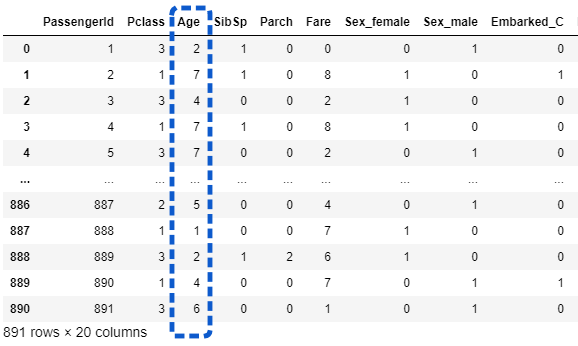
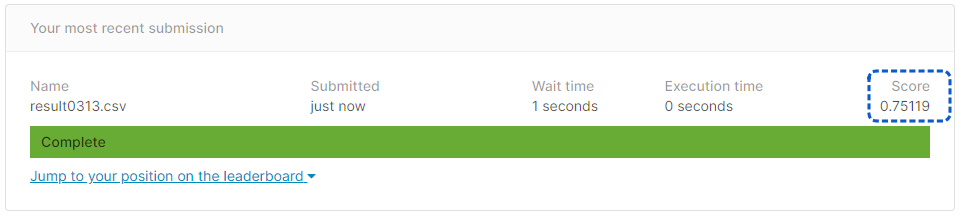
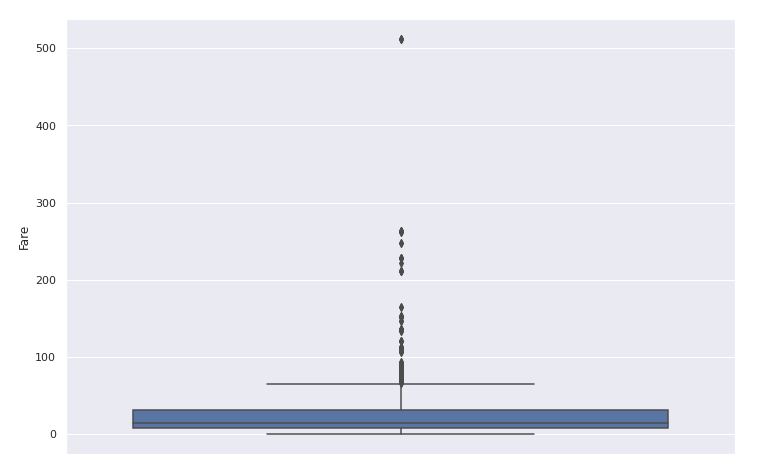
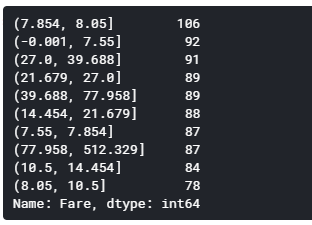
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
| import pandas as pd
import numpy as np
Dead_list = []
Survived_list = []
def age_trans(df):
# Age を Pclass, Sex, Parch, SibSp からランダムフォレストで推定
from sklearn.ensemble import RandomForestRegressor
# 推定に使用する項目を指定
age_df = df[['Age', 'Pclass','Sex','Parch','SibSp']]
# ラベル特徴量をワンホットエンコーディング
age_df=pd.get_dummies(age_df)
# 学習データとテストデータに分離し、numpyに変換
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# 学習データをX, yに分離
X = known_age[:, 1:]
y = known_age[:, 0]
# ランダムフォレストで推定モデルを構築
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
# 推定モデルを使って、テストデータのAgeを予測し、補完
predictedAges = rfr.predict(unknown_age[:, 1::])
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df
def make_list(df):
global Dead_list
global Survived_list
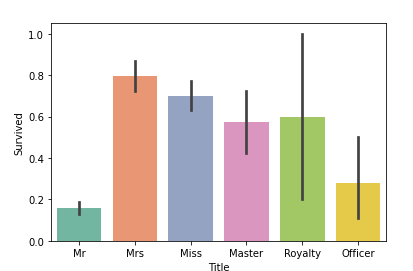
# Nameから敬称(Title)を抽出し、グルーピング
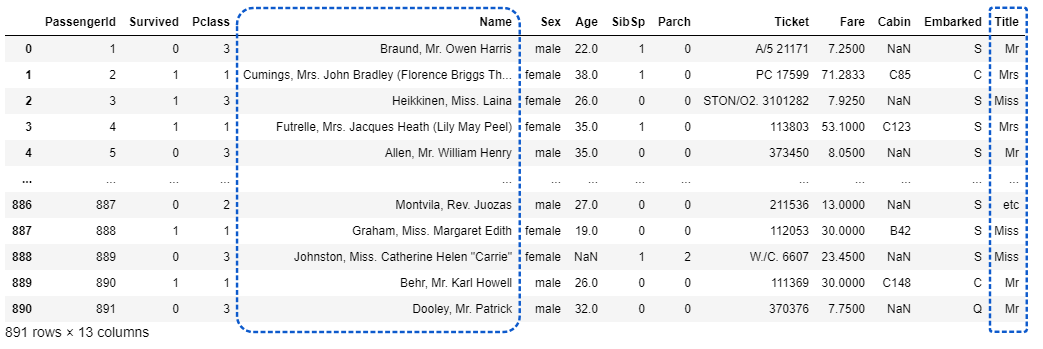
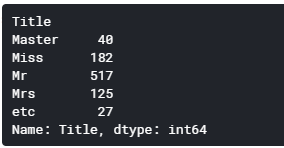
df['Title'] = df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona', 'Jonkheer'], 'Royalty', inplace=True)
df['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['Title'].replace(['Mlle'], 'Miss', inplace=True)
# NameからSurname(苗字)を抽出
df['Surname'] = df['Name'].map(lambda name:name.split(',')[0].strip())
# 同じSurname(苗字)の出現頻度をカウント(出現回数が2以上なら家族)
df['FamilyGroup'] = df['Surname'].map(df['Surname'].value_counts())
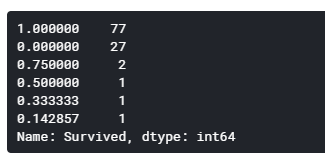
# 家族で16才以下または女性の生存率
Female_Child_Group=df.loc[(df['FamilyGroup']>=2) & ((df['Age']<=16) | (df['Sex']=='female'))]
Female_Child_Group=Female_Child_Group.groupby('Surname')['Survived'].mean()
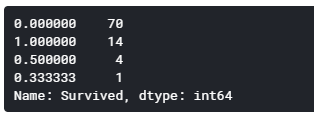
# 家族で16才超えかつ男性の生存率
Male_Adult_Group=df.loc[(df['FamilyGroup']>=2) & (df['Age']>16) & (df['Sex']=='male')]
Male_Adult_List=Male_Adult_Group.groupby('Surname')['Survived'].mean()
# デッドリストとサバイブリストの作成
Dead_list=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
Survived_list=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
def trans_by_list(df):
# Nameから敬称(Title)を抽出し、グルーピング
df['Title'] = df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona', 'Jonkheer'], 'Royalty', inplace=True)
df['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['Title'].replace(['Mlle'], 'Miss', inplace=True)
# NameからSurname(苗字)を抽出
df['Surname'] = df['Name'].map(lambda name:name.split(',')[0].strip())
# 同じSurname(苗字)の出現頻度をカウント(出現回数が2以上なら家族)
df['FamilyGroup'] = df['Surname'].map(df['Surname'].value_counts())
# デッドリストとサバイブリストをSex, Age, Title に反映させる
df.loc[(df['Surname'].apply(lambda x:x in Dead_list)), ['Sex','Age','Title']] = ['male',28.0,'Mr']
df.loc[(df['Surname'].apply(lambda x:x in Survived_list)), ['Sex','Age','Title']] = ['female',5.0,'Mrs']
return df
# データ前処理
def preprocessing(df):
df = age_trans(df)
df = trans_by_list(df)
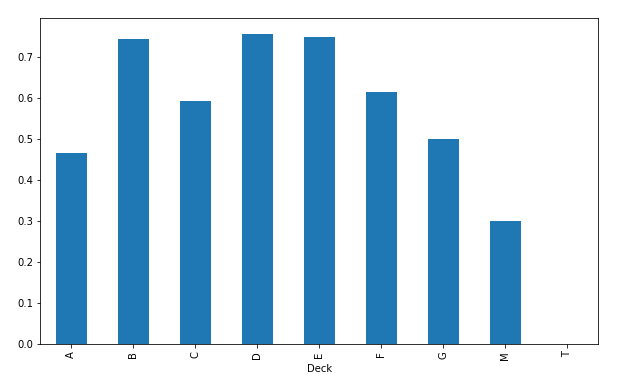
df['Deck'] = df['Cabin'].apply(lambda s:s[0] if pd.notnull(s) else 'M')
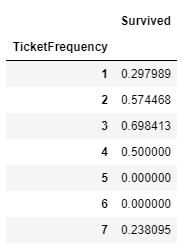
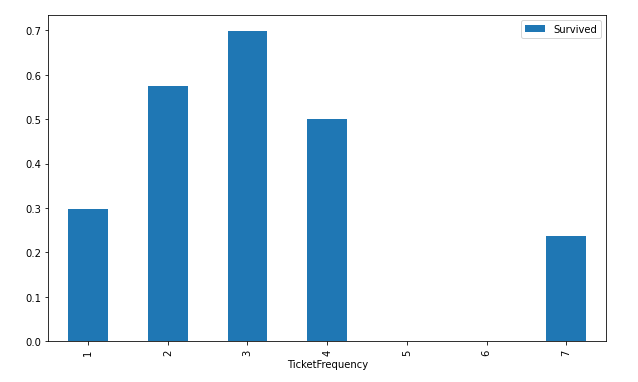
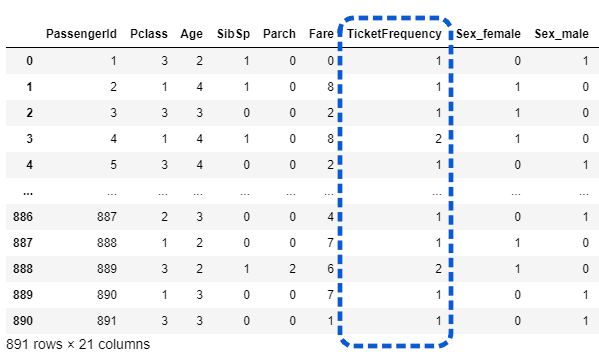
df['TicketFrequency'] = df.groupby('Ticket')['Ticket'].transform('count')
# 不要な列の削除
df.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 欠損値処理
df['Fare'] = df['Fare'].fillna(df['Fare'].median())
df['Embarked'] = df['Embarked'].fillna('S')
df['Fare'] = pd.qcut(df['Fare'], 10, labels=False)
df['Age'] = pd.cut(df['Age'], 10, labels=False)
# カテゴリ変数の変換
df = pd.get_dummies(df, columns=['Sex', 'Embarked', 'Deck', 'Title', 'Surname'])
return df
df_train = pd.read_csv('/kaggle/input/titanic/train.csv')
df_test = pd.read_csv('/kaggle/input/titanic/test.csv')
# 訓練データとテストデータを連結
df_test['Survived'] = np.nan
df_all = pd.concat([df_train, df_test], ignore_index=True, sort=False)
make_list(df_all) # デッドリストとサバイブリストを作成
df_all = preprocessing(df_all)
print(df_all.shape)
# ひとまとめにしたデータを訓練データとテストデータに分割
df_train = df_all.loc[df_all['Survived'].notnull()]
df_test = df_all.loc[df_all['Survived'].isnull()]
x_titanic = df_train.drop(['Survived'], axis=1)
y_titanic = df_train['Survived']
|