1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
| # ライブラリをインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
import seaborn as sns
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings("ignore")
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
# CSVファイルを読み込み、正解ラベルのデータを分ける
data = pd.read_csv('./train.csv', dtype = np.float32)
labels = data.pop('label').astype('int64')
# 0~255のピクセルデータを0~1に変換
data = data.to_numpy() / 255.0 # converting to numpy and normalizing between 0 and 1
labels = labels.to_numpy()
data = data.reshape(-1, 28, 28, 1)
labels = labels.reshape(-1,1)
print(labels.shape)
# 訓練データと評価データに分ける
x_train, x_val, y_train, y_val = train_test_split(data, labels, test_size=0.2)
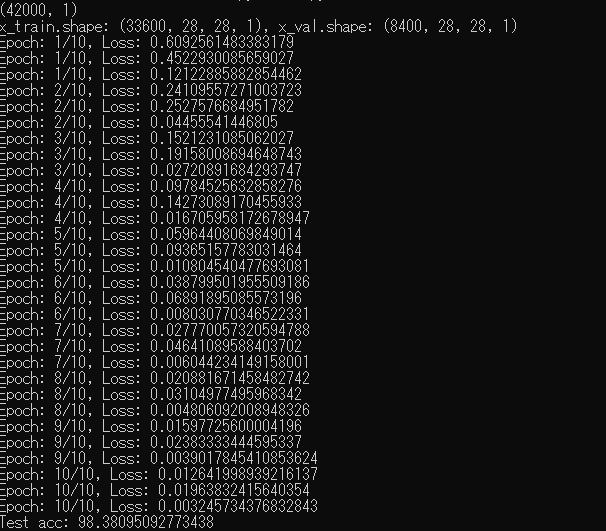
print(f'x_train.shape: {x_train.shape}, x_val.shape: {x_val.shape}')
# カスタムデータセットの定義
class MNISTDataset(Dataset):
def __init__(self, images, labels, transform = None):
"""Method to initilaize variables."""
self.images = images
self.labels = labels
self.transform = transform
def __getitem__(self, index):
label = self.labels[index]
image = self.images[index]
if self.transform is not None:
image = self.transform(image)
image = image.repeat(3, 1, 1)
return image, label
def __len__(self):
return len(self.images)
# データを0~1のテンソルに変換
train_set = MNISTDataset(x_train, y_train, transform=transforms.Compose([transforms.ToTensor()]))
val_set = MNISTDataset(x_val, y_val, transform=transforms.Compose([transforms.ToTensor()]))
all_data = MNISTDataset(data, labels, transform=transforms.Compose([transforms.ToTensor()]))
train_loader = DataLoader(train_set, batch_size=32)
val_loader = DataLoader(val_set, batch_size=32)
all_data_loader = DataLoader(all_data, batch_size=32)
# GPUが使えればGPUを使用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
learning_rate = 0.001
num_classes = 10
num_epochs = 10
# TorchvisionからResNet-18(畳み込みニューラル ネットワーク)モデルをダウンロード
model = torchvision.models.resnet18(pretrained=True) # Kaggleノートブックではここでダウンロードエラー
num_ftrs = model.fc.in_features
# 全結合を行う3層構造のニューラルネットワークを生成
model.fc = nn.Linear(num_ftrs, num_classes)
model.to(device)
criterion = nn.CrossEntropyLoss()
# 全てのパラメータが最適化されることを観察
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
# 7エポックごとにLRを0.1ずつ減らす
# LR range test:初期学習率を決める手段で、ある幅で学習率を徐々に増加させながらAccuracyないしLossを観察し決定する手法
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 損失関数と最適化アルゴリズムを生成
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 学習率を更新する
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 学習する
total_step = len(train_loader)
curr_lr = learning_rate
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass(順伝搬:初期の入力を層ごとに処理して出力に向けて送ること)
outputs = model(images)
loss = criterion(outputs, labels.flatten())
# Backward and optimize(逆伝播と最適化を行う)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 300 == 0:
print(f'Epoch: {epoch + 1}/{num_epochs}, Loss: {loss.item()}')
# 評価する
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels.flatten()).sum()
print(f'Test acc: {100 * correct / total}')
|