手書きの数字認識問題Digit Recognizer の2回目の記事になります。
PyTorchデータセットの読み込み
前回記事で読み込んだデータを訓練データと評価データに分けます。(4:1の割合)
分けたデータはPyTorch用のデータセットに変換します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 x_train, x_val, y_train, y_val = train_test_split(data, labels, test_size=0.2) print('Train shape:', x_train.shape, 'Val shape:', x_val.shape) x_train_tensor = torch.from_numpy(x_train) y_train_tensor = torch.from_numpy(y_train).type(torch.LongTensor) x_val_tensor = torch.from_numpy(x_val) y_val_tensor = torch.from_numpy(y_val).type(torch.LongTensor) train_dataset = TensorDataset(x_train_tensor, y_train_tensor) val_dataset = TensorDataset(x_val_tensor, y_val_tensor) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
[結果]
ロジスティック回帰モデルの準備
ロジスティック回帰モデルを作成します。パラメータはコメントをご参照下さい。
交差エントロピーは損失関数 の一つで、予測と実際の値のズレの大きさを表す関数です。モデルの予測精度を評価するもので、損失関数の値が小さければより正確なモデルと言えます。
確率的勾配降下法は最適化アルゴリズム(勾配降下法) の一つで、重みを少しずつ更新して勾配が最小になる点を探索するアルゴリズムです。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 device = torch.device('cpu' if torch.cuda.is_available() else 'cpu') input_size = 28 * 28 # 入力層のサイズ output_size = 10 # 出力層のサイズ hidden_size = 100 # 隠れ層(中間層)のサイズ learning_rate = 0.001 # 学習率 num_epochs = 10 # エポック数「一つの訓練データを何回繰り返して学習させるか」 class LogisticRegression(nn.Module): def __init__(self, input_size, output_size): super(LogisticRegression, self).__init__() # Linear model self.linear = nn.Linear(input_size, output_size) def forward(self, x): out = self.linear(x) return out model = LogisticRegression(input_size, output_size).to(device) # Cross Entropy Loss(交差エントロピー) criterion = nn.CrossEntropyLoss() # SGD Optimizer(確率的勾配降下法) optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
学習と評価(CPU版)
上記で用意したデータセットと回帰モデルで学習と評価を行います。
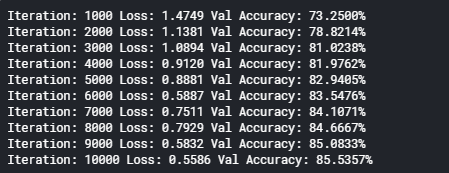
1000回ごとに途中結果を表示しています。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 loss_list = [] iteration_list = [] accuracy_list = [] iter_num = 0 for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): # input and label(入力データと正解ラベルを設定) train = images.view(-1, 28*28) labels = labels # Forward pass(順伝搬:初期の入力を層ごとに処理して出力に向けて送ること) outputs = model(train) # Loss calculate(損失計算) loss = criterion(outputs, labels) # Backward and optimize(最適化、確率的勾配降下法) optimizer.zero_grad() loss.backward() optimizer.step() iter_num += 1 if (i+1) % 50 == 0: correct = 0 total = 0 for images, labels in val_loader: # Forward pass(順伝搬:初期の入力を層ごとに処理して出力に向けて送ること) images = images.view(-1, 28*28) outputs = model(images) # Predictions(予測) predicted = torch.max(outputs, 1)[1] # Total number of samples(サンプル数) total += labels.size(0) # Total correct predictions(正解数) correct += (predicted == labels).sum() accuracy = 100 * (correct/total) loss_list.append(loss.data) iteration_list.append(iter_num) accuracy_list.append(accuracy) if (iter_num+1) % 1000 == 0: # Print Loss(損失と正解率を表示) print('Iteration: {} Loss: {:0.4f} Val Accuracy: {:0.4f}%'.format(iter_num+1, loss.data, accuracy))
[結果]
損失(Loss)が少しずつ少なくなり、正解率が(Accuracy)少しずつ上昇し、最終的に85.53% になったことが確認できます。
学習結果をグラフ化
学習結果をグラフ表示します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13 # Visualize loss(損失のグラフ化) plt.plot(iteration_list,loss_list) plt.xlabel("Num. of Iters.") plt.ylabel("Loss") plt.title("Logistic Regression: Loss vs Num. of Iters.") plt.show() # Visualize accuracy(正解率のグラフ化) plt.plot(iteration_list,accuracy_list) plt.xlabel("Num. of Iters.") plt.ylabel("Accuracy") plt.title("Logistic Regression: Accuracy vs Num. of Iters.") plt.show()
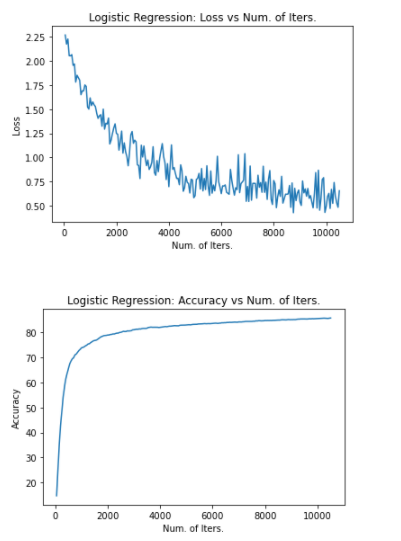
[結果]
損失(上図)が次第に下がり、正解率(下図)が徐々に上がっていることを視覚的に確認することができます。
次回は畳み込みニューラルネットワーク(Convolutional Neural Networks)の処理を実装していきます。