
線形回帰モデル(燃費)
scikit-learnを使用して、線形回帰モデルを作成してみましょう。
以下は、燃費データを使って車の燃費を予測する例です。
1 | import pandas as pd |
このコードでは、UCI Machine Learning Repositoryから車の燃費データを読み込み、線形回帰モデルを用いて車の燃費(MPG)を予測します。
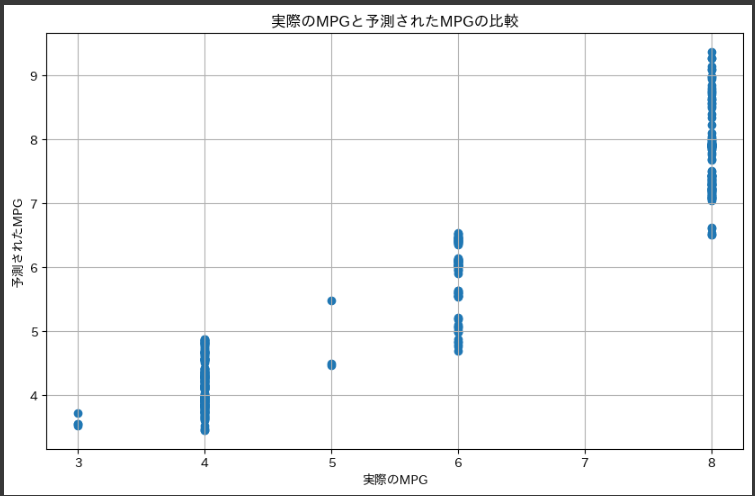
そして、実際のMPGと予測されたMPGの比較を散布図として表示しています。
ソースコード解説
このコードは、以下の手順で車の燃費(MPG)データを分析し、線形回帰モデルを作成しています。
データの読み込みと前処理
- UCI Machine Learning Repositoryから車の燃費データをダウンロードし、Pandasを使って読み込みます。
- データにはカラム名がないので、カラム名を定義しています。
- 欠損値が含まれる可能性があるため、欠損値を含む行を削除します。
特徴量とターゲットの選択
- 説明変数(特徴量)と目的変数(ターゲット)を選択します。
ここでは、車の性能に関連する特徴量(気筒数、排気量、馬力、重量、加速度)を特徴量として選択し、燃費(MPG)を目的変数として選択しています。
モデルの訓練
- scikit-learnの
LinearRegression()を使用して線形回帰モデルを作成し、特徴量と目的変数を使ってモデルを訓練します。
予測と実際の値の比較
- 訓練済みモデルを使って、特徴量から燃費(MPG)を予測します。
- 実際の燃費と予測された燃費の関係を比較するため、散布図を作成しています。
グラフ化
- 予測されたMPGと実際のMPGを散布図で表示しており、x軸が実際のMPG、y軸が予測されたMPGを示しています。
- グラフのタイトルや軸ラベルが追加されており、グリッドが表示されています。
結果解説
このグラフは、実際の燃費(実際のMPG)と機械学習モデルによって予測された燃費(予測されたMPG)の関係を示しています。
各点は、個々の車両に対しての実際の燃費とモデルによる予測のペアを表しています。
x軸は実際のMPGを示し、y軸はそれに対する機械学習モデルによる予測されたMPGを表しています。
各点が45度の直線に近い位置に集中している場合、予測が実際の値とほぼ同じであることを意味します。
グラフ全体が45度の直線に近い形をしている場合、モデルが実際の値と良好に一致して予測していることを示し、点が直線から離れてばらつきが大きい場合、予測が実際の値との間で大きくズレていることを示します。