import numpy as np import pandas as pd import matplotlib.pyplot as plt import os from tqdm import tqdm from sklearn.model_selection import train_test_split import seaborn as sns import warnings warnings.filterwarnings("ignore")
import torch import torch.nn as nn from torch.autograd import Variable import torchvision
CSVファイル読み込み・正解ラベルの準備
CSVファイルを読み込み、正解ラベルのデータを分けます。
正解ラベルはNumpyのint32型に変換します。
[ソース]
1 2 3 4
data = pd.read_csv('../input/digit-recognizer/train.csv', dtype = np.float32) labels = data.pop('label').astype('int32')
data.head() # let's see first five rows
[結果]
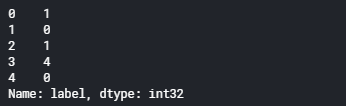
変換した正解ラベルを表示します。
[ソース]
1
labels.head() # after converting labels to `int32`
[結果]
次に0~255のピクセルデータを0~1に変換します。(正規化)
正解ラベルと0~1に変換したデータはNumpyの配列型にしておきます。
また、訓練データと評価データに分けます。(4:1の割合)
[ソース]
1 2 3 4 5
data = data.to_numpy() / 255.0 # converting to numpy and normalizing between 0 and 1 labels = labels.to_numpy()
plt.figure(figsize=(12, 10)) for i in range(16): plt.subplot(4, 4,i+1) plt.xticks([]) plt.yticks([]) plt.imshow(x_train[i].reshape(28,28), cmap=plt.cm.binary) plt.xlabel(y_train[i]) plt.show()
# Train the model() total_step = len(train_loader) for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): # (訓練データごとにループ) images = images.view(32, 1, 28, 28).to(device) labels = labels.to(device)
# Forward pass(順伝搬:初期の入力を層ごとに処理して出力に向けて送ること) outputs = model(images) loss = criterion(outputs, labels)
# Backward and optimize(最適化、確率的勾配降下法) optimizer.zero_grad() loss.backward() optimizer.step()
iter_num += 1
if iter_num % 50 == 0: # Calculate Accuracy(正解率の算出) correct = 0 total = 0 # Iterate through val dataset(評価データごとにループ) for images, labels in val_loader: test = images.view(1, 1, 28, 28).to(device) labels = labels.to(device) # Forward propagation(順伝搬:初期の入力を層ごとに処理して出力に向けて送ること) outputs = model(test) # Get predictions from the maximum value(予測値の取得) predicted = torch.max(outputs.data, 1)[1] # Total number of labels(正解ラベルの総数) total += len(labels) correct += (predicted == labels).sum() accuracy = 100 * correct / float(total)
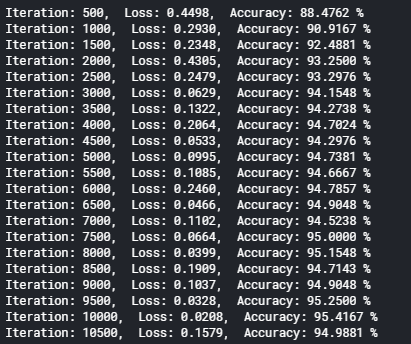
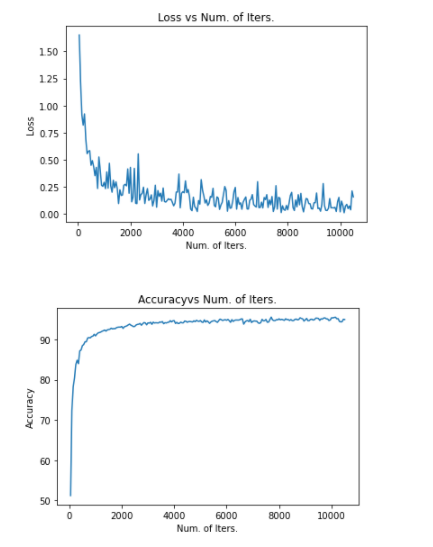
# store loss and iteration(損失・正解率を保持) loss_list.append(loss.data) iteration_list.append(iter_num) accuracy_list.append(accuracy) if iter_num % 500 == 0: # Print Loss(損失と正解率を表示) print('Iteration: {}, Loss: {:.4f}, Accuracy: {:.4f} %'.format(iter_num, loss.data, accuracy))