メッシュグラフ
メッシュグラフは3次元のデータをドロネー三角分割で算出された図形の面で表現します。
Plotlyでメッシュグラフを表示するにはMesh3dクラスを使用します。
Mesh3dクラスの引数 x、y、zにX値、Y値、Z値を設定します。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]
グラフをドラッグすると、3Dグラフをいろいろな角度で表示することができます。
メッシュグラフは3次元のデータをドロネー三角分割で算出された図形の面で表現します。
Plotlyでメッシュグラフを表示するにはMesh3dクラスを使用します。
Mesh3dクラスの引数 x、y、zにX値、Y値、Z値を設定します。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]
グラフをドラッグすると、3Dグラフをいろいろな角度で表示することができます。
サーフェスグラフは3次元のデータを面で表現します。
Plotlyでサーフェスグラフを表示するにはSurfaceクラスを使用します。
Surfaceクラスの引数 x、y、zにX値、Y値、Z値を設定します。
Z値はカラースケールで表示されます。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]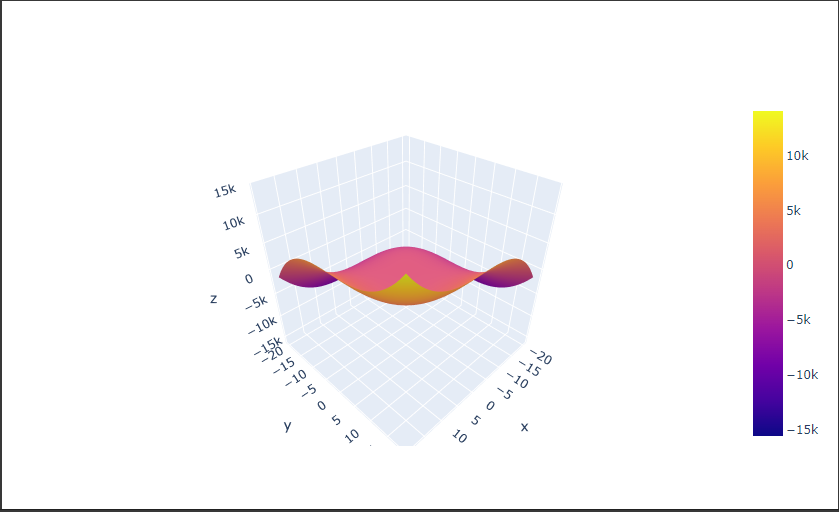
グラフをドラッグすると、3Dグラフをいろいろな角度で表示することができます。
Plotlyで3D折れ線グラフを表示するにはScatter3dクラスを使用します。
Scatter3dクラスの引数 x、y、zにX値、Y値、Z値を設定します。(11~13行目)
折れ線グラフとして描画する場合は、引数 modeに“lines”を設定します。(14行目)
以下のコードでは三角関数で生成したデータを3D折れ線グラフで表示しています。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]
グラフをドラッグすると、3Dグラフをいろいろな角度で表示することができます。
Plotlyで3D散布図を表示するにはScatter3dクラスを使用します。
Scatter3dクラスの引数 x、y、zにX値、Y値、Z値を設定します。
散布図として描画する場合は、引数 modeに“markers”を設定します。
またScatterクラスと同様に、要素の色やサイズの大きさで表現することができます。
以下のコードでは5×100の乱数を生成し、それぞれの値(x,y,z)およびサイズ(size)と色(color)で表現した3D散布図を表示しています。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]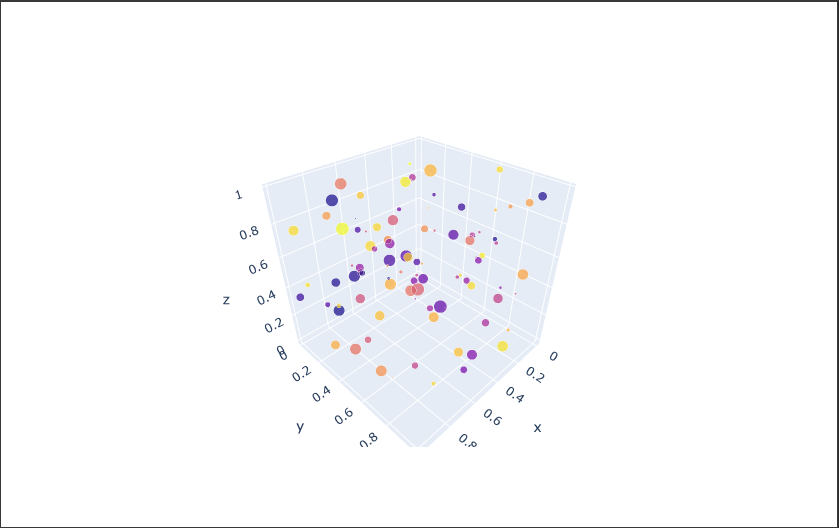
グラフをドラッグすると、3Dグラフをいろいろな角度で表示することができます。
mapboxを利用すると、より高精細な地図を表示することができます。
mapboxサイトで事前にアカウントを登録し、アクセストークンを取得しておきましょう。
mapbox - https://www.mapbox.jp/
mapboxを利用するには、layoutのmapbox属性にplotly.objects.layout.Mapboxインスタンスを設定します。
Mapboxクラスの引数は下記の通りです。
下記のコードでは、Scattermapboxクラスを使って、mapboxを利用した散布図を地図上に描画しています。
(Scattergeoと同様の引数を使用することができます。)
[Google Colaboratory]
1 | import numpy as np |
[実行結果]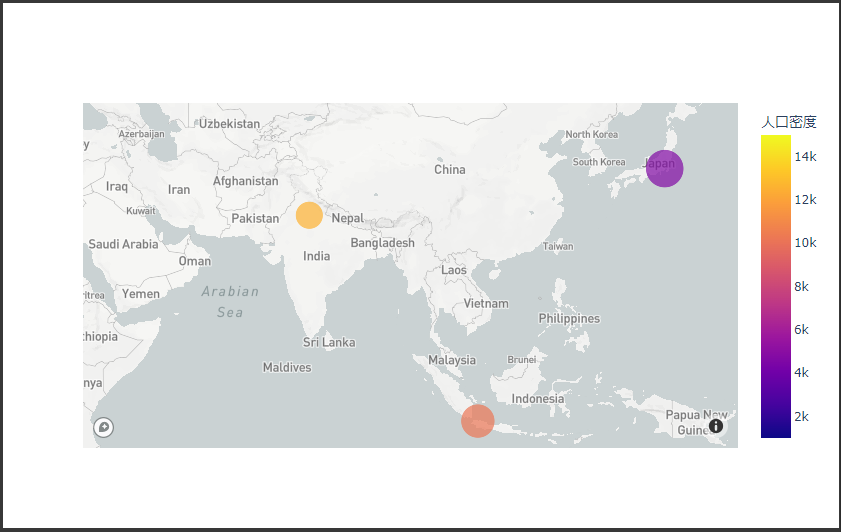
Plotlyで地図上に折れ線グラフを表示するにはScattergeoクラスを使用します。
Scattergeoクラスの引数は下記の通りです。
以下のコードでは、地図上の各地点を繋いだ折れ線グラフを描画しています。
layoutのgeo.projection属性に辞書型データを設定すると投影法などに変更することができます。(14行目)
[Google Colaboratory]
1 | import plotly.graph_objects as go |
[実行結果]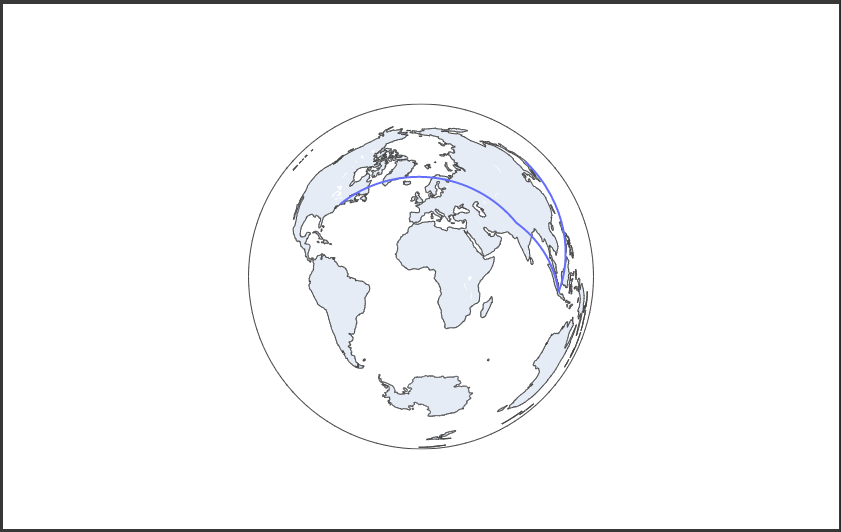
Plotlyで地図上に散布図を表示するにはScattergeoクラスを使用します。
Scattergeoクラスの引数は下記の通りです。
以下のコードでは、地図上に散布図を描画し、要素のサイズと色で値を表現しています。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]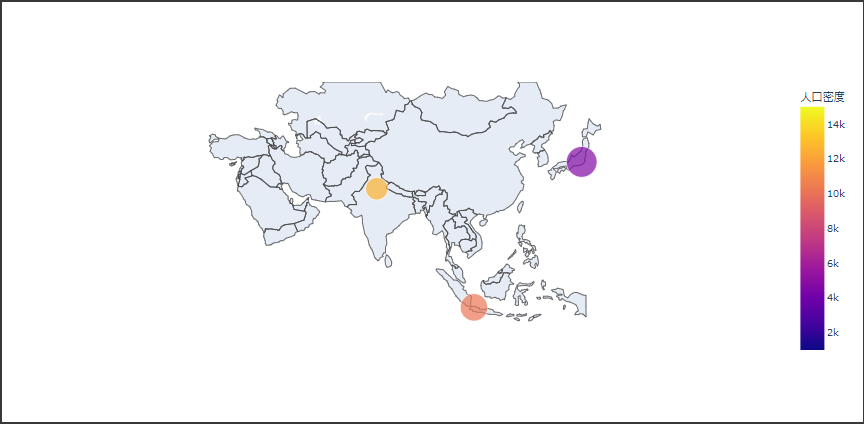
階級区分図(コロプレスマップ)は、国民所得や人口密度などの統計数値に合わせて色調を塗り分けた地図です。
地域ごとに数値を比較し可視化する際に利用します。
Plotlyで階級区分図を表示するにはChoroplethクラスを使用します。
Choroplethクラスの引数は下記の通りです。
以下のコードではgapminderデータセットのcountry列を位置データとして指定し、lifeExp列の値を階級区分図で表示しています。
[Google Colaboratory]
1 | import plotly |
[実行結果]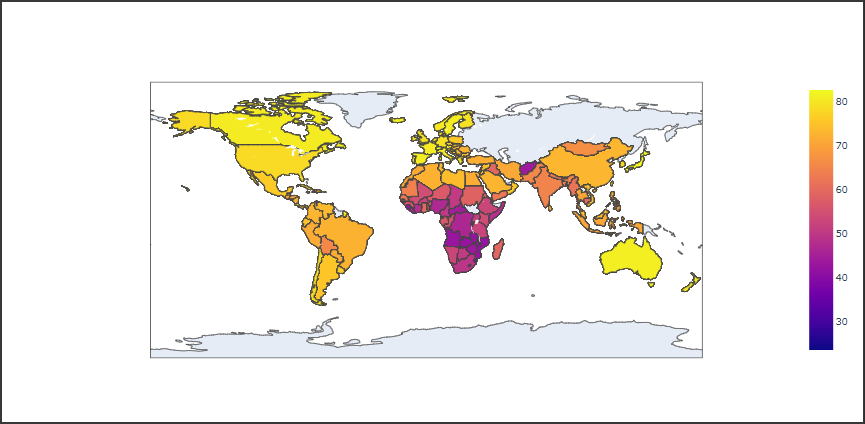
ファンネル図は値が絞り込まれる様子を漏斗(ろうと)の形で表現します。
値は長方形の長さで表現され、次の要素は初期値からの変化または前の値からの変化が描画されます。
Plotlyでファンネル図を表示するにはFunnelクラスを使用します。
引数 xに各段階の値、引数 yに各段階のラベルを設定します。(7~8行目、16~17行目)
引数 textinfoには要素の表示形式と基準値をスペース区切りで設定します。(9行目、18行目)
基準値とは百分率を表示する場合の基準となる値で、次の3つのいずれかを指定します。
[Google Colaboratory]
1 | import plotly.graph_objects as go |
[実行結果]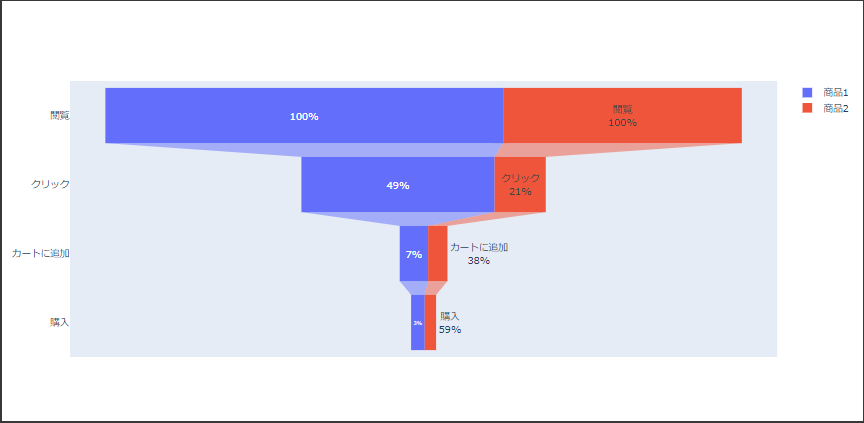
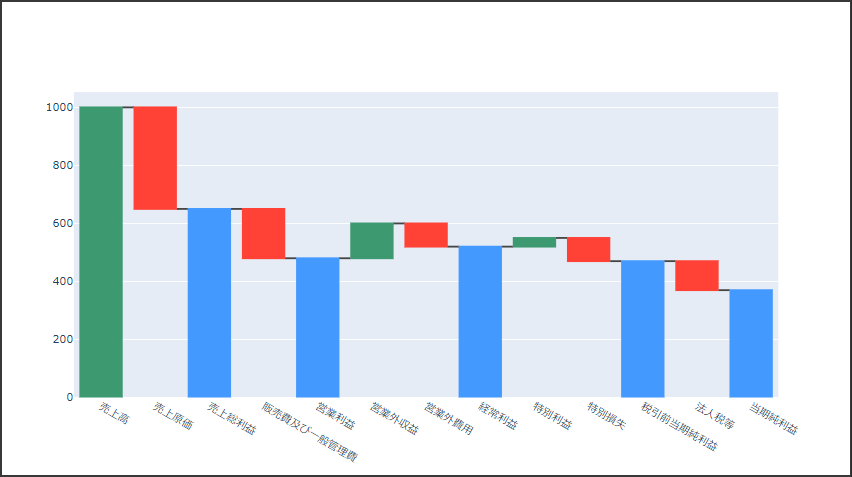
ウォーターフォール図は初期値、累計値、値の増減を長方形の長さで表現します。
値が増加した場合は前の値が底辺となり、値が減少した場合は前の値が上辺となります。
初期値と累計値は0が底辺となります(値が正の場合)。
Plotlyでウォーターフォール図を表示するにはWaterfallクラスを使用します。
引数 xにラベルとなるデータ、引数 yに値となるデータを設定します。
引数 measureには“relative”(相対値)、または“total”(合計値)を設定します。
[Google Colaboratory]
1 | import plotly.graph_objects as go |
[実行結果]