タイタニック生存予測の面白そうなノートを見つけたので試しに実行してみます。
Titanic best working Classifier https://www.kaggle.com/sinakhorami/titanic-best-working-classifier
タイタニックの生存予測に一番最適な予測アルゴリズムを比較しています。
参考ソースをそのまま実行
まずは、訓練データと検証データを読み込み、1つにまとめています。
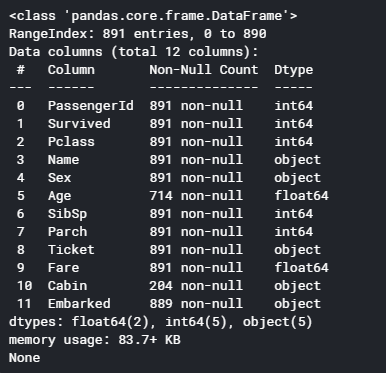
訓練データのデータの要約を表示します。カラム名、Nullでないデータ数、データタイプが表示されます。
[ソース]
1 2 3 4 5 6 7 8 9 10 %matplotlib inline import numpy as np import pandas as pd import re as re train = pd.read_csv('/kaggle/input/titanic/train.csv', header = 0, dtype={'Age': np.float64}) test = pd.read_csv('/kaggle/input/titanic/test.csv' , header = 0, dtype={'Age': np.float64}) full_data = [train, test] print (train.info())
[結果]
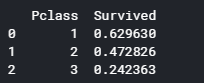
客室クラスごとの平均生存率を表示します。
[ソース]
1 print (train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean())
[結果]
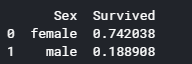
性別ごとの平均生存率を表示します。
[ソース]
1 print (train[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean())
[結果]
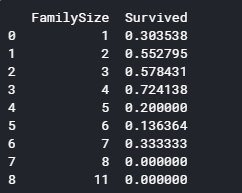
家族の人数ごとの平均生存率を表示します。
[ソース]
1 2 3 for dataset in full_data: dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1 print (train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean())
[結果]
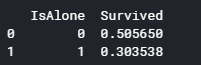
一人身(=1)かそれ以外の平均生存率を表示します。
[ソース]
1 2 3 4 for dataset in full_data: dataset['IsAlone'] = 0 dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1 print (train[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean())
[結果]
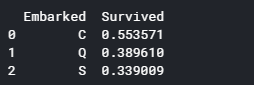
乗船地ごとの平均生存率を表示します。
[ソース]
1 2 3 for dataset in full_data: dataset['Embarked'] = dataset['Embarked'].fillna('S') print (train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean())
[結果]
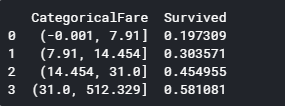
料金を4分割し、料金範囲ごとの平均生存率を表示します。
[ソース]
1 2 3 4 for dataset in full_data: dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median()) train['CategoricalFare'] = pd.qcut(train['Fare'], 4) print (train[['CategoricalFare', 'Survived']].groupby(['CategoricalFare'], as_index=False).mean())
[結果]
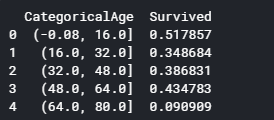
年齢が欠測値になっている箇所を、統計的に適当にばらして補完します。
年齢を5分割し、年齢範囲ごとの平均生存率を表示します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 for dataset in full_data: age_avg = dataset['Age'].mean() age_std = dataset['Age'].std() age_null_count = dataset['Age'].isnull().sum() age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count) dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list dataset['Age'] = dataset['Age'].astype(int) train['CategoricalAge'] = pd.cut(train['Age'], 5) print (train[['CategoricalAge', 'Survived']].groupby(['CategoricalAge'], as_index=False).mean())
[結果]
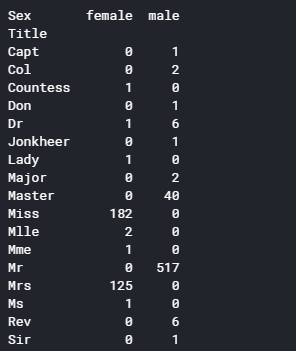
名前から敬称を取得し、敬称・性別ごとに平均生存率を表示します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 def get_title(name): title_search = re.search(' ([A-Za-z]+)\.', name) # If the title exists, extract and return it. if title_search: return title_search.group(1) return "" for dataset in full_data: dataset['Title'] = dataset['Name'].apply(get_title) print(pd.crosstab(train['Title'], train['Sex']))
[結果]
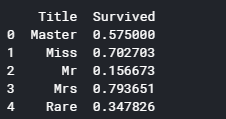
意味合いが同じ敬称とレアな敬称にまとめて、平均生存率を表示します。
[ソース]
1 2 3 4 5 6 7 8 9 for dataset in full_data: dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\ 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare') dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss') dataset['Title'] = dataset['Title'].replace('Ms', 'Miss') dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs') print (train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean())
[結果]
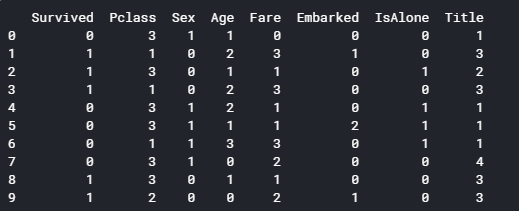
カテゴリデータや範囲ごとのデータを数値変換し、予測に必要な特徴量(カラム)を選択します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 for dataset in full_data: # Mapping Sex dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int) # Mapping titles title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5} dataset['Title'] = dataset['Title'].map(title_mapping) dataset['Title'] = dataset['Title'].fillna(0) # Mapping Embarked dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int) # Mapping Fare dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0 dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1 dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2 dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3 dataset['Fare'] = dataset['Fare'].astype(int) # Mapping Age dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0 dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1 dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2 dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3 dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 # Feature Selection drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp',\ 'Parch', 'FamilySize'] train = train.drop(drop_elements, axis = 1) train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1) test = test.drop(drop_elements, axis = 1) print (train.head(10)) train = train.values test = test.values
[結果]
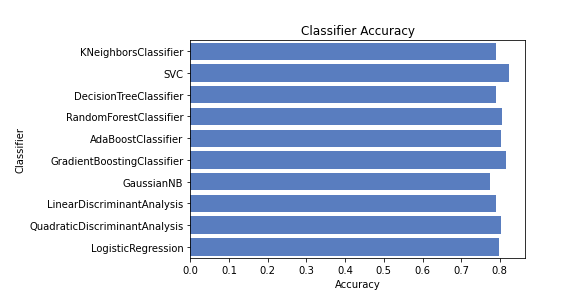
各アルゴリズムごとに予測を行い、それぞれの正解率をグラフ表示します。
[ソース]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import StratifiedShuffleSplit from sklearn.metrics import accuracy_score, log_loss from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier from sklearn.naive_bayes import GaussianNB from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis from sklearn.linear_model import LogisticRegression classifiers = [ KNeighborsClassifier(3), SVC(probability=True), DecisionTreeClassifier(), RandomForestClassifier(), AdaBoostClassifier(), GradientBoostingClassifier(), GaussianNB(), LinearDiscriminantAnalysis(), QuadraticDiscriminantAnalysis(), LogisticRegression()] log_cols = ["Classifier", "Accuracy"] log = pd.DataFrame(columns=log_cols) sss = StratifiedShuffleSplit(n_splits=10, test_size=0.1, random_state=0) X = train[0::, 1::] y = train[0::, 0] acc_dict = {} for train_index, test_index in sss.split(X, y): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] for clf in classifiers: name = clf.__class__.__name__ clf.fit(X_train, y_train) train_predictions = clf.predict(X_test) acc = accuracy_score(y_test, train_predictions) if name in acc_dict: acc_dict[name] += acc else: acc_dict[name] = acc for clf in acc_dict: acc_dict[clf] = acc_dict[clf] / 10.0 log_entry = pd.DataFrame([[clf, acc_dict[clf]]], columns=log_cols) log = log.append(log_entry) plt.xlabel('Accuracy') plt.title('Classifier Accuracy') sns.set_color_codes("muted") sns.barplot(x='Accuracy', y='Classifier', data=log, color="b")
[結果]
そんなに大きな違いはないですが、とりあえずSVMがベストのアルゴリズムのようです。