Example
Beam deflection is an important topic in structural engineering.
In this example, we will analyze the deflection of a simply supported beam subjected to a uniformly distributed load.
Problem Statement
A simply supported beam of length $( L = 10 )$ meters is subjected to a uniformly distributed load $( w = 5 )$ $kN/m$.
The flexural rigidity of the beam is $( EI = 2 \times 10^9 ) Nm(^2)$.
The beam follows the Euler-Bernoulli beam equation:
$$
\frac{d^4 y}{dx^4} = \frac{w}{EI}
$$
- $ y(x) $ is the deflection of the beam at position $ x $,
- $ w $ is the uniformly distributed load $kN/m$,
- $ EI $ is the flexural rigidity of the beam $Nm(^2)$,
- $ x $ is the position along the beam $m$.
Using boundary conditions:
- $ y(0) = 0 $, $ y(L) = 0 $ (simply supported ends),
- $ y’’(0) = 0 $, $ y’’(L) = 0 $ (no moment at the supports),
we solve for the deflection $ y(x) $.
Python Implementation
1 | import numpy as np |
Explanation
Beam Deflection Equation:
- The function
beam_deflection(x)computes deflection using the analytical solution of the Euler-Bernoulli beam equation.
- The function
Computing Deflection:
- The formula is applied to various positions along the beam to determine the deflection profile.
Visualization:
- The graph shows how the beam bends under load.
- The maximum deflection occurs at the center of the beam.
Results and Interpretation
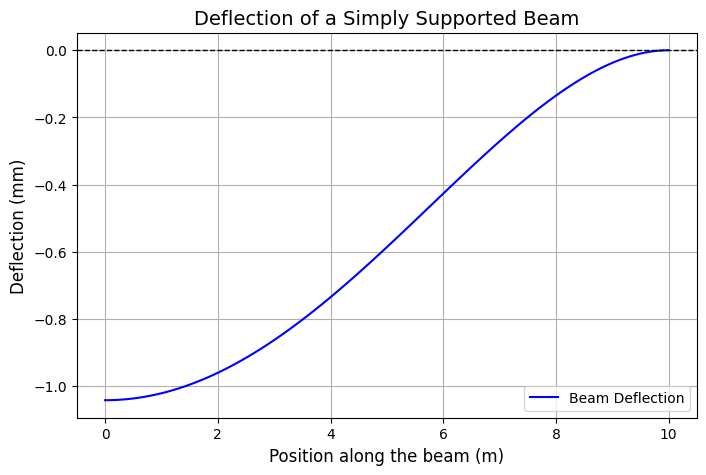
Maximum Deflection: -1.04 mm at x = 5.0 m
- The maximum deflection occurs at $( x = L/2 = 5 )$ meters.
- Computed maximum deflection:
$$
\approx -1.04 \text{ mm}
$$
(negative sign indicates downward deflection).
This example demonstrates how to solve and visualize a classic engineering mechanics problem using $Python$.