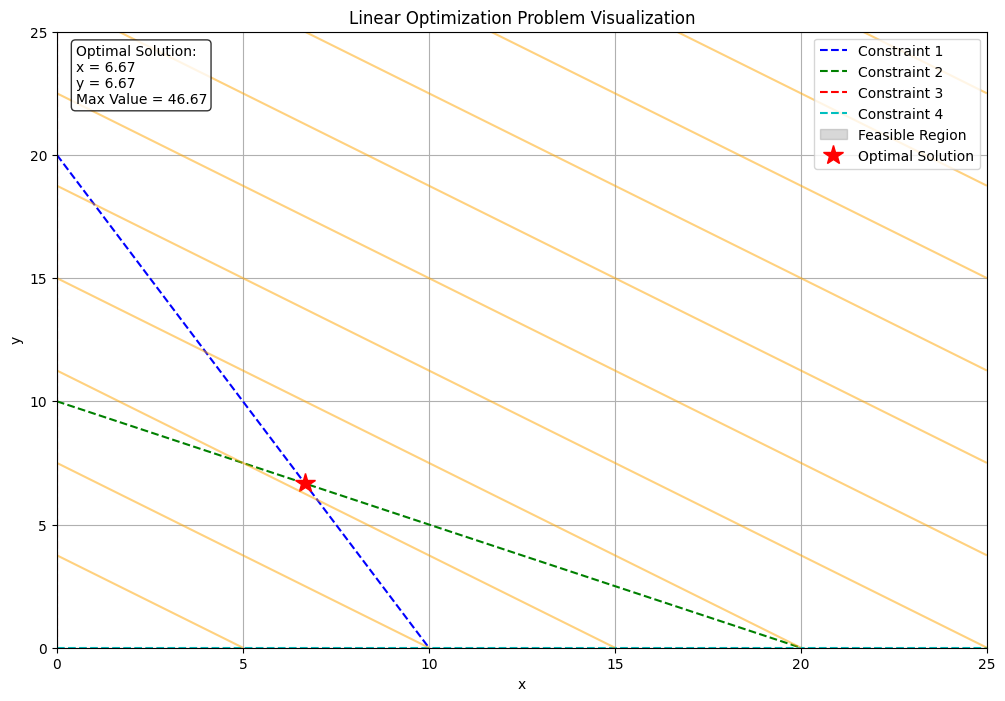
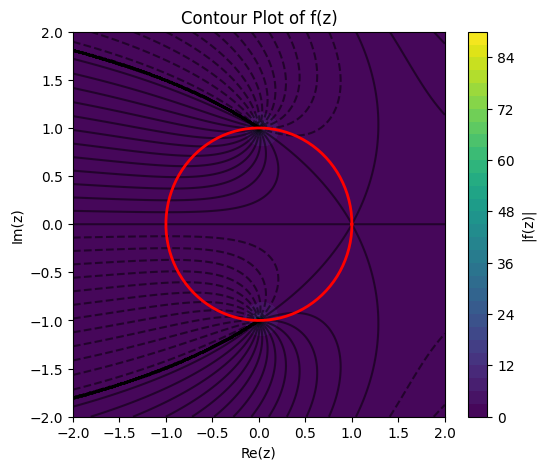
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
| import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import odeint
from matplotlib.animation import FuncAnimation
def double_pendulum_equations(state, t, L1, L2, m1, m2, g):
"""
Derive differential equations for double pendulum motion
State vector: [θ1, ω1, θ2, ω2]
θ1, θ2: angular positions of pendulums
ω1, ω2: angular velocities
"""
theta1, omega1, theta2, omega2 = state
delta = theta2 - theta1
den1 = (m1 + m2) * L1 - m2 * L1 * np.cos(delta) * np.cos(delta)
den2 = (L2/L1) * den1
alpha1 = (-m2 * L1 * omega1 * omega1 * np.sin(delta) * np.cos(delta)
+ g * (m2 * np.sin(theta2) * np.cos(delta) - (m1 + m2) * np.sin(theta1))
- m2 * L2 * omega2 * omega2 * np.sin(delta)) / den1
alpha2 = (L1/L2) * (m2 * L1 * omega1 * omega1 * np.sin(delta) * np.cos(delta)
+ g * (m1 + m2) * np.sin(theta1) * np.cos(delta)
- (m1 + m2) * g * np.sin(theta2)
+ (m1 + m2) * L1 * omega1 * omega1 * np.sin(delta)) / den2
return [omega1, alpha1, omega2, alpha2]
L1, L2 = 1.0, 1.0
m1, m2 = 1.0, 1.0
g = 9.81
t = np.linspace(0, 20, 1000)
initial_states = [
[np.pi/2, 0, np.pi/2, 0],
[np.pi/3, 0, np.pi/4, 0],
[0.1, 0, 0.2, 0]
]
solutions = []
for initial_state in initial_states:
solution = odeint(double_pendulum_equations, initial_state, t,
args=(L1, L2, m1, m2, g))
solutions.append(solution)
fig = plt.figure(figsize=(15, 10))
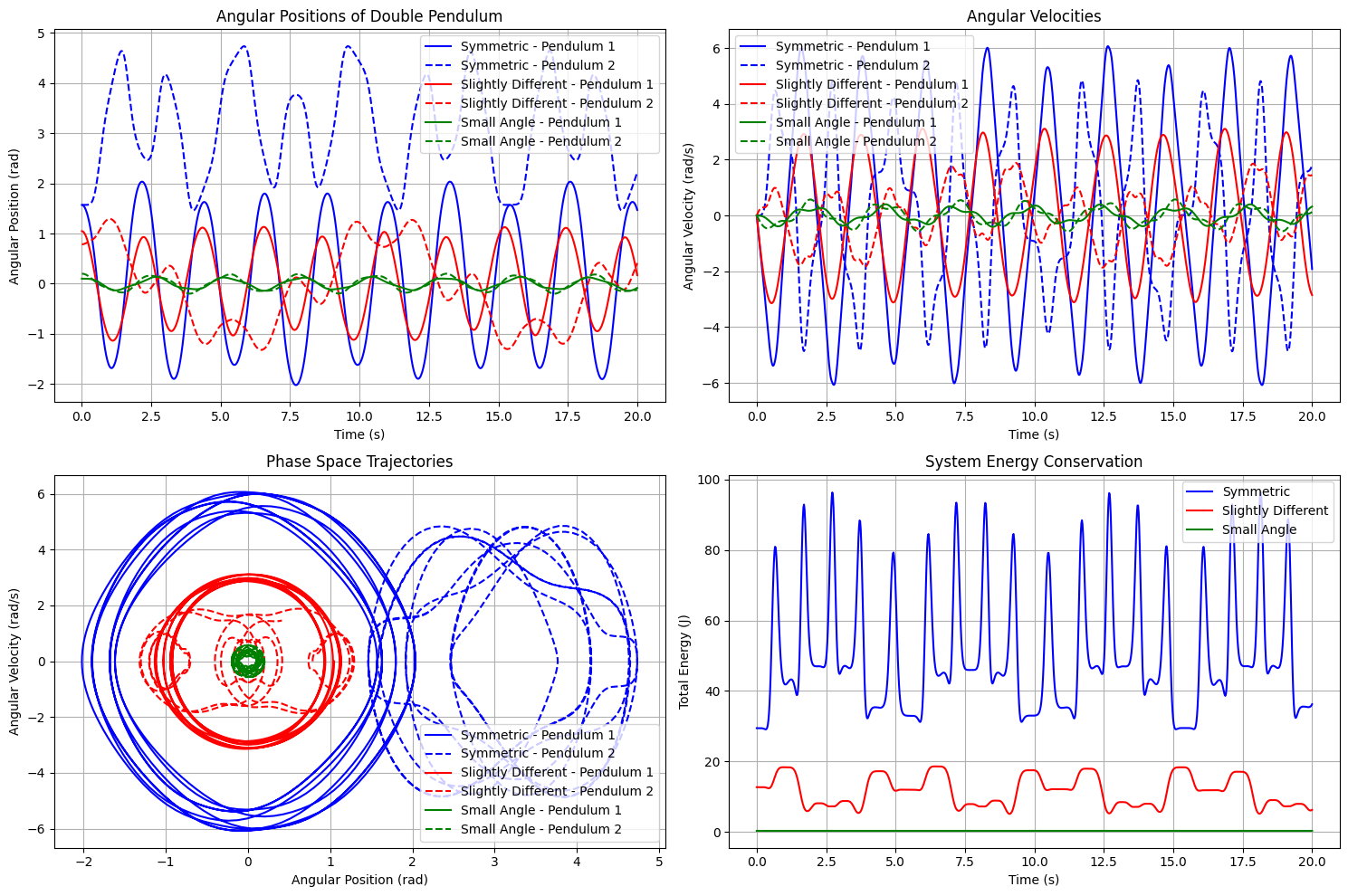
ax1 = fig.add_subplot(221)
colors = ['blue', 'red', 'green']
labels = ['Symmetric', 'Slightly Different', 'Small Angle']
for i, sol in enumerate(solutions):
ax1.plot(t, sol[:, 0], colors[i], label=f'{labels[i]} - Pendulum 1')
ax1.plot(t, sol[:, 2], colors[i], linestyle='--', label=f'{labels[i]} - Pendulum 2')
ax1.set_xlabel('Time (s)')
ax1.set_ylabel('Angular Position (rad)')
ax1.set_title('Angular Positions of Double Pendulum')
ax1.legend()
ax1.grid(True)
ax2 = fig.add_subplot(222)
for i, sol in enumerate(solutions):
ax2.plot(t, sol[:, 1], colors[i], label=f'{labels[i]} - Pendulum 1')
ax2.plot(t, sol[:, 3], colors[i], linestyle='--', label=f'{labels[i]} - Pendulum 2')
ax2.set_xlabel('Time (s)')
ax2.set_ylabel('Angular Velocity (rad/s)')
ax2.set_title('Angular Velocities')
ax2.legend()
ax2.grid(True)
ax3 = fig.add_subplot(223)
for i, sol in enumerate(solutions):
ax3.plot(sol[:, 0], sol[:, 1], colors[i], label=f'{labels[i]} - Pendulum 1')
ax3.plot(sol[:, 2], sol[:, 3], colors[i], linestyle='--', label=f'{labels[i]} - Pendulum 2')
ax3.set_xlabel('Angular Position (rad)')
ax3.set_ylabel('Angular Velocity (rad/s)')
ax3.set_title('Phase Space Trajectories')
ax3.legend()
ax3.grid(True)
ax4 = fig.add_subplot(224)
for i, sol in enumerate(solutions):
PE1 = m1 * g * L1 * (1 - np.cos(sol[:, 0]))
PE2 = m2 * g * (L1 * (1 - np.cos(sol[:, 0])) + L2 * (1 - np.cos(sol[:, 2])))
KE1 = 0.5 * m1 * (L1 * sol[:, 1])**2
KE2 = 0.5 * m2 * ((L1 * sol[:, 1])**2 + (L2 * sol[:, 3])**2 +
2 * L1 * L2 * sol[:, 1] * sol[:, 3] * np.cos(sol[:, 0] - sol[:, 2]))
total_energy = PE1 + PE2 + KE1 + KE2
ax4.plot(t, total_energy, colors[i], label=labels[i])
ax4.set_xlabel('Time (s)')
ax4.set_ylabel('Total Energy (J)')
ax4.set_title('System Energy Conservation')
ax4.legend()
ax4.grid(True)
plt.tight_layout()
plt.show()
print("\nDouble Pendulum Chaotic Motion Analysis:")
print("-" * 50)
print("System Parameters:")
print(f"Pendulum 1 Length: {L1} m")
print(f"Pendulum 2 Length: {L2} m")
print(f"Pendulum 1 Mass: {m1} kg")
print(f"Pendulum 2 Mass: {m2} kg")
print(f"Gravitational Acceleration: {g} m/s²")
for i, (label, sol) in enumerate(zip(labels, solutions)):
print(f"\n{label} Initial Condition:")
max_angle1 = np.max(np.abs(sol[:, 0]))
max_angle2 = np.max(np.abs(sol[:, 2]))
max_vel1 = np.max(np.abs(sol[:, 1]))
max_vel2 = np.max(np.abs(sol[:, 3]))
print(f"Maximum Angle 1: {max_angle1:.2f} rad")
print(f"Maximum Angle 2: {max_angle2:.2f} rad")
print(f"Maximum Angular Velocity 1: {max_vel1:.2f} rad/s")
print(f"Maximum Angular Velocity 2: {max_vel2:.2f} rad/s")
|