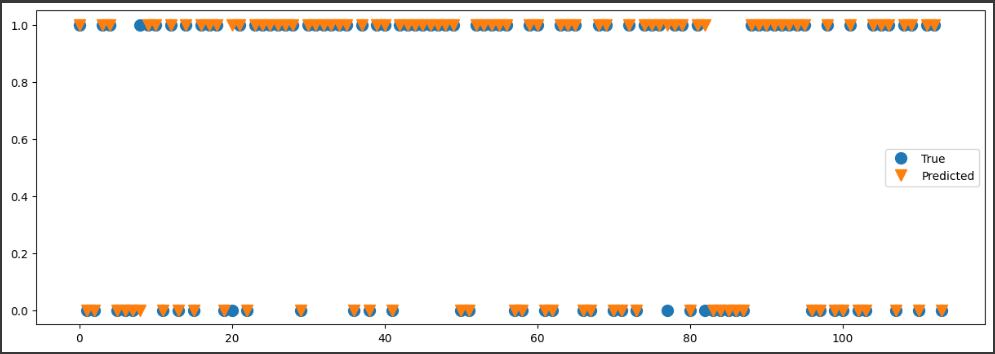
以上のステップで、乳がん診断のためのランダムフォレストモデルの学習と評価を行い、結果を視覚化しました。
ソースコード解説
このコードは乳がんデータセットを使用し、ランダムフォレストを使って腫瘍が良性か悪性かを分類する機械学習モデルを訓練しています。
1. データの読み込みと分割:
load_breast_cancerで乳がんデータセットを読み込み、特徴量(X)とターゲット(y)を取得します。train_test_splitを使ってデータをトレーニング用とテスト用に分割します。
2. モデルの訓練:
- ランダムフォレスト分類器(
RandomForestClassifier)を使って、トレーニングデータでモデルを訓練します。
3. モデルの評価:
- テストデータで訓練されたモデルの性能を評価し、精度(accuracy)を表示します。
4. 特徴量の重要度のプロット:
feature_importances_を使用して、各特徴量の重要度を取得します。- 重要度の高い特徴量を降順にソートし、特徴量の名前とともにバーのプロットを作成します。
5. 予測結果の可視化:
- テストデータでの実際のターゲット値(
y_test)と予測値(y_pred)をプロットして比較します。
このコードは、ランダムフォレストを使った分類タスクの全体的な流れを示しています。
データの読み込みから特徴量の重要度の可視化まで、モデル構築から評価までの一連のステップを示しています。
結果解説
[実行結果]
このグラフは、ランダムフォレストクラシフィケーションモデルを用いて特徴量の重要度を視覚化したものです。
グラフの各バーは一つひとつの特徴量を表し、その長さ(高さ)はその特徴量のランダムフォレスト内での相対的な重要度を示しています。
特徴量の重要度は、その特徴が何回スプリットに利用され、それらの分割がどれだけ不純物(通常はジニ不純度またはエントロピー)を減らすのに寄与したかを基づいて計算されます。
x軸上には特徴量の名前が表示され、これらはその重要度に基づいて左から右へと並べられています。
最も重要な特徴量が左側に表示され、重要度が低いものが右側へと続きます。
ばらつきの大きい特徴量は、対象とする問題において重要な役割を果たすことが多いです。
これらの特徴量を特定することで、データの理解が深まり、より効果的な特徴エンジニアリング戦略を考える上でも有効です。
なお、このソースコードは乳がんの診断に関するデータセットを対象としているため、特徴量は乳がんの診断に関連する一連の医学的測定値を指します。
例えば、細胞の形やサイズ、細胞核の形状などがこれに該当します。
[実行結果]
このグラフは、予測結果と実際の結果を視覚化したものです。
テストデータに対して予測がどのように行われ、その結果がどの程度実際の目標値に一致しているかを判断するためのものです。
“True”ライン:
これはy_testの値をプロットしたもので、テストデータの真のラベル(クラス)がどのように分布しているかを示しています。
これは「正解」の分布を示す基準線となります。
“Predicted”ライン:
これはy_predの値をプロットしたもので、モデルがテストデータをどのように予測したかを示します。
これはモデルの「予測」の分布を示しており、こちらが“True”ラインとどの程度一致しているかが、モデルの性能を評価するための主要な視覚的指標となります。
点のy軸の位置はクラスラベルを示し、x軸の位置は各データポイントを示しています。
ここでは二項分類問題を扱っており、各クラス(良性、悪性)はそれぞれ$0$と$1$でラベル付けされています。
したがって、予測が真のラベルと一致する場合、“True”点と”Predicted”の点は同じy座標に配置されます。
逆に、予測が真のラベルと一致しない場合、“True”点と”Predicted”点は異なるy座標に存在します。
このタイプのグラフはモデルの具体的なミスを視覚的に把握するのに役立ちます。
例えば、一部のデータポイントで予測が一貫して外れている場合、それはそのデータポイントが何らかの特定のパターンを有しており、それがモデルにとって難しいか、または学習データ内で不足している可能性を示しています。