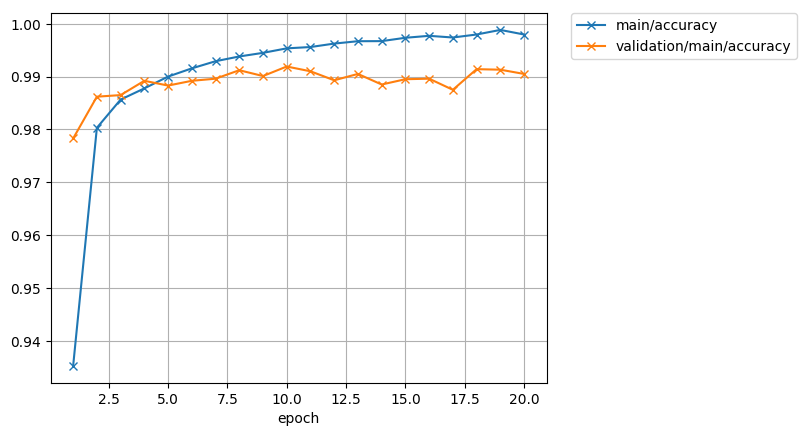
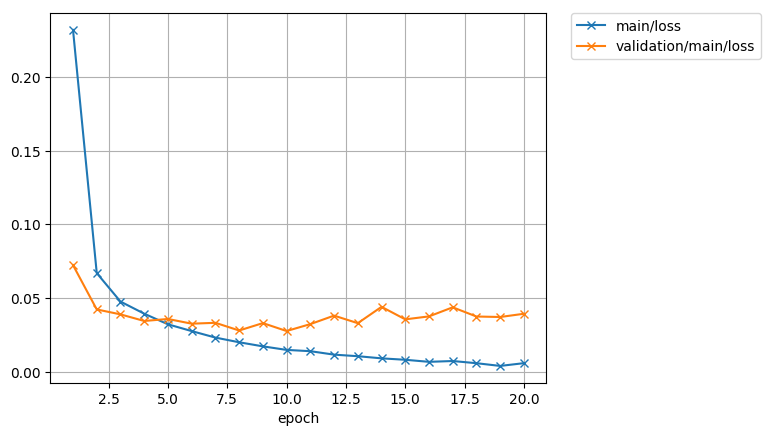
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| from __future__ import print_function
import argparse
import chainer
import chainer.functions as F
import chainer.links as L
import chainer.initializers as I
from chainer import training
from chainer.training import extensions
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
w = I.Normal(scale=0.05)
super(MLP, self).__init__(
conv1=L.Convolution2D(1, 16, 5, 1, 0),
conv2=L.Convolution2D(16, 32, 5, 1, 0),
l3=L.Linear(None, n_out, initialW=w),
)
def __call__(self, x):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)), ksize=2, stride=2)
h2 = F.max_pooling_2d(F.relu(self.conv2(h1)), ksize=2, stride=2)
y = self.l3(h2)
return y
def main():
parser = argparse.ArgumentParser(description='Chainer example: MNIST')
parser.add_argument('--batchsize', '-b', type=int, default=100, help='Number of images in each mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=20, help='Number of sweeps over the dataset to train')
parser.add_argument('--gpu', '-g', type=int, default=-1, help='GPU ID (negative value indicates CPU)')
parser.add_argument('--out', '-o', default='result', help='Directory to output the result')
parser.add_argument('--resume', '-r', default='', help='Resume the training from snapshot')
parser.add_argument('--unit', '-u', type=int, default=1000, help='Number of units')
args = parser.parse_args(args=[])
print('GPU: {}'.format(args.gpu))
print('# unit: {}'.format(args.unit))
print('# Minibatch-size: {}'.format(args.batchsize))
print('# epoch: {}'.format(args.epoch))
print('')
train, test = chainer.datasets.get_mnist(ndim=3)
model = L.Classifier(MLP(args.unit, 10), lossfun=F.softmax_cross_entropy)
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use()
model.to_gpu()
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
train_iter = chainer.iterators.SerialIterator(train, args.batchsize)
test_iter = chainer.iterators.SerialIterator(test, args.batchsize, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=args.gpu)
trainer = training.Trainer(updater, (args.epoch, 'epoch'), out=args.out)
trainer.extend(extensions.Evaluator(test_iter, model, device=args.gpu))
trainer.extend(extensions.dump_graph('main/loss'))
trainer.extend(extensions.snapshot(), trigger=(args.epoch, 'epoch'))
trainer.extend(extensions.LogReport())
trainer.extend( extensions.PlotReport(['main/loss', 'validation/main/loss'], 'epoch', file_name='loss.png'))
trainer.extend( extensions.PlotReport(['main/accuracy', 'validation/main/accuracy'], 'epoch', file_name='accuracy.png'))
trainer.extend(extensions.PrintReport( ['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.ProgressBar())
if args.resume:
chainer.serializers.load_npz(args.resume, trainer)
trainer.run()
model.to_cpu()
modelname = args.out + "/MLP.model"
print('save the trained model: {}'.format(modelname))
chainer.serializers.save_npz(modelname, model)
if __name__ == '__main__':
main()
|