1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
| from sklearn import model_selection
from PIL import Image
import os, glob
import numpy as np
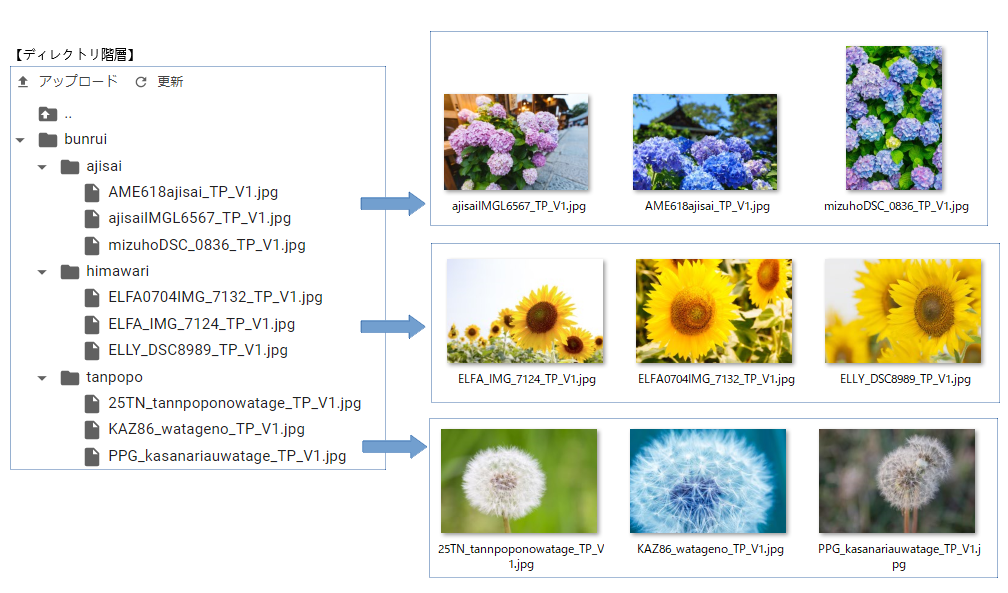
root_dir = "./bunrui/"
categories = ["ajisai", "himawari", "tanpopo"]
nb_classes = len(categories)
image_size = 50
X = []
Y = []
for idx, cat in enumerate(categories):
image_dir = os.path.join(root_dir, cat)
files = glob.glob(image_dir + "/*.jpg")
print("---", cat, "を処理中")
for i, f in enumerate(files):
img = Image.open(f)
img = img.convert("RGB")
img = img.resize((image_size, image_size))
data = np.asarray(img)
X.append(data)
Y.append(idx)
X = np.array(X)
Y = np.array(Y)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, Y)
xy = (X_train, X_test, y_train, y_test)
np.save("./bunrui/hana.npy", xy)
print("ok,", len(Y))</pre>
<strong>手順④</strong>
手順③で保存したデータをロードし、モデル化・学習・評価を行う。
モデル化したデータは<code>bunrui/hana.hdf5</code>に保存する。
<pre>from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.utils import np_utils
import numpy as np
root_dir = "./bunrui/"
categories = ["ajisai", "himawari", "tanpopo"]
nb_classes = len(categories)
image_size = 50
def main():
X_train, X_test, y_train, y_test = np.load("./bunrui/hana.npy")
X_train = X_train.astype("float") / 256
X_test = X_test.astype("float") / 256
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
model = model_train(X_train, y_train)
model_eval(model, X_test, y_test)
def build_model(in_shape):
model = Sequential()
model.add(Convolution2D(32, 3, 3,
border_mode='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Convolution2D(64, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
return model
def model_train(X, y):
model = build_model(X.shape[1:])
model.fit(X, y, batch_size=32, nb_epoch=30)
hdf5_file = "./bunrui/hana.hdf5"
model.save_weights(hdf5_file)
return model
def model_eval(model, X, y):
score = model.evaluate(X, y)
print('loss=', score[0])
print('accuracy=', score[1])
if __name__ == "__main__":
main()
|