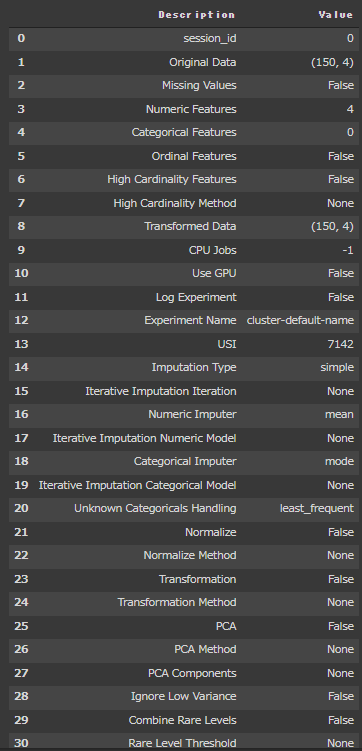
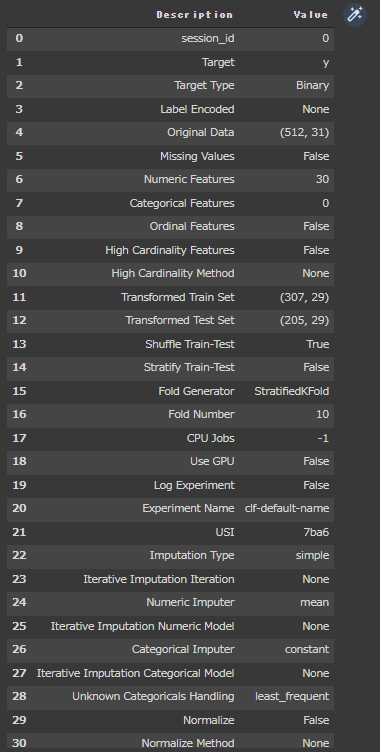
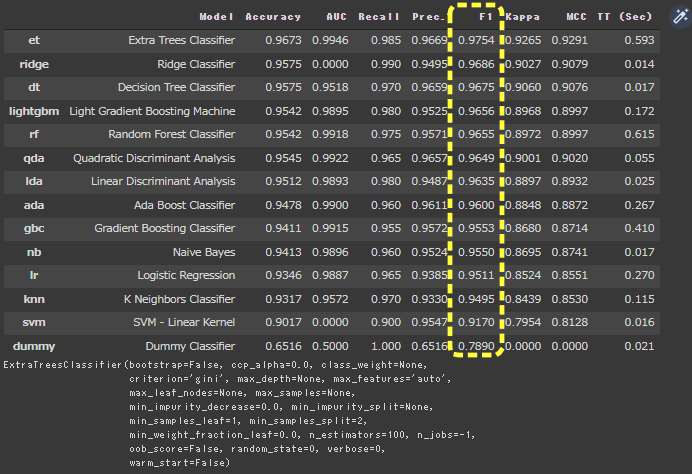
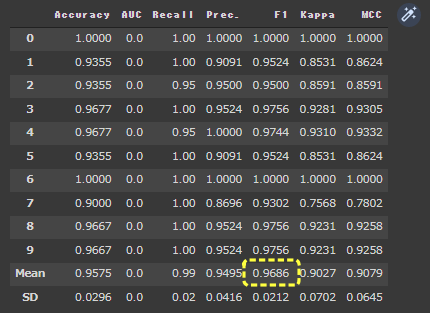
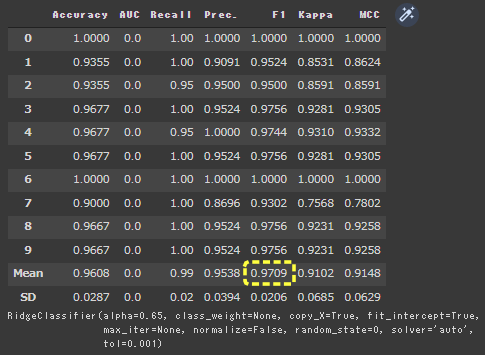
PyCaretでいろいろな評価指標グラフを表示していきます。
evaluate_modelダイアログ
evaluate_modelを実行すると、様々な評価指標を確認することができます。
[Google Colaboratory]
1
| evaluate_model(tuned_ridge)
|
[実行結果]
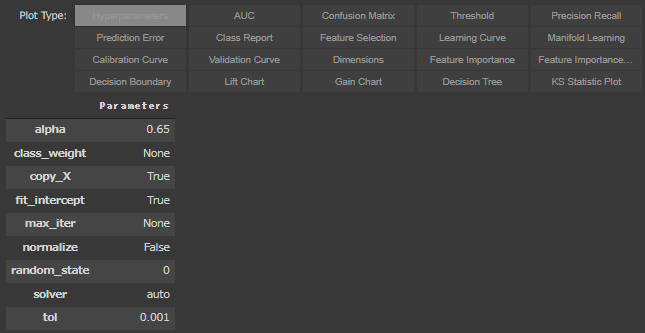
Feature Importance
plot_modelに“feature”を渡すと、Feature Importanceのグラフを表示することができます。
[Google Colaboratory]
1
| plot_model(tuned_ridge, "feature")
|
[実行結果]
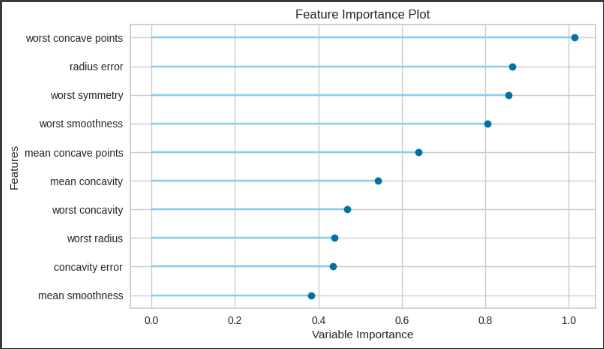
worst concave pointsが高いことが確認できます。
Confusion Matrix
plot_modelに“confusion_matrix”を渡すと、Confusion Matrixのグラフを表示することができます。
[Google Colaboratory]
1
| plot_model(tuned_ridge, plot = "confusion_matrix")
|
[実行結果]
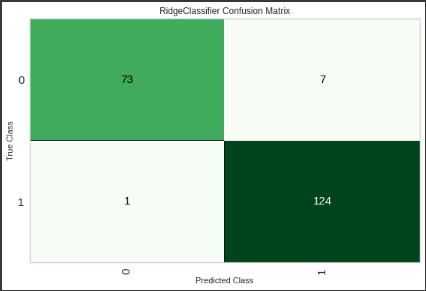
精度よく分類されていることが分かります。
Class Prediction Error Plot
plot_modelに“error”を渡すと、Class Prediction Error Plotのグラフを表示することができます。
[Google Colaboratory]
1
| plot_model(tuned_ridge, "error")
|
[実行結果]
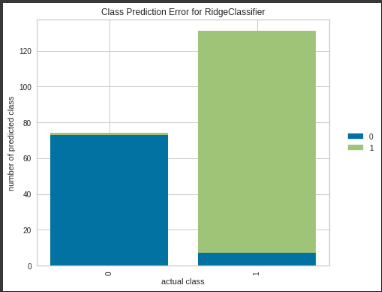
横軸にカテゴリが表示され、予測が積み上げ棒で表示されています。
モデルがどのカテゴリで問題を抱えているか、カテゴリごとにどのような不正解があるのかを確認できます。
異なるモデルの長所と短所、およびデータセットにおける特有の課題の発見に役立ちます。
モデルの確定と推論
モデルを確定させて推論を実施します。
推論には、モデル構築に使っていないUnseenデータ(残り10%)を使用します。(2行目)
[Google Colaboratory]
1
2
3
| final_ridge = finalize_model(tuned_ridge)
predictions = predict_model(final_ridge, data=tg_df_unseen)
print(predictions)
|
[実行結果(一部略)]
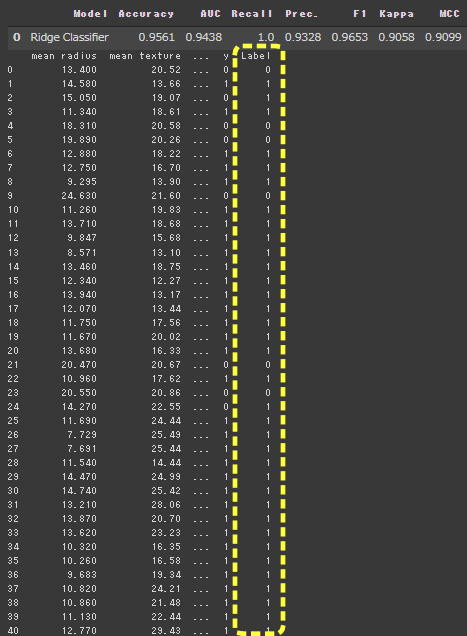
予測値がLabelとして追加されています。
確定したモデルは回帰モデルと同じように、ファイルに保存することができ、そのファイルを読み込むことでモデルの再利用が可能です。
以上が、PyCaretを使って分類モデルを構築して推論を行うフローになります。