
非線形回帰モデル
非線形回帰モデルを使用してデータを解析し、モデルの評価と解釈を行う例を挙げます。
この例では、非線形な関数に基づいたデータを生成し、statsmodelsを使用して非線形回帰を行います。
1 | import numpy as np |
このコードでは、非線形な関数に基づいたデータを生成し、それに対して非線形回帰モデルを構築しています。
statsmodelsのOLSクラスを使用してモデルを構築し、多項式項を追加して非線形性をモデル化しています。
モデルの概要を表示し、実際のデータと予測値をプロットしています。
この例では、非線形な関数を適切にモデル化し、その結果を詳細に解釈するために必要な手順を示しています。
非線形回帰は通常、複雑な現象や関係性をモデル化するために使用されます。
ソースコード解説
このコードは、非線形な回帰モデルを使用してサンプルデータを解析し、結果を表示するためのプログラムです。
以下に、各部分の詳細な説明を示します。
1. サンプルデータの生成:
1 | np.random.seed(42) |
np.linspace(0, 10, 100): 0から10までの範囲を100等分した数値を生成し、変数Xに格納します。
これは x 軸の値として使用されます。2 * np.sin(X) + 0.5 * X + np.random.normal(scale=0.5, size=len(X)): サイン関数に基づく非線形な関数にノイズが加えられたデータが変数yに格納されます。
これが実際の目的変数です。
2. データフレームの作成:
1 | data = pd.DataFrame({'X': X, 'y': y}) |
- NumPyの配列を使用して、
Xとyを列として持つ Pandas のデータフレームdataを作成します。
3. 非線形回帰モデルの構築:
1 | X_poly = sm.add_constant(np.column_stack((X, X**2))) |
sm.add_constant: 定数項をデザイン行列に追加します。np.column_stack((X, X**2)):XとXの2乗の列を結合して多項式項を作成します。sm.OLS(y, X_poly): 最小二乗法(OLS)を使用して、目的変数yと説明変数X_polyからなる非線形回帰モデルを作成します。
4. モデルの適合:
1 | results = model.fit() |
fitメソッドを使用して、モデルをデータに適合させます。
5. モデルの概要を表示:
1 | print(results.summary()) |
results.summary()を使用して、回帰モデルの統計的な概要を表示します。
この中には回帰係数、統計的な有意性、R-squared(決定係数)などが含まれます。
6. データと予測値のプロット:
1 | fig, ax = plt.subplots(figsize=(8, 6)) |
plt.subplots(figsize=(8, 6)): 8x6のサイズのプロット領域を作成します。- 実際のデータ点と回帰モデルに基づく予測値をプロットします。
- プロットのラベルや凡例を追加しています。
plt.show(): プロットを表示します。
このコードは、非線形な回帰モデルを構築し、その結果を可視化する基本的な流れを示しています。
モデルの詳細な統計的な評価は、results.summary()を通じて得られます。
結果解説
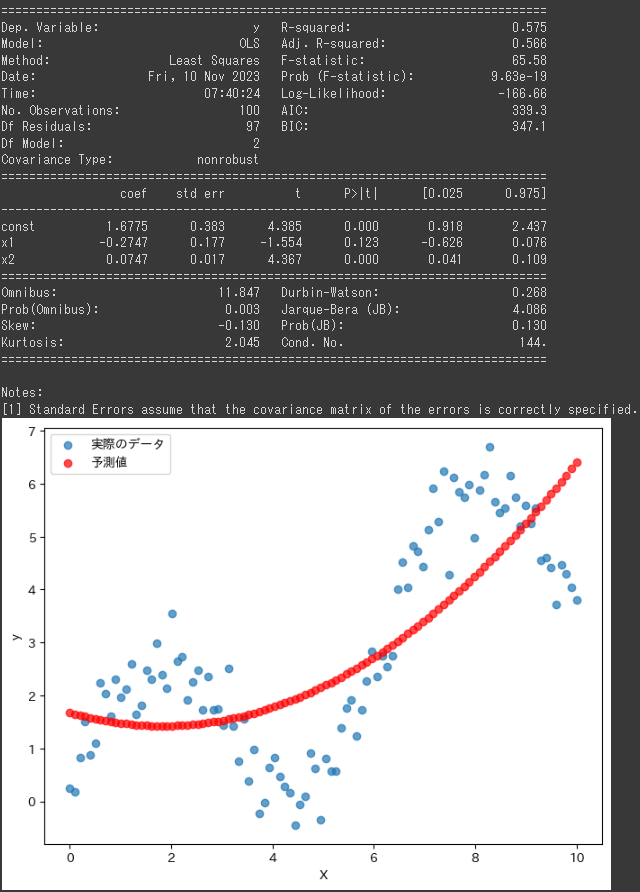
このコードのグラフは、非線形な回帰モデルに基づくデータの実際の値と予測値を視覚的に比較しています。
以下に、各要素の詳細な説明を示します。
1. 実際のデータの散布図 (青色の点):
- x軸は変数
Xを表し、y軸は目的変数yを表しています。 - 各青い点は、生成された非線形データの実際の値を示しています。
- ノイズが加えられた sin 関数と線形項(0.5 * X)に基づいてデータが生成されました。
2. 予測値の散布図 (赤色の点):
- x軸は変数
Xを表し、y軸は回帰モデルに基づく予測値を表しています。 - 各赤い点は、モデルが与えた変数
Xに対する予測値を示しています。
このグラフを通じて、実際のデータとモデルの予測がどれだけよく一致しているかを確認できます。
モデルがデータにどれくらいよく適合しているかを把握するためには、実際のデータと予測値の一致度を評価する指標や、残差のプロットなどを用いることがあります。