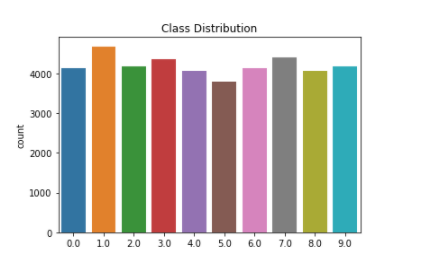
import numpy as np import pandas as pd import matplotlib.pyplot as plt import os from tqdm import tqdm import seaborn as sns from sklearn.model_selection import train_test_split import warnings warnings.filterwarnings("ignore")
import torch import torch.nn as nn import torchvision from torch.utils.data import TensorDataset, DataLoader, Dataset
plt.figure(figsize=(12, 10)) for i in range(20): plt.subplot(5, 4, i+1) plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(data[i].reshape(28,28))