タイタニック生存予測の正解率をあげるために、Random Forestを生成するときのパラメータを調整します。
(データの前処理は前回記事と全く同じなので省略します。)
グリッドサーチ
グリッドサーチを使って、次の3パラメータに対してチューニングを行います。
- criterion
データの分割の方法。
- n_estimators
バギングに用いる決定木の個数。デフォルトの値は10。
- max_depth
決定木の深さの最大値。過学習を避けるためにはこれを調節するのが最も重要。
グリッドサーチはパラメータ候補をリストで指定して、その中でもっとも成績のいいパラメータの組み合わせを導く手法です。
[ソース]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| from sklearn import ensemble, model_selection
from sklearn.model_selection import GridSearchCV
# 試行するパラメータを羅列
params = {
'criterion' : ['gini', 'entropy'],
'n_estimators': [10, 100, 300, 500, 1000, 1500, 2000],
'max_depth' : [3, 5, 7, 9, 11]
}
clf = ensemble.RandomForestClassifier()
grid_search = GridSearchCV(clf, param_grid=params, cv=4)
grid_search.fit(x_titanic, y_titanic)
print(grid_search.best_score_)
print(grid_search.best_params_)
|
[結果]

最も成績のよいパラメータは上記のようになりました。
Random Forest分割交差検証
グリッドサーチで調べたベストパラメータを指定してRandom Forestのインスタンスを作成します。
その後、cross_val_score関数で分割交差検証を行い、どのくらいの正解率になるかチェックします。
[ソース]
1
2
3
4
5
6
7
| from sklearn import ensemble, model_selection
clf = ensemble.RandomForestClassifier(criterion='geni', n_estimators=100, max_depth=9)
for _ in range(5):
score = model_selection.cross_val_score(clf, x_titanic, y_titanic, cv=4) # cv=4は4分割の意
print('各正解率', score)
print('正解率', score.mean())
|
[結果]
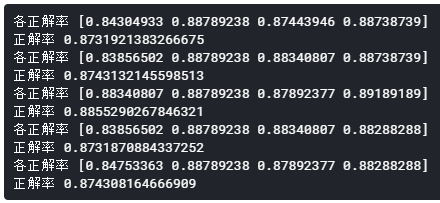
正解率は87.31%~88.55%となりました。
Kaggleに提出
分割交差検証で生成したRandom Forestをそのまま使って、学習・予測を行います。
最後に提出用に出力したCSVファイルをKaggleに提出します。
[ソース]
1
2
3
4
5
6
7
8
9
| # 学習
clf.fit(x_titanic, y_titanic)
# 予測
pre = clf.predict(df_test.drop(['Survived'], axis=1))
result = pd.DataFrame(df_test['PassengerId'])
result['Survived'] = pre.astype(int)
result.to_csv('result0320l.csv', index=False)
|
[提出結果]
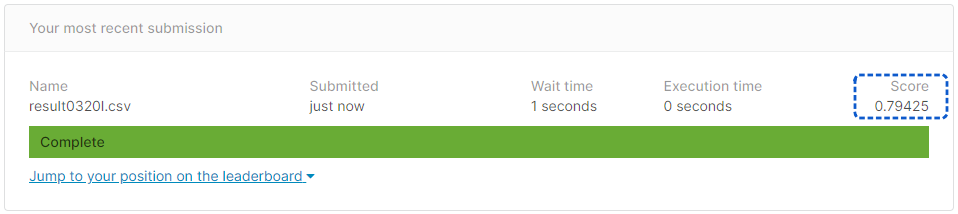
正解率79.42%となりました。
パラメータを調整していない前回の正解率と全く同じ結果となりました・・・難しいです。